 夜雨聆风
夜雨聆风





✨基于VeRL源码解读字节Seed的DAPO✨







网上关于DAPO的解读已经很多了,大多都是基于DAPO中使用的几个trick来展开讲解,本文除了解读trick外,更多的是基于VeRL源码来对各个trick进行拆解详细解析请左滑
持续更新大模型上下文长度扩展方法:PI、NTK和YaRN等
LeetCode整理(Hot 100 + 面试经典150题 + 各大厂高频面试题)
SFT全流程代码实现
面试常见手撕代码总结(GQA、LoRA、Norm、MLP、BeamSearch等)
大模型相关论文精读
上述资料提供代码bug答疑服务感兴趣的小伙伴可以点击下方链接查看
#大模型算法岗 #暑期实习 #秋招 #春招面试 #大厂算法岗 #rlhf强化学习 #代码复现 #字节seed #火山引擎 #verl
💡背景痛点
大语言模型(如ChatGPT)的强化学习训练一直依赖PPO/GRPO算法,但这些方法在复杂推理任务中暴露致命缺陷:
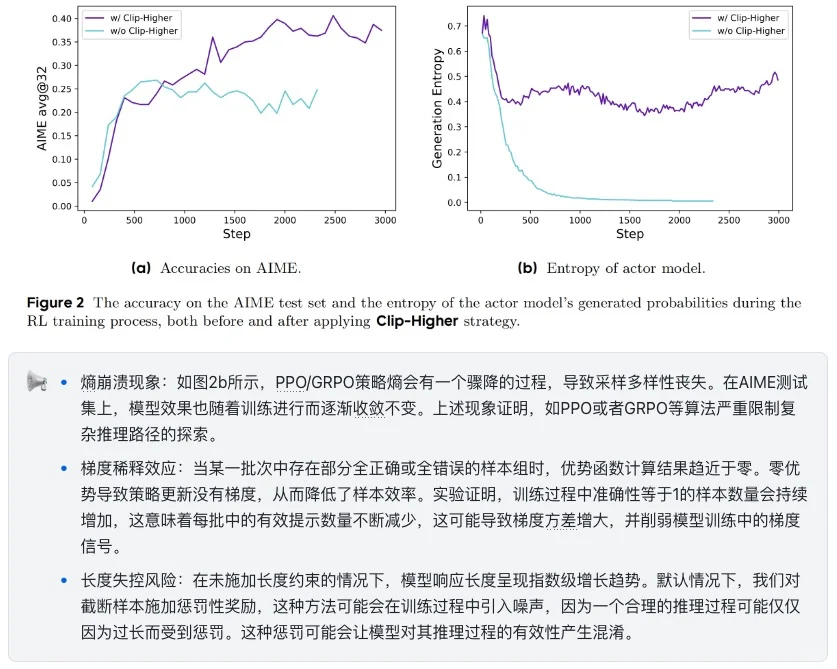
🔸 探索受限:低概率答案被过度压制,导致策略快速收敛且回答趋于一致,造成熵坍缩现象
🔸 零优势效应:随着训练进行,某些组内优势趋于0,削弱了模型训练中的梯度信号
🔸 长度惩罚:现有的直接截断或者惩罚策略会引入奖励噪声
🚀DAPO的三大创新 :
1️⃣ 智能调整学习步幅
👉 不对称裁剪技术(Clip-Higher)
让低概率答案有更大提升空间(+28%探索自由度),打破思维固化,这个我感觉算是本文比较好的一个探索~
2️⃣ 动态过滤无效样本
👉 自动筛除全对/全错的「摆烂」数据
只保留能带来有效学习信号的优质样本,关于源码中的做法,具体可以参考图6
3️⃣ 长度惩罚机制
👉 用渐进式惩罚遏制长输出
定义了一个惩罚区间,在这个区间内长度越长收到的惩罚越大,这个感觉没有太惊艳
🌈实际效果
在奥数题测试集AIME 2024上:
✅ Qwen2.5-32B准确率从0逐步上升到50%
✅ 训练步数比主流方案节省50%
✨✨✨💥💥💥🔥🔥🔥
上述论文解读内容已同步更新至《大模型实战代码合集(持续更新)》和《大模型自学笔记整理(持续更新)》。
代码实战合集中包含以下几部分内容:
持续更新大模型上下文长度扩展方法:PI、NTK和YaRN等
LeetCode整理(Hot 100 + 面试经典150题 + 各大厂高频面试题)
SFT全流程代码实现
面试常见手撕代码总结(GQA、LoRA、Norm、MLP、BeamSearch等)
大模型相关论文精读
上述资料提供代码bug答疑服务感兴趣的小伙伴可以点击下方链接查看
#大模型算法岗 #暑期实习 #秋招 #春招面试 #大厂算法岗 #rlhf强化学习 #代码复现 #字节seed #火山引擎 #verl
