 夜雨聆风
夜雨聆风





大模型RLHF:PPO原理与源码解读




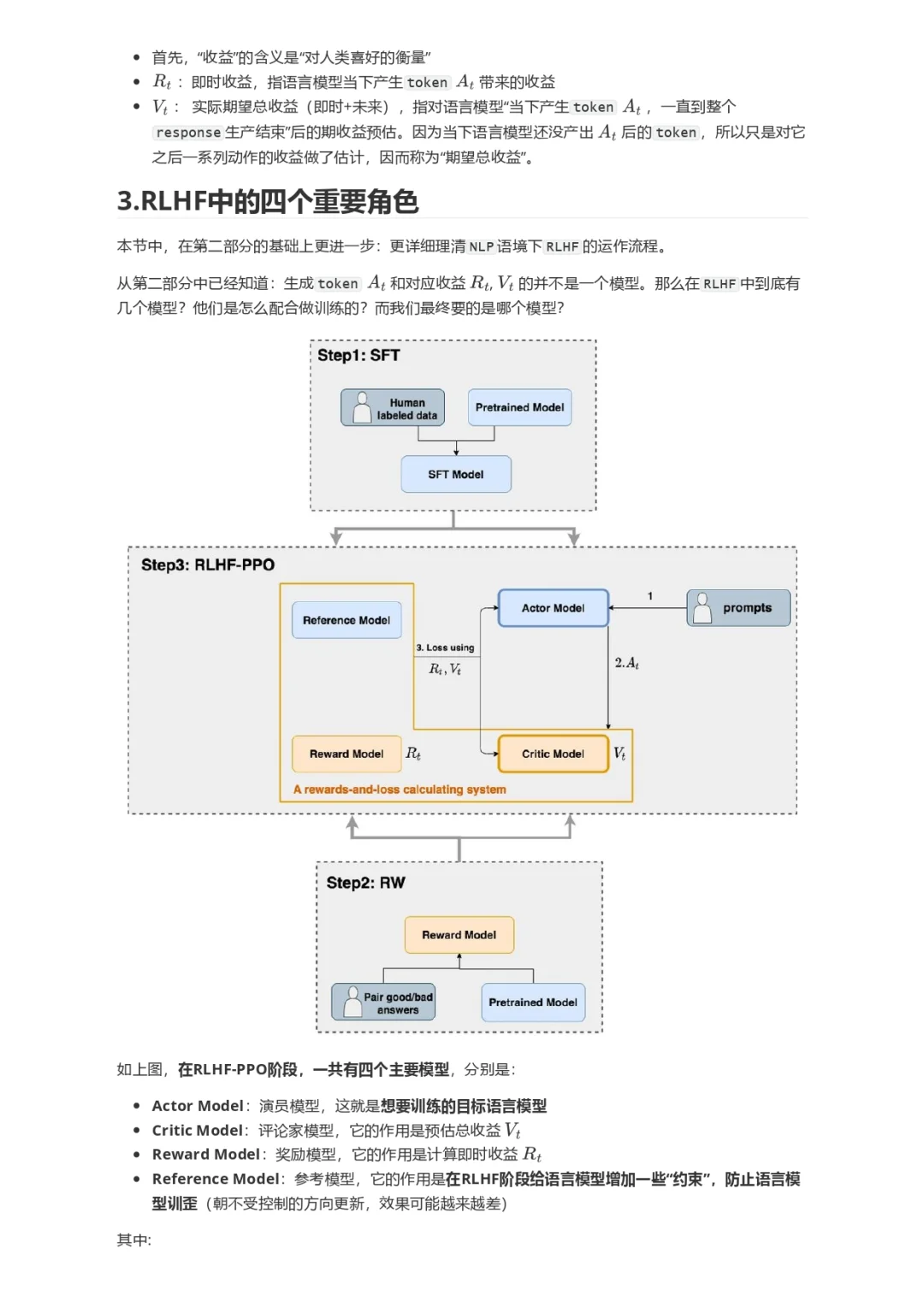
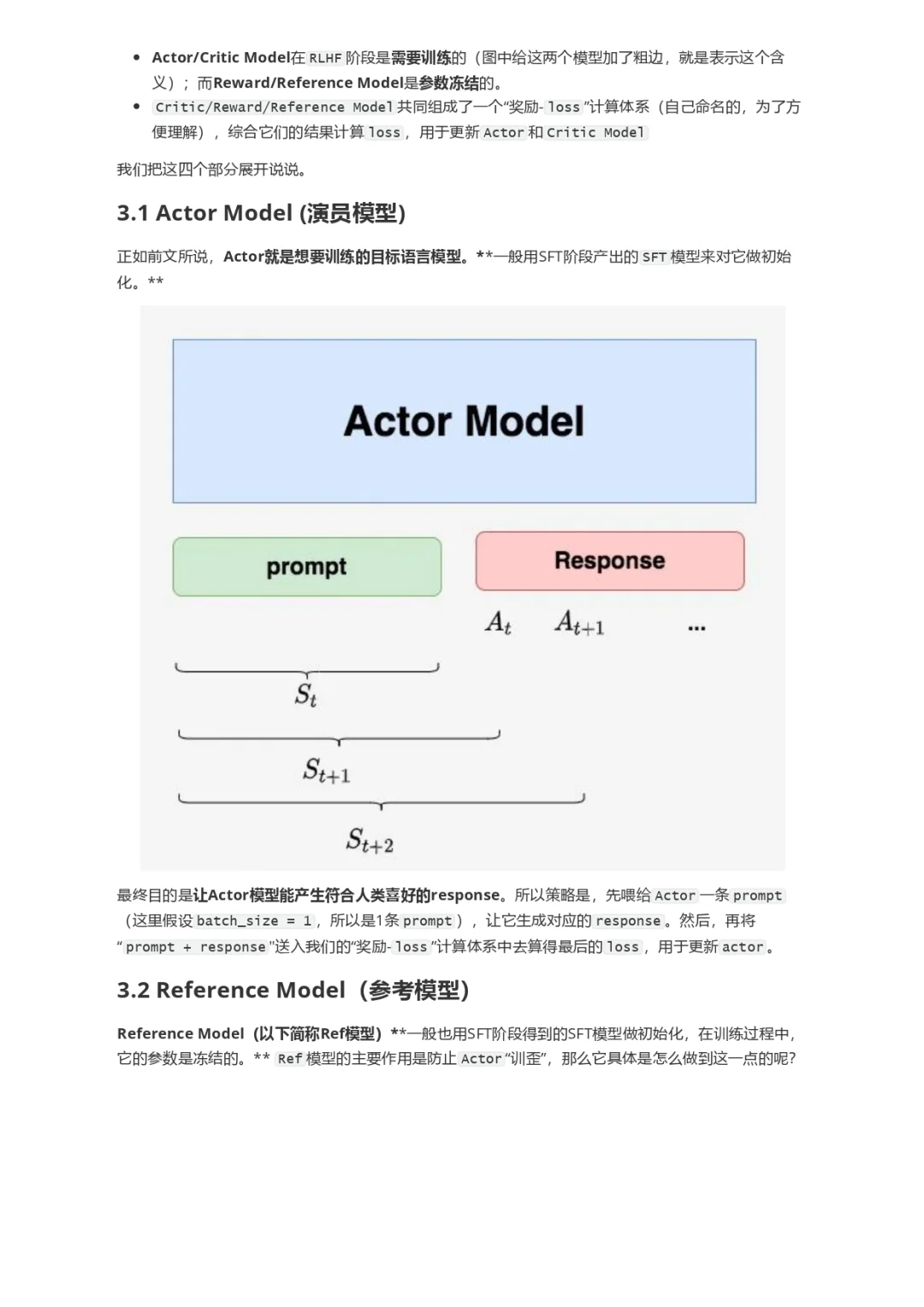

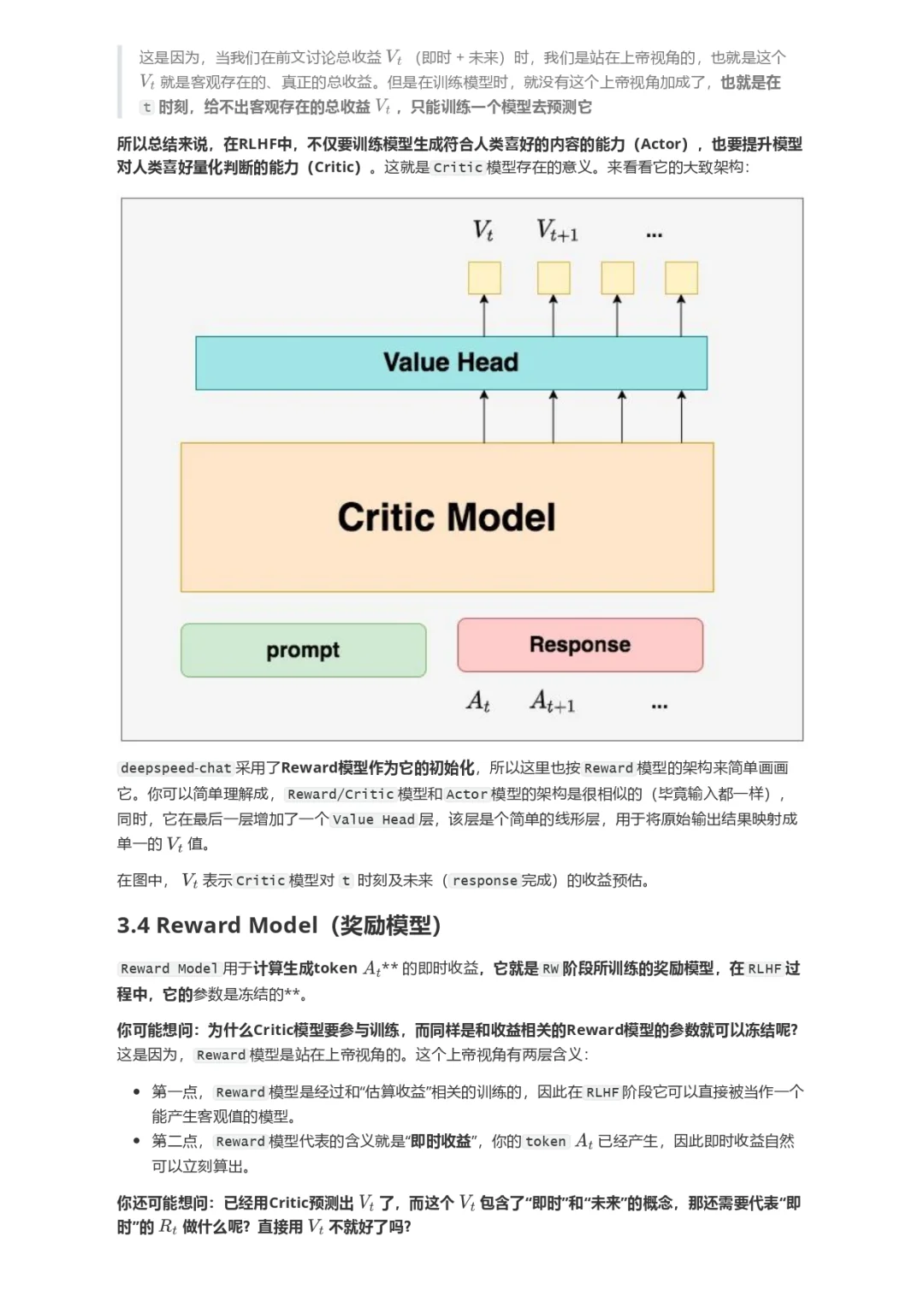
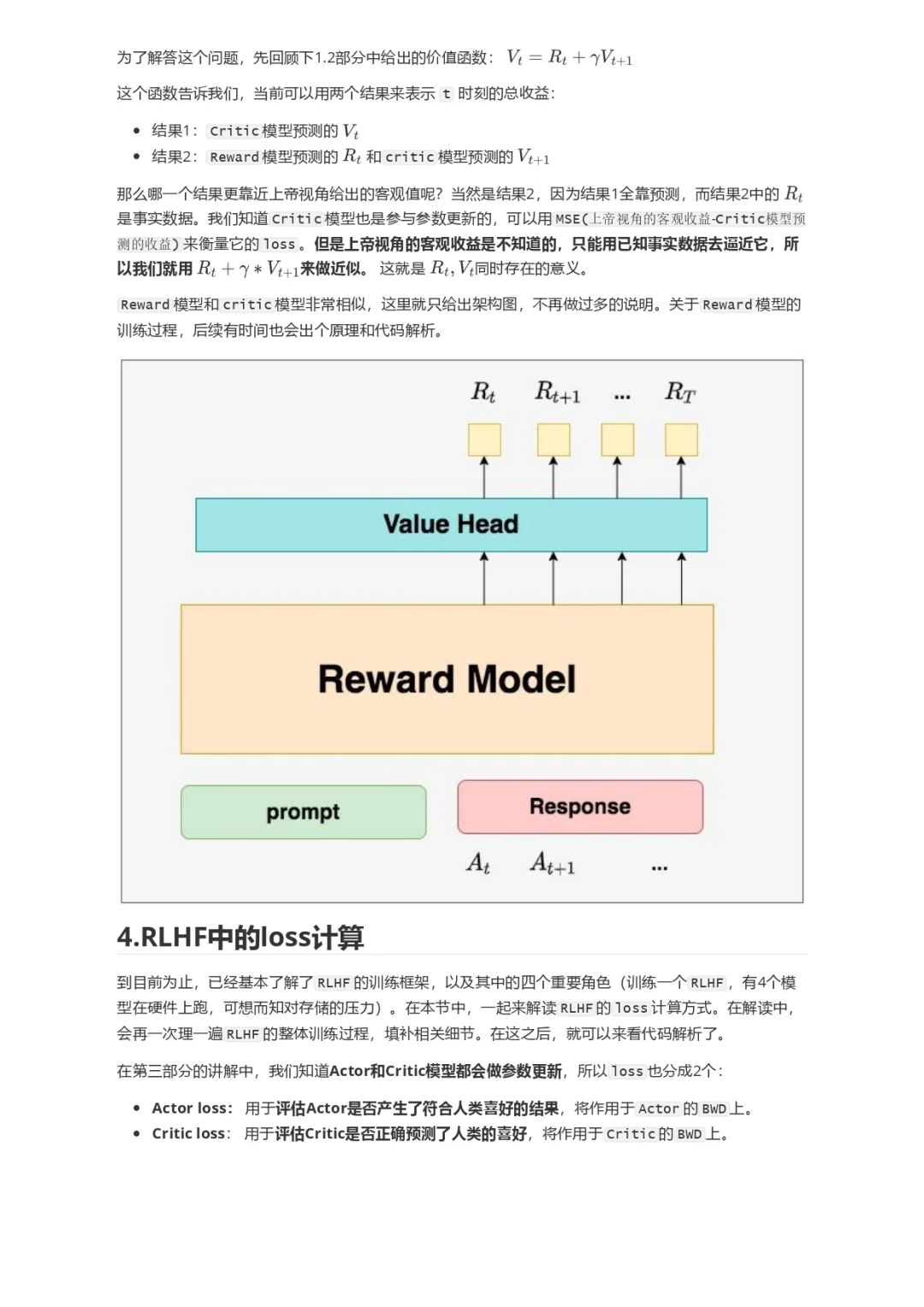








本文直接从一个RLHF开源项目源码入手(deepspeed-chat),根据源码的实现细节,给出尽可能丰富的训练流程图,并对所有的公式给出直观的解释。希望可以帮助大家更具象地感受RLHF的训练流程。关于RLHF,各家的开源代码间都会有一些差异,同时也不止PPO一种RLHF方式。
1.强化学习概述
1.1 强化学习整体流程
强化学习的两个实体:智能体(Agent)与环境(Environment)
强化学习中两个实体的交互:
状态空间S:S即为State,指环境中所有可能状态的集合
动作空间A:A即为Action,指智能体所有可能动作的集合
奖励R:R即为Reward,指智能体在环境的某一状态下所获得的奖励。
以上图为例,智能体与环境的交互过程如下:
在 t 时刻,环境的状态为 St,达到这一状态所获得的奖励为 Rt。
智能体观测到 St 与 Rt,采取相应动作 At
智能体采取 At后,环境状态变为St+1,得到相应的奖励Rt+1
智能体在这个过程中学习,它的最终目标是:找到一个策略,这个策略根据当前观测到的环境状态和奖励反馈,来选择最佳的动作。
1.2 价值函数
γ \\gammaγ :折扣因子。它决定了我们在多大程度上考虑将“未来收益”纳入“当下收益”。
注:在这里,不展开讨论RL中关于价值函数的一系列假设与推导,而是直接给出一个便于理解的简化结果,方便没有RL背景的朋友能倾注更多在“PPO策略具体怎么做”及“对PPO的直觉理解”上。
2.NLP中的强化学习
在第一部分介绍了通用强化学习的流程,那么要怎么把这个流程对应到NLP任务中呢?换句话说,NLP任务中的智能体、环境、状态、动作等等,都是指什么呢?
回想一下对NLP任务做强化学习(RLHF)的目的:希望给模型一个prompt,让模型能生成符合人类喜好的response。再回想一下GPT模型做推理的过程:每个时刻 t 只产生一个token,即token是一个一个蹦出来的,先有上一个token,再有下一个token。
#RAG #langchain #大模型 #前端面试题 #机器学习 #RLHF #算法 #PPO #DPO #强化学习