 夜雨聆风
夜雨聆风





「笔记分享」强化学习PPO源码阅读

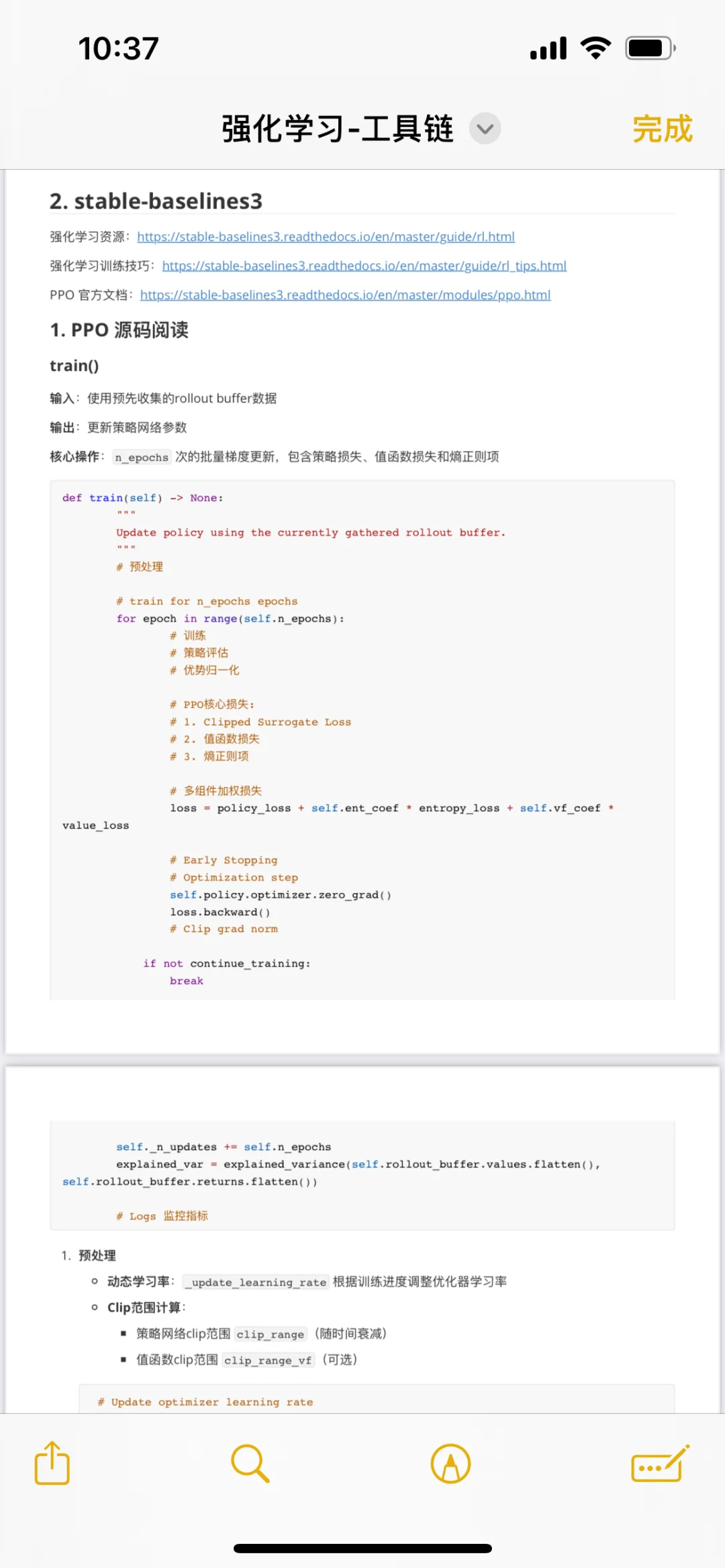




最近正在学习PPO算法,欢迎同方向的uu与我一起讨论学习!源码来源于pytorch stable-baselines3
PPO(Proximal Policy Optimization)算法的核心在于其通过Clipping机制在策略更新的稳定性和效率之间取得了平衡。它创新性地引入策略更新幅度的硬性约束,通过限制新旧策略的差异避免过大的梯度更新,从而防止训练崩溃;同时,结合重要性采样技术,支持对同一批数据多次复用并优化策略,显著提升了样本效率。
相较于TRPO等复杂方法,PPO省去了二阶导数计算和繁琐的约束优化,仅需一阶近似即可实现稳定训练,大幅降低了实现难度。此外,PPO对超参数相对鲁棒,在连续控制、游戏决策等多种任务中展现了优异的通用性和可扩展性,成为深度强化学习领域应用最广泛的基准算法之一。
更多 RL 学习笔记可见我的博客:dearaj.github.io。部分内容来源于网络,侵权删。也欢迎加入下方 RL 交流群。
#强化学习 #PPO #算法 #科研学习 #计算机 #人工智能