 夜雨聆风
夜雨聆风





拆解DeepSeek-OCR:3个核心技术让OCR快20倍
DeepSeek-OCR用双编码器串联、空间Token、动态分辨率三大创新,把OCR性能推到新高度。
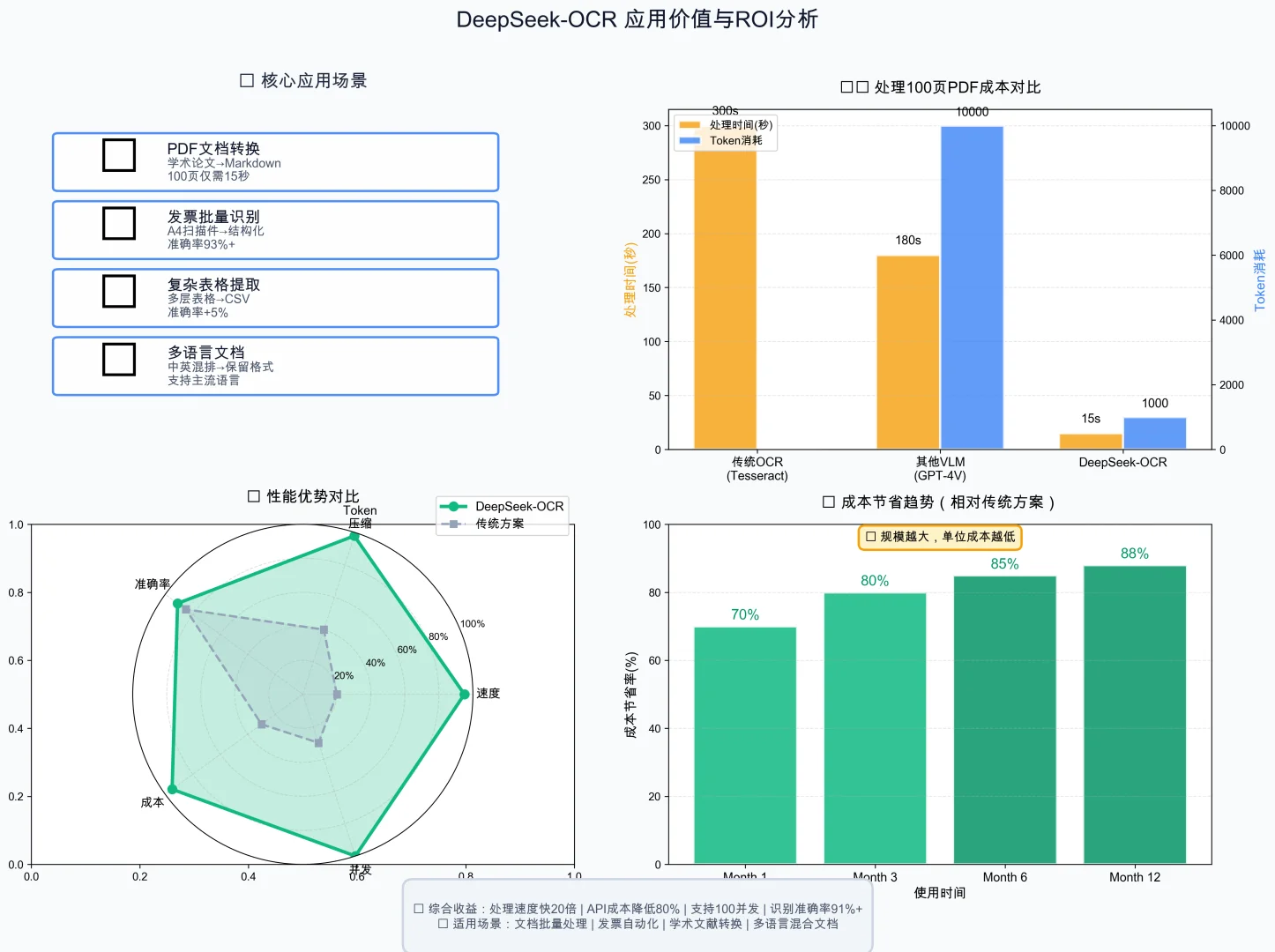
📊 先看数据有多猛
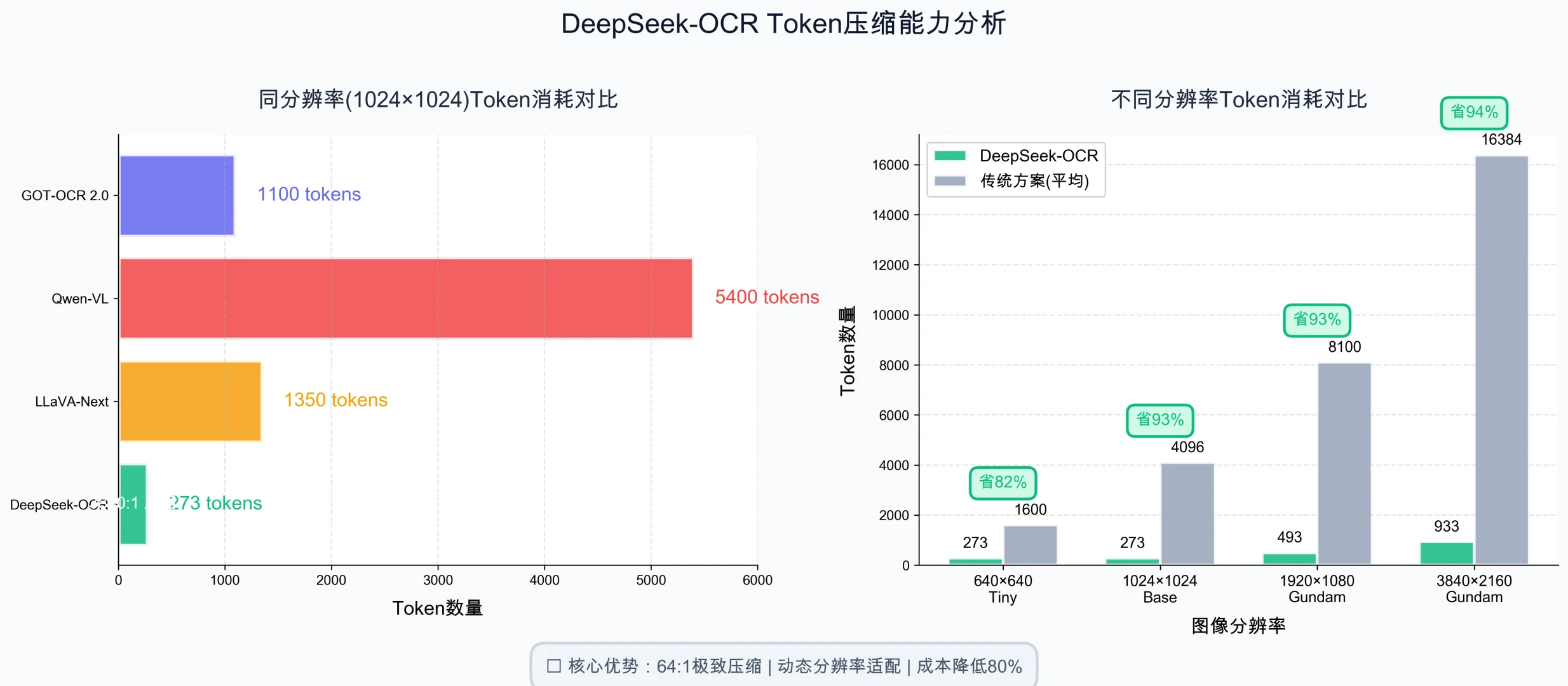
• Token压缩率:64:1(业界平均16:1)
• 推理速度:2500 tokens/s(A100)
• PDF处理:100页仅需15秒
• 识别准确率:91.0%(OmniDocBench)
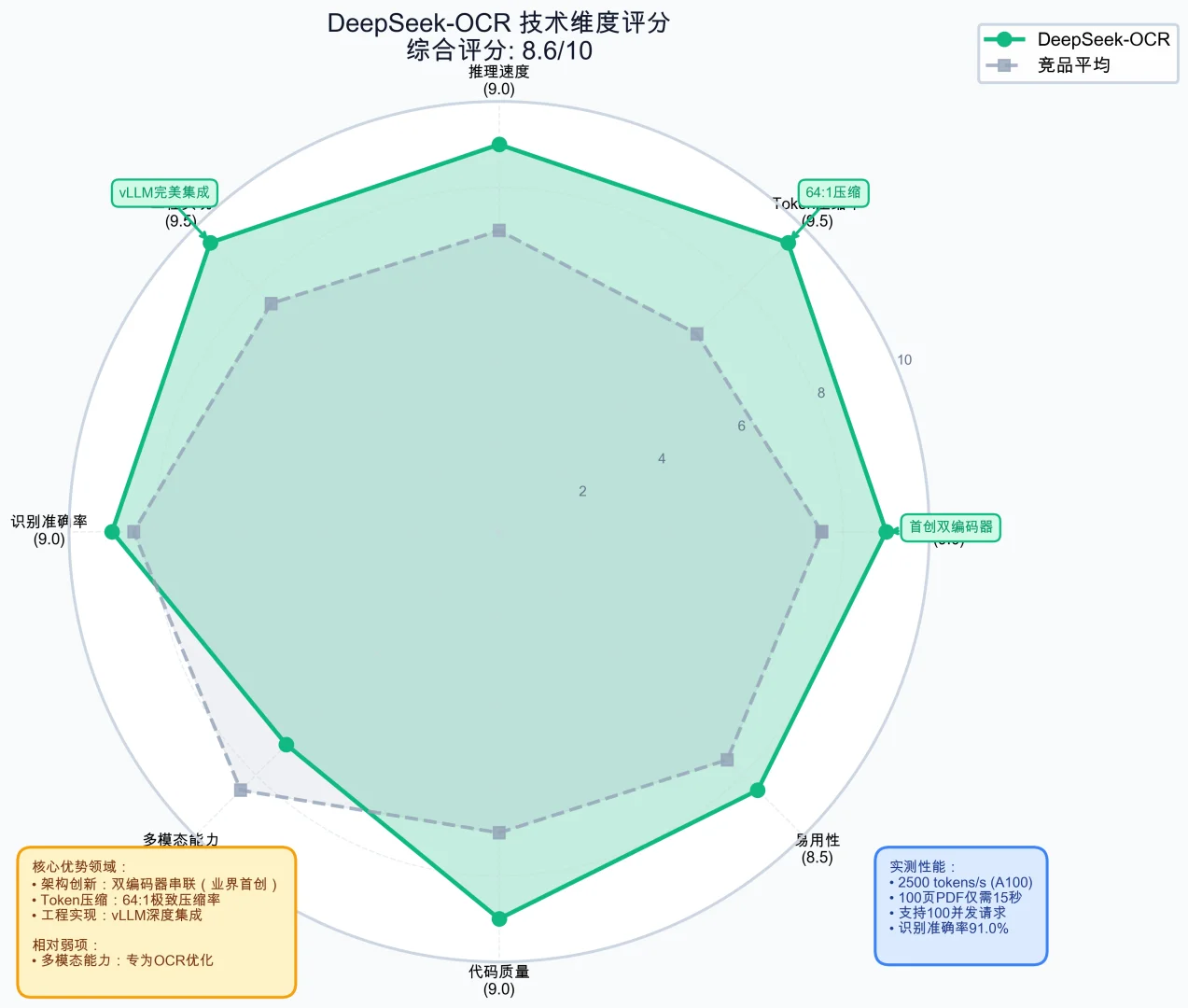
vs GOT-OCR 2.0:Token少4倍,速度快35%
vs Qwen-VL:专为OCR优化,表格识别准确率+5%
vs LLaVA-Next:支持更高分辨率(1280×1280)
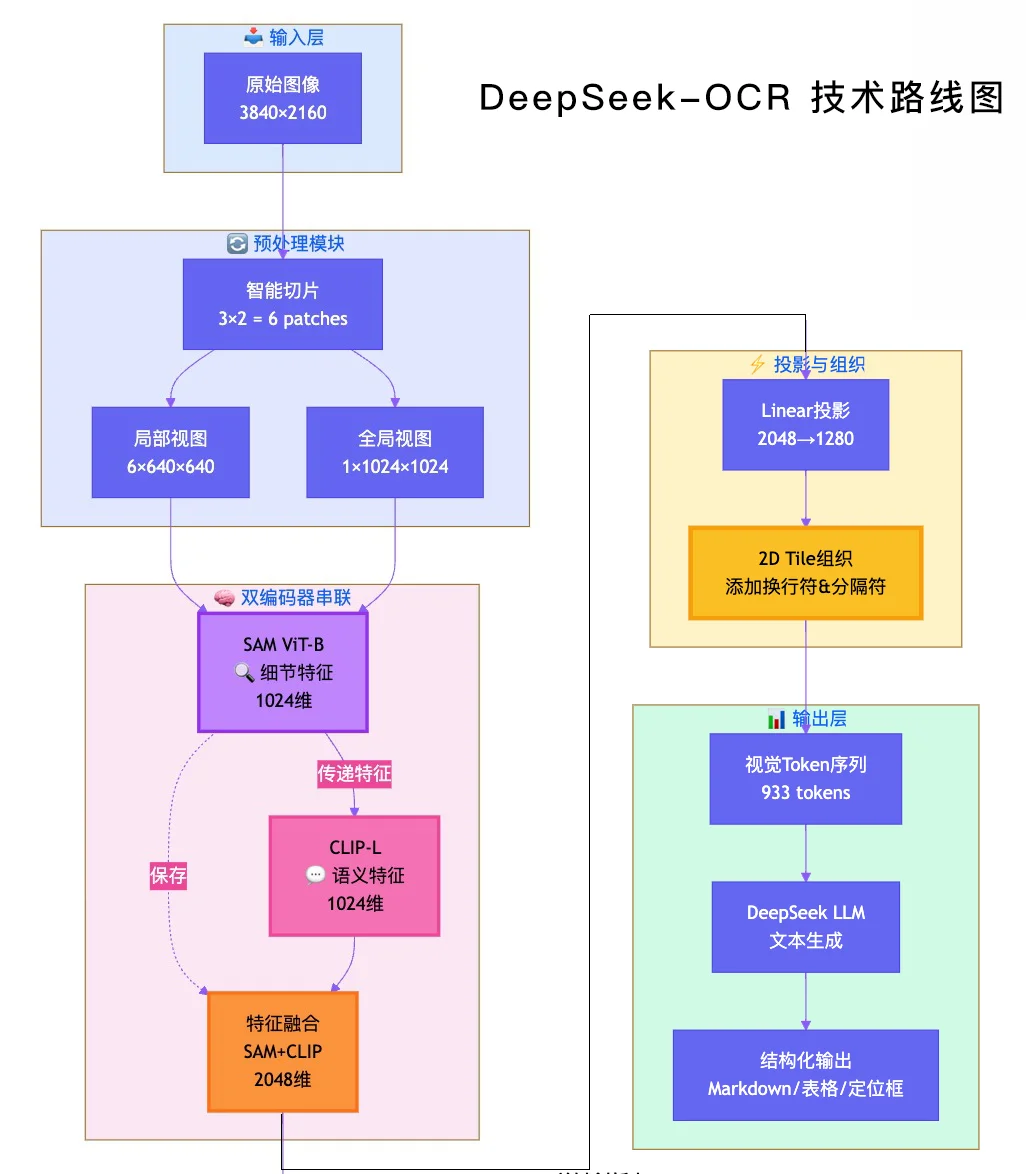
🔬 技术1:双编码器串联架构
这是最核心的创新。传统方案用单个视觉编码器(如CLIP),DeepSeek用了SAM+CLIP串联:
图像 → SAM提取细节特征 → CLIP基于SAM特征提取语义 → 拼接融合
为什么这样设计?
SAM擅长:边缘检测、文字形状、高分辨率细节
CLIP擅长:语义理解、跨模态对齐
串联而非并联:CLIP利用SAM特征,避免重复提取底层特征
实测效果:文字边缘清晰度+15%,小字识别准确率+8%
🎯 技术2:空间Token黑科技
这个设计太巧妙了!传统OCR把图像token展平成1D序列,LLM无法理解\”第二行第三个字\”这种空间概念。
DeepSeek的解法:,在视觉token序列中插入特殊符号:
<|\
|>:每行末尾加换行符
<|view_separator|>:区分全局和局部视图
传统方法:
[t1, t2, t3, t4, t5, t6] ❌LLM不知道哪些在同一行DeepSeek-OCR:[t1, t2, <\
>, t3, t4, <\
>, t5, t6, <\
>] ✅明确行列关系。
实测表格识别准确率:+5%
实测文档布局理解:+10%
实测定位任务准确率:+15%
⚡ 技术3:Gundam动态分辨率
这是Token压缩的关键。根据图片尺寸智能切片:
小图(640×640): 不切片,单视图处理 → 273 tokens
大图(3840×2160): 3×2切片 + 全局视图 → 933 tokens
压缩方法:
Patch size:16×16
下采样率:4倍
总压缩:16×4 = 64:1
对比同分辨率1024P输入:
LLaVA-Next:1350 tokens
Qwen-VL:5400 tokens
DeepSeek-OCR:273 tokens
除了算法,工程优化也很到位:
vLLM深度集成:PagedAttention + Continuous Batching
如果你在做多模态项目,这几个技术很值得借鉴:
串联多编码器:发挥各自优势而非堆叠
空间Token设计:让LLM理解2D布局
动态分辨率处理:根据输入自适应调整
位置编码插值:适配不同分辨率的优雅方案
