 夜雨聆风
夜雨聆风





深入解析自动抓取文章源码:基础理论、技术途径与实践应用
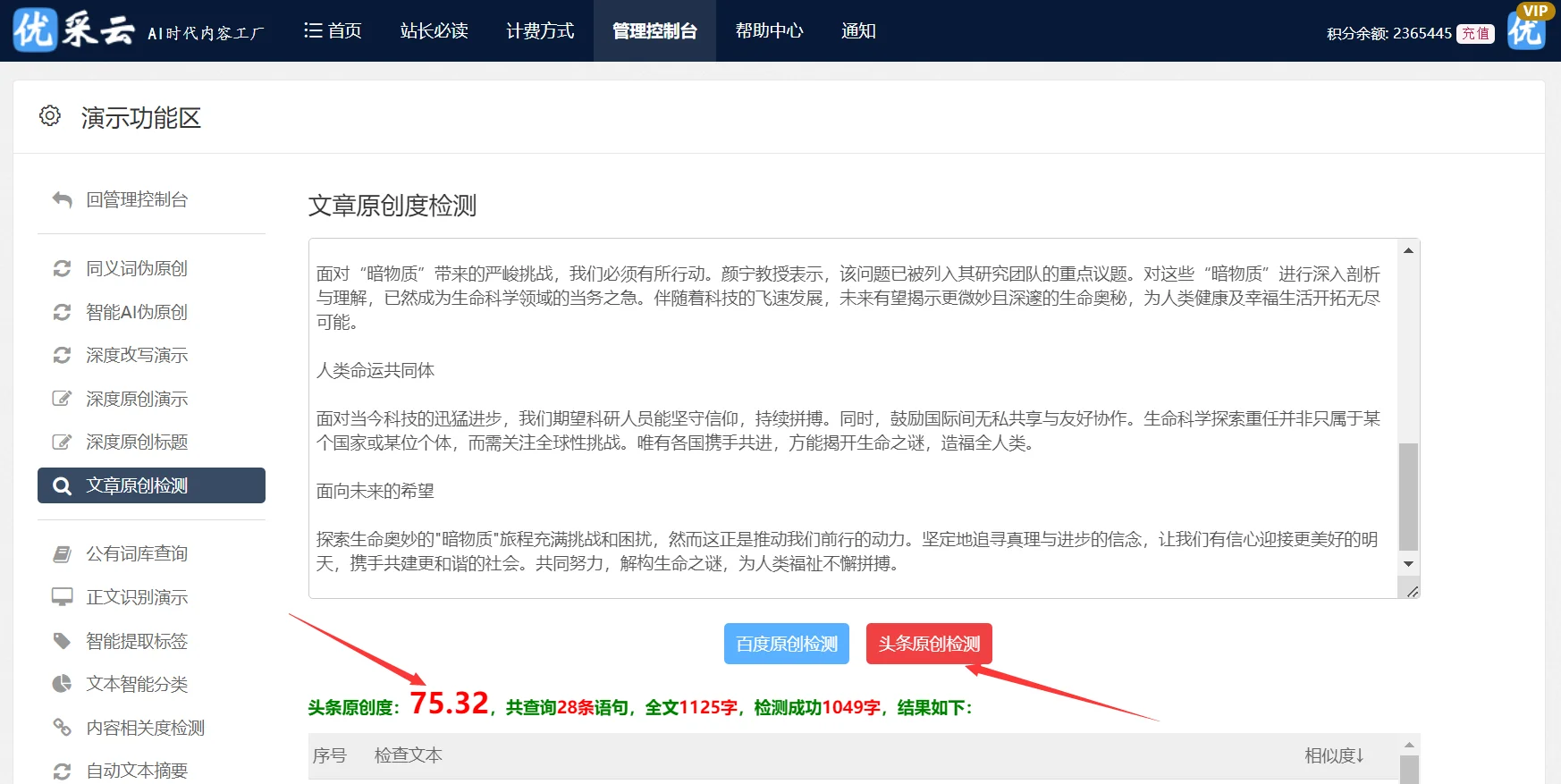

在当前信息泛滥的环境中,掌握自动抓取文章源码成为了内容制作者与网站运维的必备技能。此技术不仅能显著提升效率,亦确保了资讯的时效性与精确度。本文将围绕基础理论、技术途径及实践应用三个维度,对文章自动抓取源码的相关知识进行深入解析。
基本概念
自动提取文章源码涉及编写专用于从网络抓取所需内容的程序。此过程主要仰仗网络爬虫技术,该技术可模仿用户浏览网页的行为,自动导航并搜集网页信息。高效提取目标数据是该技术的关键,它要求对HTML结构和网页内容有透彻的了解。
数据清洗为自动采集的关键环节之一,它旨在剔除原始数据中的噪音,包括广告和无关信息。通过应用算法与规则,确保有价值信息的留存。数据清洗的整体质量将显著影响数据分析和应用的效果。
技术实现
自动获取文章源码一般需熟练运用特定编程语言及工具。Python因其庞大的库资源(如BeautifulSoup和Scrapy)而广受欢迎,便于网页数据的解析与提取。JavaScript与Node.js亦为优秀选择,尤其在应对动态网页内容方面表现突出。
编写采集软件时,应严格遵循网站的robots.txt规定及法律法规,以防对网站造成超额负担或侵权。恰当调整采集速率与深度,可显著减轻服务器负荷并提升采集效果。
应用场景
自动采集源码在不同领域应用广泛。新闻网站依赖其实时更新国内外新闻;电商平台通过其获取对手价格和产品信息;学术研究人员借助其采集的大量文献数据进行研究和分析。
自动抓取技术亦适用于网络舆论监测。企业通过搜集社交平台及论坛中的用户评价与对话,迅速掌握公众对自身产品和服务的反馈,进而实施相应的优化措施。
您认为自动提取代码在何种情境中效能最为显著?敬请于评论区交流您的观点,并对文章点赞与转发,以推广这一实用的技术知识。
基本概念
自动提取文章源码涉及编写专用于从网络抓取所需内容的程序。此过程主要仰仗网络爬虫技术,该技术可模仿用户浏览网页的行为,自动导航并搜集网页信息。高效提取目标数据是该技术的关键,它要求对HTML结构和网页内容有透彻的了解。
数据清洗为自动采集的关键环节之一,它旨在剔除原始数据中的噪音,包括广告和无关信息。通过应用算法与规则,确保有价值信息的留存。数据清洗的整体质量将显著影响数据分析和应用的效果。
技术实现
自动获取文章源码一般需熟练运用特定编程语言及工具。Python因其庞大的库资源(如BeautifulSoup和Scrapy)而广受欢迎,便于网页数据的解析与提取。JavaScript与Node.js亦为优秀选择,尤其在应对动态网页内容方面表现突出。
编写采集软件时,应严格遵循网站的robots.txt规定及法律法规,以防对网站造成超额负担或侵权。恰当调整采集速率与深度,可显著减轻服务器负荷并提升采集效果。
应用场景
自动采集源码在不同领域应用广泛。新闻网站依赖其实时更新国内外新闻;电商平台通过其获取对手价格和产品信息;学术研究人员借助其采集的大量文献数据进行研究和分析。
自动抓取技术亦适用于网络舆论监测。企业通过搜集社交平台及论坛中的用户评价与对话,迅速掌握公众对自身产品和服务的反馈,进而实施相应的优化措施。
您认为自动提取代码在何种情境中效能最为显著?敬请于评论区交流您的观点,并对文章点赞与转发,以推广这一实用的技术知识。
