 夜雨聆风
夜雨聆风





从C源码到Hex文件——Keil编译过程的深度解析
1. 编译流程全景图与体系架构
1.1 编译工具链整体架构
在深入分析编译过程的每个环节之前,我们先从宏观角度了解Keil MDK工具链的整体架构。下图展示了从源代码到最终Hex文件的完整处理流程,涵盖了所有参与的工具和它们之间的数据流关系:
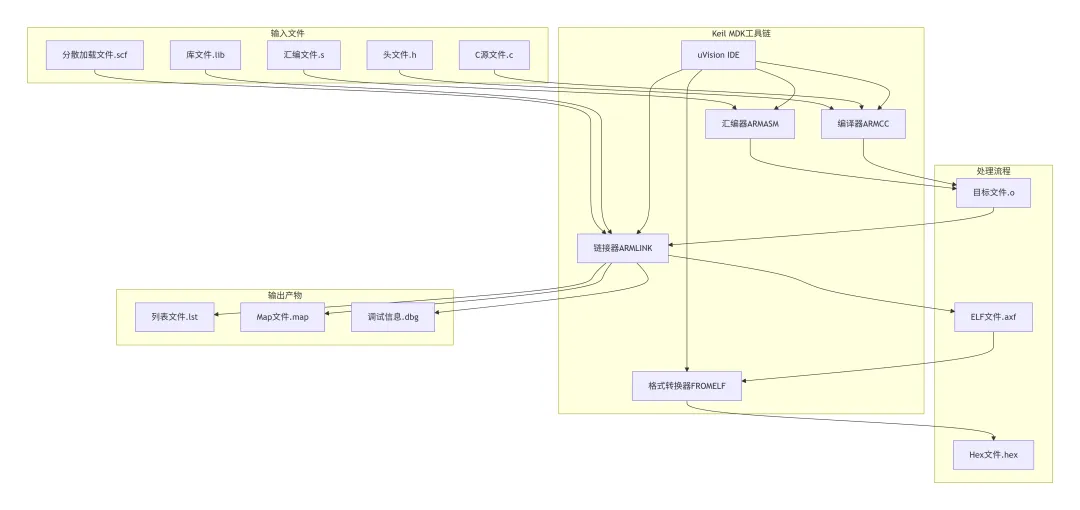
架构解析:Keil MDK采用典型的工具链架构,每个组件负责特定的转换任务。uVision IDE作为集成开发环境,协调各个工具的执行顺序和数据传递。ARMCC编译器将C源代码转换为汇编代码,ARMASM处理汇编源文件,ARMLINK负责链接所有目标文件,FROMELF则将可执行文件转换为可烧录的Hex格式。这种模块化设计允许每个组件独立优化,同时保证整个流程的高效执行。
1.2 编译过程数据流
为了更清晰地理解各个工具如何协同工作,下图展示了编译过程中数据的流动顺序和每个阶段的输入输出关系:
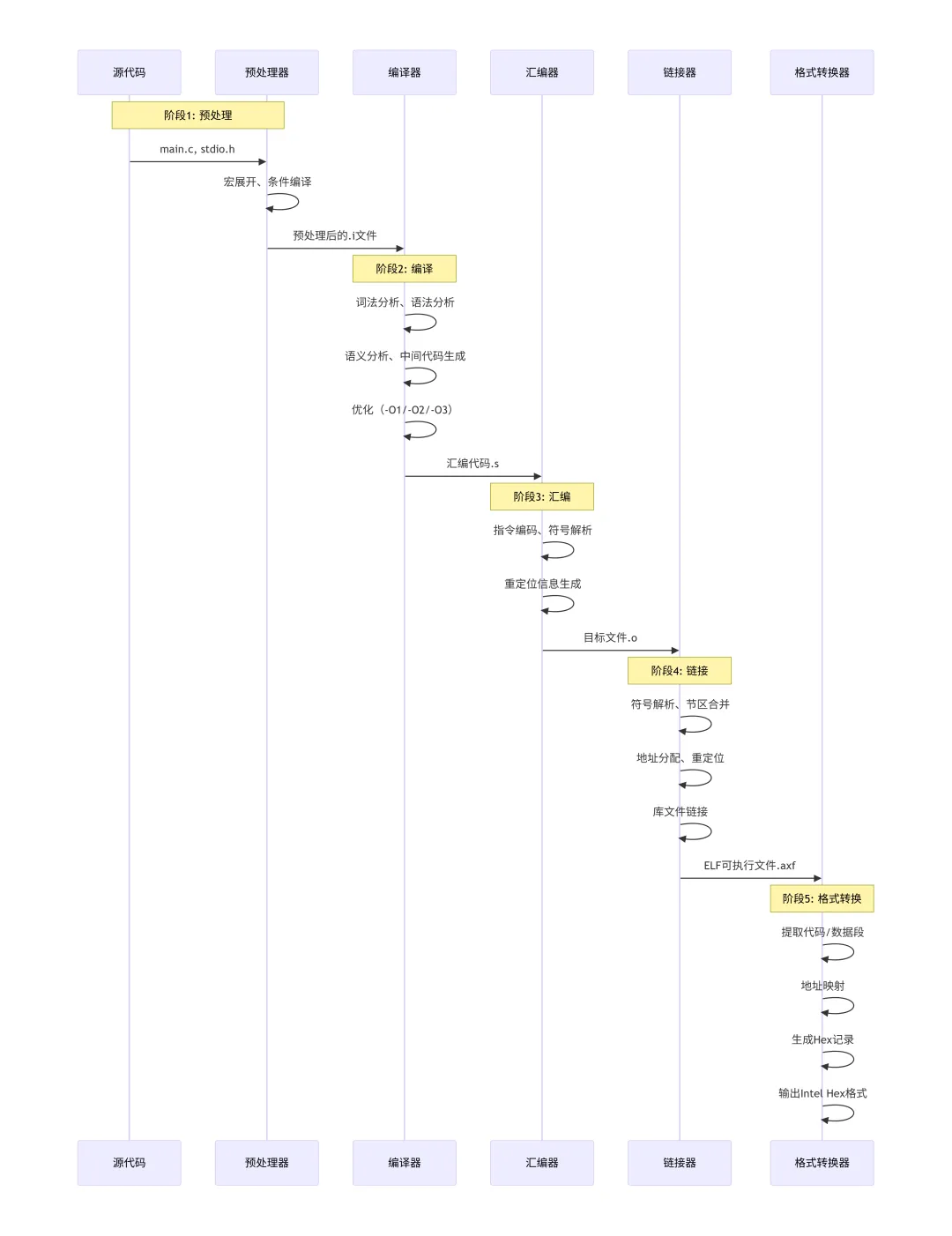
数据流解析:这是一个典型的顺序处理流水线,每个阶段的输出作为下一阶段的输入。预处理阶段处理宏和条件编译指令;编译阶段进行语法语义分析并生成汇编代码;汇编阶段将汇编指令编码为机器码;链接阶段解决符号引用并分配内存地址;最后格式转换阶段生成适合烧录的Hex文件。每个阶段都可以独立调试和优化,这种设计提高了工具链的灵活性和可维护性。
2. 预处理器:宏展开与条件编译
2.1 预处理状态机原理
预处理器是编译过程的第一步,它处理源代码中的预处理指令。下图展示了预处理器如何通过状态机模型识别和处理不同类型的预处理指令:
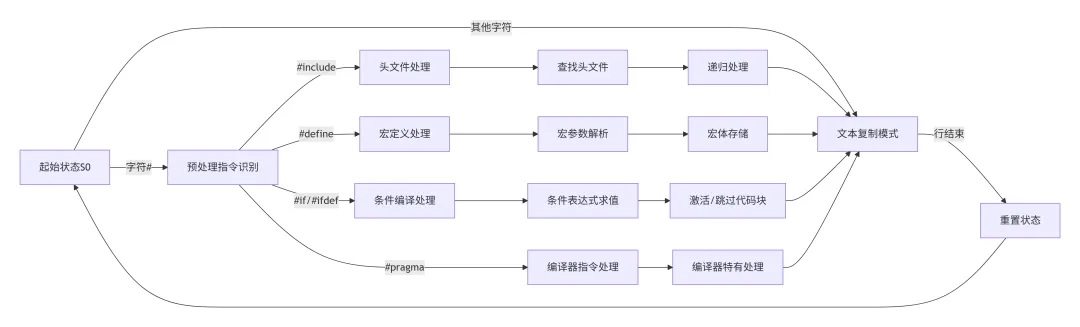
状态机解析:预处理器使用有限状态机来识别和处理不同的预处理指令。起始状态S0检测字符流,当遇到’#’字符时进入指令识别状态。根据后续字符识别指令类型,然后进入相应的处理状态。处理完成后返回文本复制模式,将处理后的内容输出到预处理文件中。这种状态机设计使得预处理器能够高效地处理复杂的嵌套指令。
2.2 预处理关键技术分析
预处理器的核心算法是宏展开,下面的代码展示了宏展开的递归下降算法实现:
// 宏展开的递归下降算法TokenStream expand_macro(MacroDef *macro, TokenStream args) {TokenStream result = create_token_stream();for (each token in macro->body) {if (token.type == MACRO_PARAM) {// 参数替换int param_index = token.param_index;TokenStream arg_expanded = expand_tokens(args[param_index]);result = concatenate(result, arg_expanded);} else if (token.type == STRINGIFY || token.type == CONCAT) {// 特殊操作符处理handle_special_operator(token, args, &result);} else if (is_macro_name(token)) {// 嵌套宏展开(防止无限递归)if (!is_recursive_call(macro, token)) {MacroDef *nested = find_macro(token.text);TokenStream nested_result = expand_macro(nested, empty_args);result = concatenate(result, nested_result);}} else {// 普通token直接复制append_token(result, token);}}return result;}
算法解析:这段代码展示了宏展开的核心逻辑。算法遍历宏定义体中的每个token,根据token类型采取不同的处理策略:参数token被替换为实际参数值;特殊操作符如#和##进行字符串化或连接操作;遇到其他宏名时递归展开,但要检测并防止无限递归。这种递归下降算法保证了宏展开的正确性和完整性。
条件编译是预处理器的另一个重要功能,下面的数据结构管理条件编译的状态:
// 条件编译状态栈typedef struct {int stack[32]; // 0=不激活,1=激活,-1=未决int if_level; // 当前嵌套层数bool else_allowed[32]; // 是否允许else分支bool active_branch[32]; // 当前分支是否激活} ConditionalStack;// ARM编译器条件编译处理boolevaluate_condition(Preprocessor *pp, TokenStream cond){// ARMCC扩展:支持目标架构特定条件if (is_arm_feature_test(cond)) {return check_arm_feature(cond);}// 标准C条件表达式求值// 注意:预处理期间只能使用整数常量表达式return eval_constant_expression(cond);}
数据结构解析:ConditionalStack结构体管理条件编译的嵌套状态。stack数组记录每层条件编译的激活状态,if_level跟踪当前嵌套深度,else_allowed标记是否允许else分支,active_branch记录当前分支是否激活。这种栈式设计完美支持了条件编译的任意深度嵌套。
2.3 ARMCC预处理特性
ARMCC编译器提供了一些特有的预处理指令,用于优化Cortex-M3代码生成:
#pragmapack(push, 1) // 字节对齐,节省内存#pragmapack(pop)#pragmadiag_suppress=Pe177 // 抑制未使用函数警告#pragmadiag_suppress=Pe550 // 抑制未使用变量警告#pragmaoptimize_for_size // 针对Flash大小优化#pragmaoptimize_for_speed // 针对执行速度优化#pragmaOspace // 优化空间(Flash)#pragmaOtime // 优化时间(执行速度)
ARMCC扩展解析:这些pragma指令允许开发者精细控制编译过程。#pack指令控制结构体对齐方式,在内存受限的Cortex-M3系统中特别有用;diag_suppress抑制特定警告,保持代码整洁;optimize指令指定优化方向,针对不同的应用场景优化代码大小或执行速度。
ARMCC还自动定义了一系列宏,帮助开发者编写可移植代码:
// ARMCC自动定义的宏#define__ARMCC_VERSION (ARM编译器版本)#define__TARGET_ARCH_ARM 7#define__TARGET_ARCH_THUMB 2#define__CORTEX_M3 // Cortex-M3特定#define__THUMB__ // Thumb模式#define__ARM_EABI__ // EABI规范// 使用示例#ifdef__CORTEX_M3// Cortex-M3特定代码#defineNVIC_PRIORITY_GROUPING NVIC_PriorityGroup_4#endif
预定义宏解析:这些自动定义的宏提供了编译时环境信息。开发者可以根据__CORTEX_M3宏编写特定于Cortex-M3的代码;__THUMB__宏表明编译器处于Thumb模式;__ARM_EABI__表示遵循ARM嵌入式应用二进制接口规范。这些宏提高了代码的可移植性和可读性。
3. 编译器:从C语言到汇编语言
3.1 编译器前端架构
编译器前端负责将预处理后的C代码转换为中间表示。下图展示了编译器前端的完整处理流程:
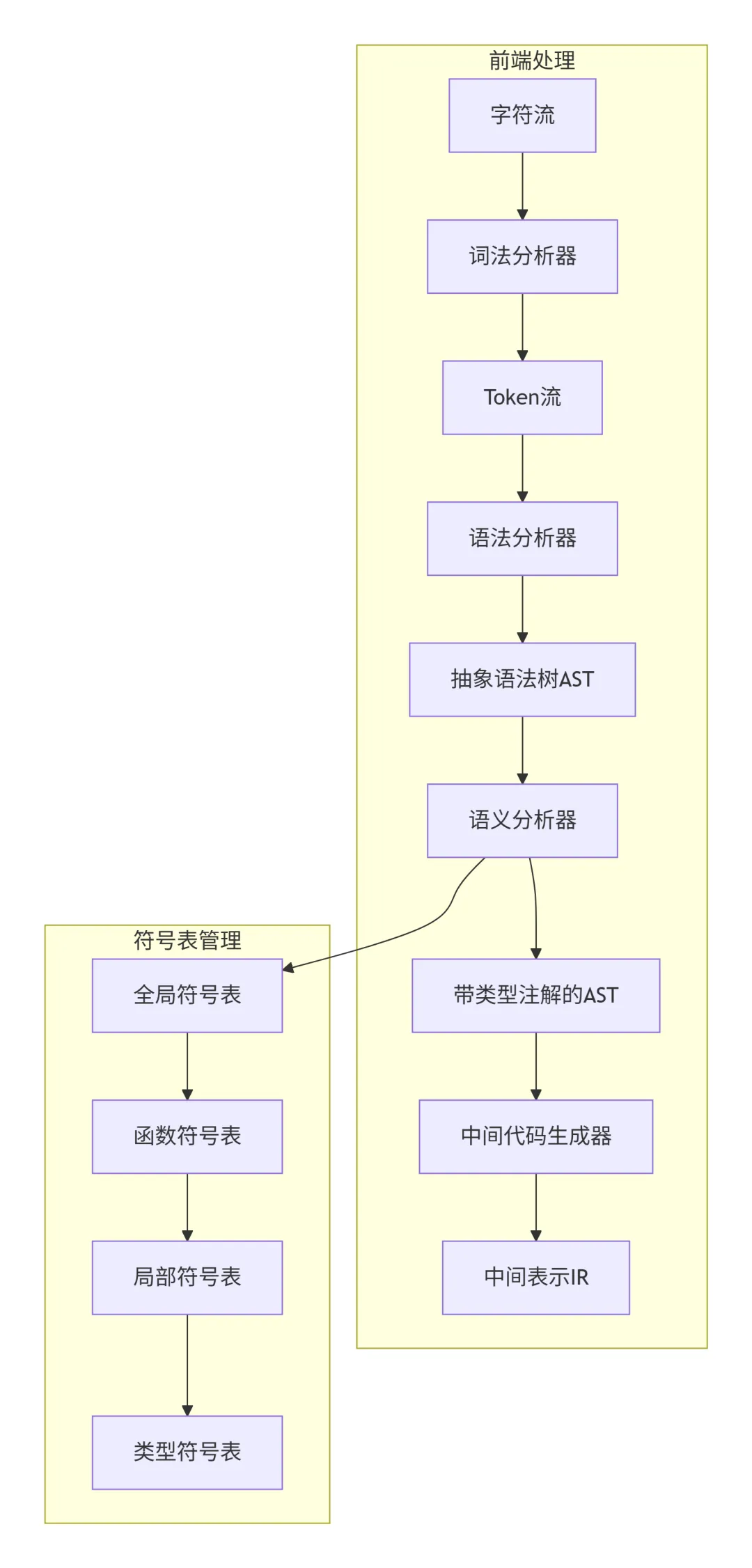
前端架构解析:编译器前端采用经典的流水线架构。字符流经过词法分析器转换为token流,语法分析器根据C语言文法构建抽象语法树,语义分析器进行类型检查和符号解析,最后中间代码生成器将AST转换为与机器无关的中间表示。符号表系统贯穿整个前端过程,管理变量、函数和类型的符号信息。
3.2 词法分析:从字符到Token
词法分析器使用确定性有限自动机(DFA)识别源代码中的各种词法单元。下面的状态转换表展示了词法分析的核心逻辑:
// ARMCC词法分析状态定义enum LexerState {LS_START, // 起始状态LS_IDENTIFIER, // 标识符LS_NUMBER, // 数字LS_HEX_NUMBER, // 十六进制数LS_FLOAT, // 浮点数LS_STRING, // 字符串LS_CHAR, // 字符常量LS_COMMENT, // 注释LS_LINE_COMMENT, // 行注释LS_PREPROCESSOR, // 预处理指令LS_OPERATOR, // 操作符LS_WHITESPACE // 空白字符};// 状态转移表示例(简化)int state_transition[LS_COUNT][256] = {// LS_START状态[LS_START]['a'-'z'] = LS_IDENTIFIER,[LS_START]['A'-'Z'] = LS_IDENTIFIER,[LS_START]['_'] = LS_IDENTIFIER,[LS_START]['0'-'9'] = LS_NUMBER,[LS_START]['"'] = LS_STRING,[LS_START]['\''] = LS_CHAR,[LS_START]['/'] = LS_COMMENT,[LS_START]['#'] = LS_PREPROCESSOR,[LS_START]['+'] = LS_OPERATOR,[LS_START]['-'] = LS_OPERATOR,// ... 其他转移};
状态机解析:这个状态转换矩阵定义了词法分析器的行为。对于每个当前状态和输入字符,矩阵指定下一个状态。例如,在起始状态遇到字母时进入标识符状态,遇到数字时进入数字状态,遇到引号时进入字符串状态。这种表驱动的方法使得词法分析器高效且易于维护。
3.3 语法分析:构建抽象语法树
语法分析器使用递归下降算法解析C语言的各种语法结构。下面的代码展示了表达式解析的核心逻辑:
// 表达式解析(运算符优先级处理)ASTNode* parse_expression(Parser* p, int min_precedence){ASTNode* lhs = parse_primary(p);while (1) {Token op = peek_token(p);int precedence = get_op_precedence(op);if (precedence < min_precedence) {break;}// 处理赋值操作符右结合性if (is_right_associative(op)) {precedence--;}next_token(p); // 消耗操作符ASTNode* rhs = parse_expression(p, precedence);lhs = create_binary_expr(op, lhs, rhs);}return lhs;}
递归下降解析解析:这段代码实现了运算符优先级解析算法,也称为普拉特解析器。算法首先解析基本表达式(变量、常量、括号表达式等),然后循环处理后续的操作符。对于每个操作符,如果其优先级高于当前最小优先级,则解析右操作数并构建二元表达式节点。这种方法自然地处理了操作符的优先级和结合性。
ARMCC支持一些GNU扩展语法,下面的代码展示了这些扩展语法的解析:
// Cortex-M3特殊语法扩展ASTNode* parse_arm_specific(Parser* p) {if (current_token_is(p, "__attribute__")) {// GNU扩展属性语法return parse_gnu_attribute(p);} else if (current_token_is(p, "__asm")) {// 内联汇编return parse_inline_asm(p);} else if (current_token_is(p, "__packed")) {// 压缩结构体return parse_packed_struct(p);}return NULL;}
语法扩展解析:这段代码处理ARMCC支持的GNU扩展语法。__attribute__用于指定变量或函数的特殊属性;__asm用于嵌入汇编代码;__packed用于定义无填充的结构体。这些扩展语法为Cortex-M3编程提供了更多的控制和优化机会。
3.4 语义分析:类型检查与符号解析
语义分析器为AST节点添加类型信息并进行各种语义检查。下面的类型系统定义展示了ARMCC如何表示C语言的各种类型:
// ARMCC类型表示typedef struct Type {enum {TYPE_VOID,TYPE_INT,TYPE_FLOAT,TYPE_POINTER,TYPE_ARRAY,TYPE_STRUCT,TYPE_UNION,TYPE_FUNCTION} kind;// 类型属性union {struct {int size; // 字节大小bool is_signed; // 有符号/无符号bool is_const; // const修饰bool is_volatile; // volatile修饰} basic;struct {struct Type* element; // 元素类型int length; // 数组长度(-1=未知)} array;struct {struct Type* pointee; // 指向的类型int address_space; // 地址空间(Cortex-M特有)} pointer;};} Type;
类型系统解析:这个类型系统完整地表示了C语言的所有类型。kind字段区分基本类型、指针类型、数组类型等;union根据类型种类存储不同的属性信息。对于Cortex-M3,address_space字段特别重要,因为Cortex-M3有不同的内存区域(Code、SRAM、Peripheral等),访问不同区域的指令可能不同。
Cortex-M3有特定的内存对齐要求,下面的函数计算各种类型的对齐值:
// Cortex-M3类型对齐规则int get_alignment_for_type(Type* type, TargetArch arch) {if (arch == ARCH_CORTEX_M3) {// Cortex-M3内存访问对齐要求switch (type->kind) {case TYPE_INT:return type->basic.size; // 按大小对齐case TYPE_FLOAT:return 4; // 单精度浮点数4字节对齐case TYPE_POINTER:return 4; // 指针4字节对齐case TYPE_STRUCT:return calculate_struct_alignment(type);default:return 1;}}return 1;}
对齐计算解析:这个函数根据Cortex-M3的架构特性计算类型的对齐要求。Cortex-M3的内存访问有对齐限制,未对齐的访问可能降低性能或导致硬件异常。例如,32位整数和指针需要4字节对齐,单精度浮点数也需要4字节对齐。正确的对齐计算对于生成高效的Cortex-M3代码至关重要。
3.5 中间代码生成与优化
编译器将AST转换为中间表示(IR),然后进行各种优化。ARMCC定义了特定于ARM架构的IR操作码:
// ARM特定IR操作码enum IR_Opcode_ARM {// 内存操作IR_ARM_LDR, // 加载寄存器IR_ARM_STR, // 存储寄存器IR_ARM_LDM, // 多加载IR_ARM_STM, // 多存储// 特殊指令IR_ARM_MRS, // 读系统寄存器IR_ARM_MSR, // 写系统寄存器IR_ARM_CPSID, // 关中断IR_ARM_CPSIE, // 开中断IR_ARM_WFI, // 等待中断IR_ARM_WFE, // 等待事件// Thumb-2扩展IR_THUMB_IT, // IT条件执行块IR_THUMB_CBZ, // 比较为零跳转IR_THUMB_CBNZ, // 比较非零跳转};
IR设计解析:这些ARM特定的IR操作码允许优化器在中间表示级别进行架构相关的优化。例如,IR_THUMB_IT表示Thumb-2的条件执行块,优化器可以将一系列条件指令合并到一个IT块中,减少代码大小。IR_ARM_WFI和IR_ARM_WFE表示休眠指令,优化器可以在适当的位置插入这些指令以降低功耗。
针对Cortex-M3的优化器进行多种窥孔优化,下面的代码展示了优化器的核心逻辑:
// IR优化:针对Cortex-M3的窥孔优化void peephole_optimize_for_cortex_m3(IR_Function* func) {for (each basic block in func) {for (each instruction sequence in block) {// 优化1:LDR/STR合并为LDM/STMif (sequence_is_load_store_multiple(sequence)) {replace_with_ldm_stm(sequence);}// 优化2:消除冗余的MOV指令if (sequence_is_redundant_mov(sequence)) {eliminate_redundant_mov(sequence);}// 优化3:条件执行转换if (can_use_it_block(sequence)) {wrap_with_it_block(sequence);}}}}
优化策略解析:窥孔优化器在小的指令序列中寻找优化机会。对于Cortex-M3,重要的优化包括:将多个LDR/STR指令合并为LDM/STM指令,减少指令数量和执行时间;消除冗余的MOV指令,特别是Thumb到ARM寄存器移动;将条件分支转换为IT条件执行块,利用Thumb-2的条件执行特性减少分支开销。
3.6 后端代码生成
后端将优化后的IR转换为目标架构的汇编代码。指令选择阶段使用模式匹配将IR操作映射到具体的机器指令:
// 指令选择模式匹配InstructionPattern patterns[ ] = {// 加法模式{IR_ADD, {IR_REG, IR_REG, IR_REG},"ADD %0, %1, %2",COST_1_CYCLE, SIZE_2_BYTES},{IR_ADD, {IR_REG, IR_REG, IR_IMM},"ADDS %0, %1, #%2",COST_1_CYCLE, SIZE_2_BYTES,.imm_range = {0, 7}}, // 限制立即数范围// 内存加载模式{IR_LOAD, {IR_REG, IR_MEM},"LDR %0, [%1]",COST_2_CYCLES, SIZE_2_BYTES},{IR_LOAD, {IR_REG, IR_MEM_OFFSET},"LDR %0, [%1, #%2]",COST_2_CYCLES, SIZE_2_BYTES,.offset_range = {0, 1020}}, // 偏移范围限制};
模式匹配解析:指令选择器使用模式匹配将IR操作映射到具体的ARM指令。每个模式指定了IR操作码、操作数类型、目标指令模板、执行代价和代码大小。模式还包含架构限制,如立即数范围或偏移范围。指令选择器选择代价最低且满足约束的模式,生成最优的指令序列。
寄存器分配是后端的关键步骤,下面的代码展示了Cortex-M3的寄存器分配策略:
// Cortex-M3寄存器分配策略void allocate_registers_cortex_m3(IR_Function* func) {// 优先分配低寄存器R0-R7RegisterPool low_regs = {R0, R1, R2, R3, R4, R5, R6, R7};RegisterPool high_regs = {R8, R9, R10, R11, R12};// 特殊寄存器保留reserve_register(R13); // SP堆栈指针reserve_register(R14); // LR链接寄存器reserve_register(R15); // PC程序计数器// 图着色寄存器分配算法InterferenceGraph* graph = build_interference_graph(func);// 分配低寄存器(使用更广泛的指令支持)color_graph(graph, low_regs, 8);// 剩余变量分配高寄存器for (each uncolored variable in graph) {if (can_use_high_register(variable)) {assign_high_register(variable, high_regs);} else {// 需要溢出到栈spill_to_stack(variable);}}}
寄存器分配解析:Cortex-M3的寄存器分配需要特殊考虑。低寄存器R0-R7可以被所有Thumb指令访问,而高寄存器R8-R12只能被部分指令访问。因此,分配器优先将频繁使用的变量分配到低寄存器。图着色算法构建变量间的冲突图,然后尝试用有限的颜色(寄存器)为图着色。无法着色的变量需要溢出到栈中。特殊寄存器SP、LR和PC需要保留,不能用于普通变量。
4. 汇编器:从汇编语言到目标文件
4.1 汇编器两遍扫描流程
汇编器将汇编源代码转换为目标文件,这个过程通常需要两遍扫描。下图展示了汇编器的完整工作流程:
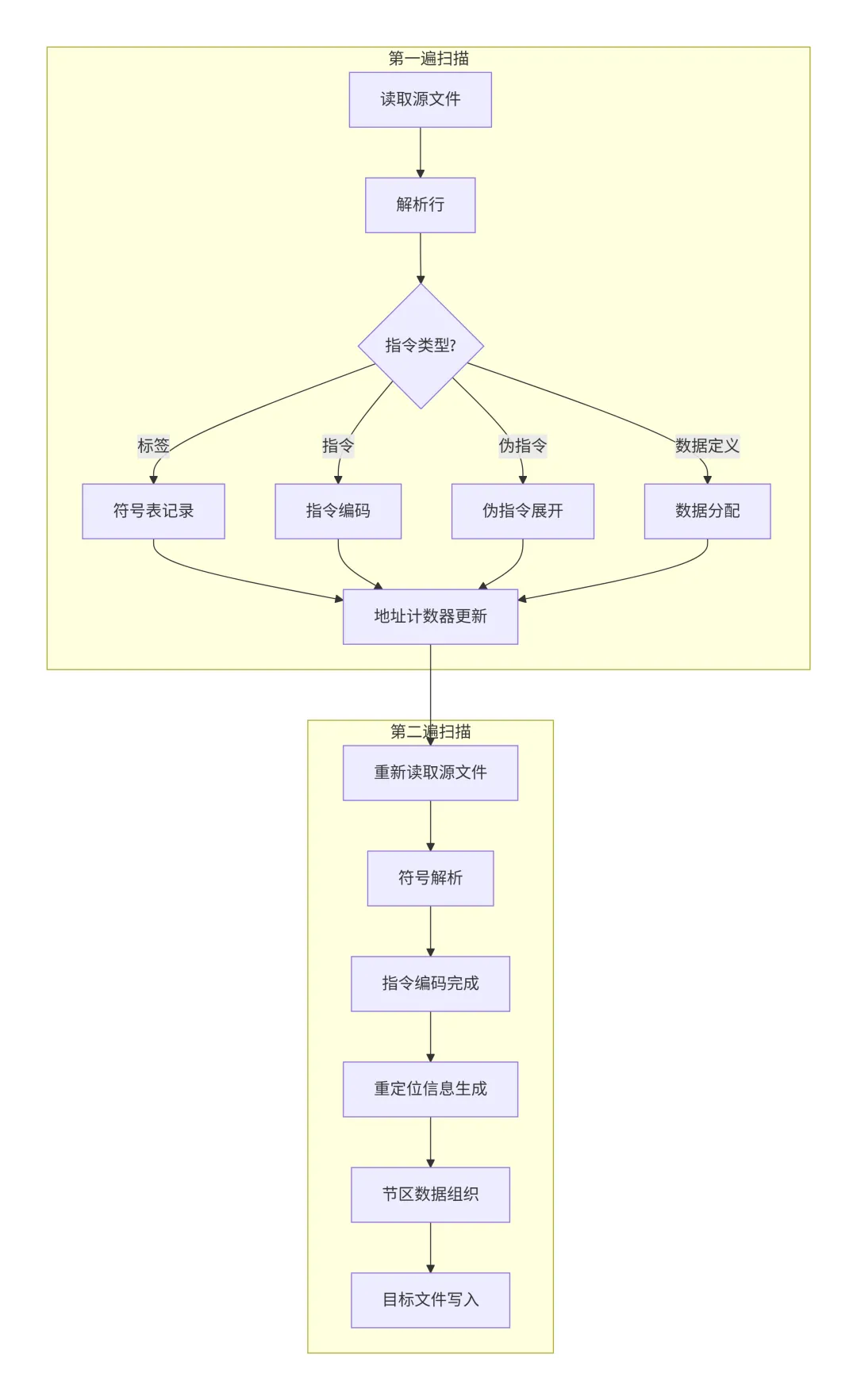
两遍扫描解析:汇编器采用两遍扫描策略处理汇编源文件。第一遍扫描建立符号表并确定所有符号的地址。由于汇编代码中可能包含前向引用(引用后面定义的符号),第一遍扫描只能记录符号位置,不能完成指令编码。第二遍扫描使用第一遍建立的符号表解析所有符号引用,完成指令编码,并生成重定位信息。最后将代码、数据和重定位信息组织成目标文件格式。
4.2 Thumb-2指令编码机制
Thumb-2指令集包含16位和32位两种长度的指令。下面的枚举定义了Thumb指令的不同格式:
// Thumb-2指令编码类typedef enum {THUMB_FORMAT_16, // 16位指令THUMB_FORMAT_32, // 32位指令THUMB_FORMAT_BL, // 分支链接指令THUMB_FORMAT_LDR_LIT, // 文字池加载} ThumbFormat;// 指令编码函数uint32_tencode_thumb_instruction(AssemblyLine* line){// 确定指令格式ThumbFormat format = determine_format(line->opcode, line->operands);switch (format) {case THUMB_FORMAT_16:return encode_16bit_instruction(line);case THUMB_FORMAT_32:return encode_32bit_instruction(line);case THUMB_FORMAT_BL:return encode_branch_link(line);case THUMB_FORMAT_LDR_LIT:return encode_literal_load(line);}return 0;}
指令编码解析:Thumb-2指令编码器根据操作码和操作数确定指令格式。大多数算术逻辑指令是16位格式,而一些复杂操作如带有大立即数的操作是32位格式。BL(分支链接)指令有特殊的编码方式,支持较大的跳转范围。LDR指令从文字池加载常量也有特定的编码格式。编码器根据格式调用相应的编码函数。
下面是一个具体的16位指令编码示例:
// 16位指令编码示例:ADD Rd, Rn, Rmuint32_tencode_add_reg_16(Register rd, Register rn, Register rm){// 编码格式:010000 1100 Rm Rn Rduint32_t encoding = 0;encoding |= (0b010000 << 10); // 操作码encoding |= (0b1100 << 6); // 子操作码encoding |= ((rm & 0x7) << 3); // Rm寄存器(低3位)encoding |= ((rn & 0x7) << 6); // Rn寄存器(低3位)encoding |= (rd & 0x7); // Rd寄存器(低3位)return encoding & 0xFFFF;}
指令编码细节解析:这个函数展示了Thumb 16位ADD指令的编码过程。指令格式固定为16位,操作码占高6位,子操作码占接下来4位,三个寄存器操作数各占3位,分别指定目标寄存器Rd和源寄存器Rn、Rm。注意寄存器编码只使用低3位,这意味着这种格式只能访问寄存器R0-R7。这是Thumb指令集的典型限制,也是为什么寄存器分配器需要优先使用低寄存器的原因。
4.3 重定位信息生成
汇编器为需要链接时解析的符号引用生成重定位信息。下面的枚举定义了ARM ELF格式支持的各种重定位类型:
// ARM ELF重定位类型定义enum ARM_Relocation_Type {R_ARM_NONE = 0,R_ARM_ABS32 = 2, // 32位绝对地址R_ARM_REL32 = 3, // 32位相对地址R_ARM_THM_CALL = 10, // Thumb BL指令R_ARM_THM_JUMP24 = 30, // Thumb B指令R_ARM_THM_MOVW_ABS_NC = 47, // MOVW立即数R_ARM_THM_MOVT_ABS = 48, // MOVT立即数R_ARM_V4BX = 40, // BX指令编码};// 重定位条目生成RelocationEntry* create_relocation(Assembler* asm,uint32_t offset,Symbol* symbol,RelocType type) {RelocationEntry* reloc = malloc(sizeof(RelocationEntry));reloc->offset = offset; // 在节区中的偏移reloc->symbol = symbol; // 引用的符号reloc->type = type; // 重定位类型reloc->addend = 0; // 加数(默认为0)// 计算重定位位置的值uint32_t* location = (uint32_t*)(asm->current_section->data + offset);reloc->original_value = *location;return reloc;}
重定位信息解析:重定位条目记录了需要链接器修改的位置信息。offset字段指定在节区中的偏移位置;symbol字段指定引用的符号;type字段指定重定位类型,决定了链接器如何计算和编码新值;addend字段是加到符号值的常数;original_value字段记录当前位置的原始值,用于调试和错误检查。不同的重定位类型对应不同的指令编码方式,例如R_ARM_THM_CALL用于BL指令,R_ARM_THM_MOVW_ABS_NC用于MOVW指令的立即数字段。
5. 链接器:目标文件合并与地址分配
5.1 链接器处理流程
链接器是编译过程的枢纽,它将多个目标文件合并为单一的可执行文件。下图展示了链接器的完整处理流程:
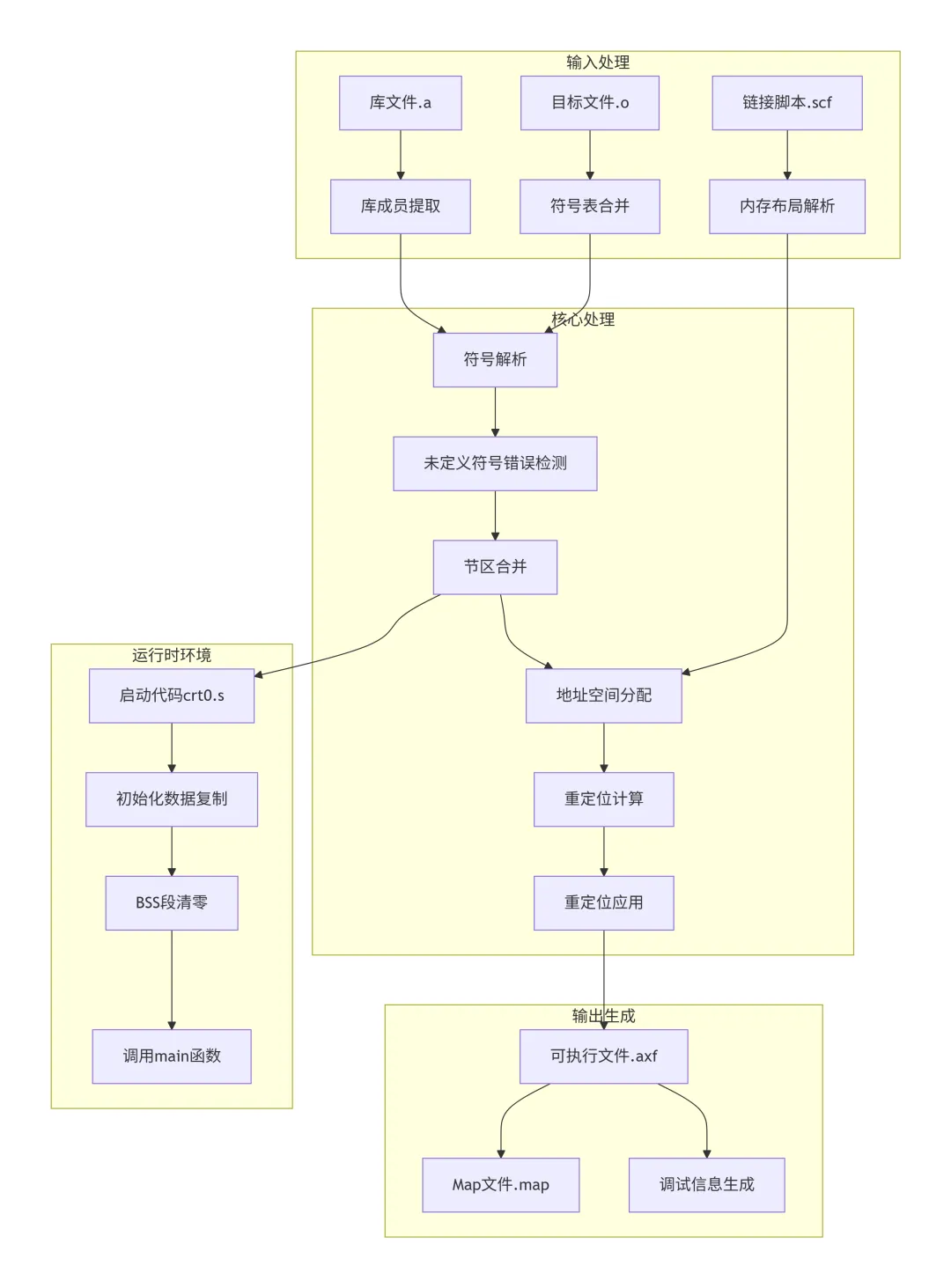
链接流程解析:链接器处理多个输入:目标文件提供代码和数据段;库文件提供可重用的函数;链接脚本定义内存布局。链接器首先合并所有符号表,解析符号引用。然后根据链接脚本将各个节区合并到相应的内存区域,并为每个节区分配具体地址。接着计算所有重定位的值,并修改代码中的符号引用。最后生成可执行文件和调试信息。对于嵌入式系统,链接器还会集成启动代码,负责初始化数据段和调用main函数。
5.2 分散加载文件解析
Cortex-M3系统通常使用分散加载文件定义复杂的内存布局。下面是一个典型的STM32F103分散加载文件示例:
; STM32F103分散加载文件ROM_LOAD 0x08000000 0x00020000 ; Flash: 128KB{; 执行域1:向量表和代码ROM_EXEC 0x08000000 0x00010000{; 必须放在起始位置的向量表vectors.o (RESET, +FIRST); 初始化代码startup_stm32f10x.o (+RO); 所有只读代码和数据* (+RO)}; 执行域2:只读数据的只读副本ROM_EXEC2 0x08010000 0x00008000{* (ER_RW) ; 可执行区域的RW数据副本}; 执行域3:附加Flash区域(如有)ROM_EXEC3 0x08018000 0x00008000{* (UserFlash) ; 用户自定义Flash区域}}RAM_EXEC 0x20000000 0x00005000 ; SRAM: 20KB{; 运行时数据RW_DATA 0x20000000 0x00004000{* (+RW, +ZI) ; 读写和零初始化数据}; 堆栈区域STACK 0x20004000 EMPTY 0x00001000{; 栈向下生长}}
分散加载文件解析:这个分散加载文件定义了Cortex-M3的典型内存布局。ROM_LOAD区域定义Flash的加载区域,包含多个执行域:ROM_EXEC放置向量表和代码,必须从0x08000000开始;ROM_EXEC2放置只读数据的副本;ROM_EXEC3留给用户自定义数据。RAM_EXEC区域定义SRAM的执行区域,RW_DATA放置读写和零初始化数据,STACK区域使用EMPTY关键字保留栈空间而不初始化。+FIRST属性确保向量表放在最前面,+RO选择只读节区,+RW选择读写节区,+ZI选择零初始化节区。
5.3 重定位算法实现
链接器的核心功能是应用重定位,修改代码中的符号引用。下面的代码展示了重定位应用的核心算法:
// 重定位应用核心算法voidapply_relocations(Linker* linker,Section* section,Relocation* relocs,int count) {for (int i = 0; i < count; i++) {Relocation* reloc = &relocs[i];// 获取符号的最终地址uint32_t symbol_addr = get_symbol_address(linker, reloc->symbol);// 计算重定位值uint32_t relocation_value = calculate_relocation(reloc, symbol_addr);// 获取需要修改的位置uint8_t* location = section->data + reloc->offset;// 根据重定位类型应用修改switch (reloc->type) {case R_ARM_ABS32:// 直接替换32位值*(uint32_t*)location = relocation_value;break;case R_ARM_THM_CALL:// Thumb BL指令重定位encode_thm_branch(location, relocation_value);break;case R_ARM_THM_MOVW_ABS_NC:case R_ARM_THM_MOVT_ABS:// MOVW/MOVT指令立即数设置encode_mov_immediate(location,relocation_value,reloc->type);break;}}}
重定位算法解析:这个函数遍历节区中的所有重定位条目。对于每个重定位,首先获取符号的最终地址,然后根据重定位类型计算需要写入的值。最后根据重定位类型将计算得到的值编码到指令中。R_ARM_ABS32是最简单的重定位类型,直接替换32位值;R_ARM_THM_CALL需要编码Thumb BL指令;R_ARM_THM_MOVW_ABS_NC和R_ARM_THM_MOVT_ABS需要编码MOVW和MOVT指令的立即数字段。
Thumb BL指令的编码相对复杂,因为需要将32位偏移编码到两个16位指令中:
// Thumb BL指令编码voidencode_thm_branch(uint8_t* location, int32_t offset){// BL指令偏移范围:±16MB,以2字节对齐offset = offset >> 1; // 转换为半字偏移// 分离高11位和低11位uint32_t S = (offset >> 24) & 0x1;uint32_t I1 = ~((offset >> 23) ^ S) & 0x1;uint32_t I2 = ~((offset >> 22) ^ S) & 0x1;uint32_t imm10 = (offset >> 12) & 0x3FF;uint32_t imm11 = offset & 0x7FF;uint32_t J1 = I1 ^ (~S) & 0x1;uint32_t J2 = I2 ^ (~S) & 0x1;// 编码第一个16位指令uint16_t instr1 = 0xF000 | (S << 10) | imm10;// 编码第二个16位指令uint16_t instr2 = 0x8000 | (J1 << 13) | (J2 << 11) | imm11;// 写入内存(Thumb-2指令是小端)*(uint16_t*)location = instr1;*(uint16_t*)(location + 2) = instr2;}
BL指令编码解析:Thumb BL指令将32位有符号偏移编码到两个16位指令中。偏移首先右移1位(因为Thumb指令是2字节对齐的),然后分离为多个字段:S是符号位,I1和I2是中间位,imm10和imm11是偏移的高低部分。J1和J2是根据I1、I2和S计算得到的校验位。最后将各个字段编码到两个16位指令中,第一个指令的高4位是0xF,第二个指令的高位是0x8。这种复杂的编码方式允许BL指令在有限的指令长度内支持较大的跳转范围。
6. 格式转换器:从ELF到Hex
6.1 ELF文件结构解析
FROMELF工具将ELF格式的可执行文件转换为Intel Hex格式。要理解转换过程,首先需要了解ELF文件的结构。下图展示了ELF文件的各个组成部分:
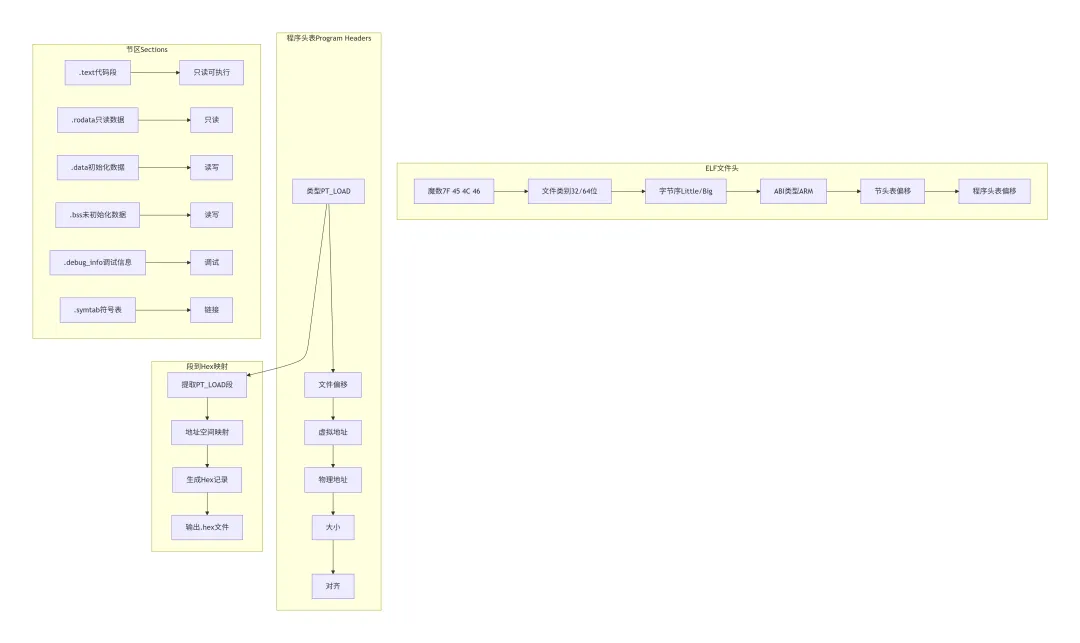
ELF结构解析:ELF文件由文件头、程序头表、节区表和实际数据组成。文件头包含魔数、文件类别、字节序、ABI类型等元信息。程序头表描述程序的段(Segment)信息,特别是PT_LOAD类型的段需要加载到内存中。节区表描述文件的各个节区(Section),如代码段.text、只读数据段.rodata、初始化数据段.data等。FROMELF工具主要关注PT_LOAD段,这些段包含了需要烧录到Flash的代码和数据。
6.2 Hex文件生成算法
FROMELF工具的核心是将ELF文件中的加载段转换为Intel Hex格式。下面的数据结构定义了Hex记录的结构:
// Hex记录结构typedef struct {uint8_t byte_count; // 数据字节数(1-255)uint16_t address; // 起始地址(0-65535)uint8_t record_type; // 记录类型uint8_t data[255]; // 数据uint8_t checksum; // 校验和} HexRecord;
Hex记录解析:Intel Hex格式的每条记录都遵循这个结构。byte_count指定数据字段的字节数;address指定数据在内存中的起始地址(16位,对于扩展地址需要特殊记录);record_type指定记录类型,00表示数据,01表示文件结束,04表示扩展线性地址;data字段包含实际的数据字节;checksum是校验和,用于数据完整性检查。
下面的代码展示了从ELF文件生成Hex文件的核心算法:
// Hex文件生成器HexFile* create_hex_from_elf(ElfFile* elf){HexFile* hex = malloc(sizeof(HexFile));memset(hex, 0, sizeof(HexFile));// 提取所有加载段ElfSegment** load_segments = get_load_segments(elf);int segment_count = count_load_segments(elf);// 按地址排序qsort(load_segments, segment_count,sizeof(ElfSegment*), compare_segment_address);// 生成Hex记录uint32_t current_ext_addr = 0xFFFFFFFF;for (int i = 0; i < segment_count; i++) {ElfSegment* seg = load_segments[i];uint32_t addr = seg->p_vaddr;uint8_t* data = seg->data;uint32_t size = seg->p_filesz;// 处理扩展线性地址uint32_t ext_addr = addr >> 16;if (ext_addr != current_ext_addr) {add_extended_address_record(hex, ext_addr);current_ext_addr = ext_addr;}// 分割数据为多个记录uint32_t offset = 0;while (offset < size) {uint32_t bytes_this_line = min(16, size - offset);uint16_t line_addr = (addr + offset) & 0xFFFF;add_data_record(hex, line_addr,data + offset,bytes_this_line);offset += bytes_this_line;}}// 添加结束记录add_end_record(hex);return hex;}
Hex生成算法解析:这个函数实现了从ELF到Hex的完整转换过程。首先提取所有PT_LOAD类型的段,这些段包含了需要烧录的数据。然后按地址排序,确保生成的Hex记录地址是递增的。对于每个段,如果其地址的高16位(扩展地址)发生变化,需要生成扩展地址记录(类型04)。然后将段数据分割为最多16字节的块,为每个块生成数据记录(类型00)。最后添加文件结束记录(类型01)。这种分段处理方式确保了生成的Hex文件既完整又高效。
校验和是Hex文件的重要部分,用于验证数据完整性:
// 校验和计算uint8_t calculate_checksum(HexRecord* record) {uint32_t sum = record->byte_count;sum += (record->address >> 8) & 0xFF;sum += record->address & 0xFF;sum += record->record_type;for (int i = 0; i < record->byte_count; i++) {sum += record->data[i];}// 计算二进制补码return (~sum + 1) & 0xFF;}
校验和计算解析:Intel Hex格式使用校验和验证记录的正确性。校验和的计算方法是将记录中除起始冒号和结束换行符外的所有字节相加,然后取和的二进制补码(即先取反再加1),最后取低8位。这个校验和机制可以检测传输或存储过程中的单字节错误,确保Hex文件的完整性。
7. 常见问题及答疑
7.1 预处理阶段常见问题
Q1:为什么宏展开时会出现意外的结果?
这个问题通常是由于宏参数没有正确使用括号导致的。考虑下面的示例:
// 示例问题代码#defineSQUARE(x) x * xint result = SQUARE(2 + 3); // 期望25,实际得到11// 原因:宏展开为 2 + 3 * 2 + 3 = 2 + 6 + 3 = 11// 解决方法:使用括号#defineSQUARE(x) ((x) * (x))
问题解析:C预处理器进行简单的文本替换,不遵循C语言的运算符优先级规则。当宏参数是表达式时,如果不加括号,替换后可能改变表达式的求值顺序。正确的做法是为每个参数和整个宏体都加上括号,确保展开后的表达式具有正确的优先级。
Q2:条件编译如何正确使用?
条件编译是C语言的重要特性,但使用时需要注意一些细节:
// 错误示例#ifdefined(DEBUG) // DEBUG未定义时,条件为假printf("Debug mode\n");#elifdefined(RELEASE) // 永远不会执行到这里printf("Release mode\n");#endif// 正确做法#ifdefDEBUGprintf("Debug mode\n");#elseprintf("Release mode\n");#endif
问题解析:defined()操作符在参数未定义时返回0,因此#ifdefined(DEBUG)在DEBUG未定义时条件为假,#elif分支永远不会被执行。正确的做法是使用#ifdef或#ifndef指令,它们专门用于检查标识符是否已定义。对于复杂的条件组合,可以使用#ifdefined() && defined()的形式。
7.2 编译阶段常见问题
Q3:为什么有些优化选项会导致代码行为异常?
优化编译器有时会改变代码的执行顺序或消除看似无用的代码,这可能导致与硬件交互的代码出现问题:
// 问题代码volatile int* status_reg = (int*)0x40021000;while ((*status_reg & 0x01) == 0); // 等待标志位// 问题:启用-O2优化后,编译器可能认为循环条件不变,优化掉循环// 解决方法:正确使用volatile关键字,或使用内存屏障__asm volatile("" ::: "memory");
问题解析:优化编译器假设程序内存状态只在代码明确修改时变化。对于硬件寄存器,这个假设不成立,因为寄存器的值可能被硬件改变。volatile关键字告诉编译器该变量的值可能在任何时候改变,不应进行优化。对于更复杂的情况,可以使用内联汇编内存屏障阻止编译器重排内存访问。
Q4:内联汇编的正确写法?
内联汇编允许在C代码中直接使用汇编指令,但必须正确编写以避免问题:
// 错误示例(缺少clobber列表)__asm {MOV R0,#1MOV R1,#2ADD R0, R0, R1}// 问题:编译器不知道修改了哪些寄存器// 正确写法__asm volatile("MOV R0,#1\n\t""MOV R1,#2\n\t""ADD %0, R0, R1": "=r"(result) // 输出操作数: // 输入操作数: "r0", "r1" // clobber列表);
问题解析:GCC风格的内联汇编需要指定输入输出操作数和clobber列表。输出操作数指定汇编代码写入的C变量;输入操作数指定汇编代码读取的C变量;clobber列表指定汇编代码修改的寄存器或内存。这种格式帮助编译器正确分配寄存器并理解汇编代码的副作用。
7.3 链接阶段常见问题
Q5:如何解决”undefined reference”错误?
链接时未定义引用是常见错误,通常有以下原因和解决方案:
// 常见原因和解决方案:// 1. 缺少库文件:添加 -l 参数指定库// 2. 库文件顺序错误:调整链接顺序// 3. 函数声明不匹配:检查头文件和实现// 4. C/C++混合编译:使用 extern "C"// Cortex-M3特殊:需要链接启动文件// 错误:undefined reference to `Reset_Handler'// 解决:确保启动文件(startup_xxx.s)已链接
问题解析:未定义引用错误表示链接器找不到符号的定义。对于Cortex-M3项目,常见的未定义符号是Reset_Handler,这是复位向量指向的启动函数。确保链接了正确的启动文件(通常以startup_开头的.s文件)。其他常见原因包括忘记链接必要的库文件,或者库文件的链接顺序不正确(依赖的库应该放在后面)。
Q6:分散加载文件编写注意事项?
分散加载文件语法严格,编写时需要注意避免常见错误:
// 常见错误1:地址重叠ROM_LOAD 0x08000000 0x00010000 {// 错误:两个执行域地址重叠EXEC1 0x08000000 0x00008000 { ... }EXEC2 0x08004000 0x00008000 { ... } // 与EXEC1重叠}// 常见错误2:忘记EMPTY关键字STACK 0x20004000 0x00001000 { // 错误:未使用EMPTY// 这里不应该有内容}// 正确写法STACK 0x20004000 EMPTY 0x00001000 {// EMPTY表示不加载任何数据,仅保留空间}
问题解析:分散加载文件中的执行域不能有地址重叠,否则链接器会报错。对于栈、堆等不包含初始化数据的区域,必须使用EMPTY关键字,否则链接器会尝试从输入文件中寻找数据填充这些区域,导致错误。正确使用EMPTY关键字告诉链接器这些区域在加载时没有数据,只在运行时使用。
7.4 Hex文件相关问题
Q7:Hex文件比实际Flash大很多?
Hex文件可能比实际的二进制数据大,原因如下:// 原因分析:1. 地址不连续导致多个记录:020000040800F2 // 扩展地址记录(6字节):10xxxx00... // 数据记录(16+5=21字节)2. 调试信息未剥离fromelf --bin --output=output.bin input.axf3. 使用了Intel Hex格式的扩展记录// 考虑使用二进制格式节省空间
问题解析:Intel Hex格式是文本格式,包含地址、长度、类型、数据和校验和等信息,因此比纯二进制数据大。地址不连续时,需要插入扩展地址记录,进一步增加文件大小。如果Hex文件包含调试信息,会更大。对于空间受限的系统,可以考虑使用二进制格式(.bin)或压缩Hex文件。
Q8:Hex文件下载失败的可能原因?
Hex文件下载失败可能由多种原因引起:
1. 地址超出Flash范围- 检查链接脚本中的地址- 确认芯片的Flash大小2. 校验和错误- 使用hex编辑器验证校验和- 重新生成Hex文件3. 格式不兼容- 确认编程器支持的Hex格式- 尝试Motorola S-record格式
问题解析:下载失败的最常见原因是地址超出目标设备的Flash范围。检查链接脚本中定义的地址是否与芯片规格匹配。校验和错误可能表示文件损坏,重新生成Hex文件通常可以解决。不同的编程器可能支持不同的Hex格式变体,确认编程器文档支持的格式。
7.5 性能与优化问题
Q9:如何优化Cortex-M3代码大小?
Cortex-M3的Flash容量通常有限,优化代码大小很重要:
// 1. 使用-0space优化选项#pragmaOspace// 2. 使用Thumb指令集(默认)// 3. 优化数据结构对齐#pragmapack(push, 1) // 1字节对齐struct SensorData {uint8_t id;uint16_t value;uint32_t timestamp;};#pragmapack(pop)// 4. 使用查表代替复杂计算const uint16_t sin_table[256] = {...};uint16_t sin_value = sin_table[angle & 0xFF];
优化解析:-Ospace选项告诉编译器优先优化代码大小而非执行速度。Thumb-2指令集本身就比ARM指令集更紧凑。结构体对齐优化可以减少填充字节,特别是对于包含不同大小成员的结构体。查表法用空间换时间,对于复杂的数学函数特别有效,Cortex-M3的Flash读取速度很快,查表通常比计算更快。
Q10:如何优化Cortex-M3执行速度?
对于实时性要求高的应用,优化执行速度是关键:
// 1. 使用-Otime优化选项#pragmaOtime// 2. 关键函数使用内联__inline voiddelay_us(uint32_t us){// 精确延时函数}// 3. 使用硬件加速特性// Cortex-M3有硬件乘法器和除法器uint32_tmultiply(uint32_t a, uint32_t b){return a * b; // 使用单周期乘法器}// 4. 内存访问优化// 使用字对齐访问uint32_tread_word(uint32_t* addr){return *addr; // 字对齐访问最快}
优化解析:-Otime选项优先优化执行速度。内联关键的小函数可以消除函数调用开销。Cortex-M3的硬件乘除法器比软件实现快得多,应该充分利用。内存访问对齐对于性能至关重要,未对齐的访问需要多个总线周期。对于频繁访问的数据,考虑使用Cortex-M3的位带特性进行原子位操作。
8. 总结
8.1 编译过程关键技术点回顾
Keil编译过程是一个复杂的多阶段处理流水线,每个阶段都有其关键技术:
8.2 Cortex-M3编译特殊考量
Cortex-M3架构在编译过程中需要特殊考虑:
8.3 构建自定义工具链的建议
基于对Keil编译过程的深入理解,构建自定义工具链需要考虑:
通过深入理解Keil编译过程的每个环节,开发者不仅可以更高效地使用现有工具链,还能为构建自定义编译系统奠定坚实基础。这种理解有助于调试复杂的编译问题,优化代码性能和大小,以及为特定应用定制编译过程。后续章节将深入探讨Hex文件下载到Cortex-M3的完整过程,以及Keil调试器如何实现源码级调试,完成嵌入式开发工具链的完整解析。
