 夜雨聆风
夜雨聆风





给YOLOv8装上这个“去噪”插件,微小目标检测能力竟暴涨97%!


这是一个基于论文 《Position Guided Dynamic Receptive Field Network: A Small Object Detection Friendly to Optical and SAR Images》 的详细解读。作为一名博士研究生,我整理了这份深度笔记,重点解析了其针对遥感图像小目标检测(SOD)提出的核心创新机制。
以下是为您准备的 Markdown 格式文件内容,您可以直接用于公众号发布。
深度解读 PG-DRFNet:一种对光学与 SAR 图像友好的位置导向动态感受野网络
论文标题:Position Guided Dynamic Receptive Field Network: A Small Object Detection Friendly to Optical and SAR Images
发表期刊:IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), August 2025
关键词:小目标检测、动态感受野、位置导向关系、动态感知头、遥感图像
1. 核心思想
[cite_start]本文提出了一种名为 PG-DRFNet (Position Guided Dynamic Receptive Field Network) 的网络结构,旨在解决遥感图像(包括光学和合成孔径雷达 SAR 图像)中小目标容易在深层特征中“消失”或“被淹没”的问题 [cite: 8, 9]。
[cite_start]其核心在于构建了一个动态感受野(DRF)模块,通过建立不同特征层之间小目标的位置导向关系(Positional Guidance Relationship),引导网络关注小目标所在的区域 [cite: 9][cite_start]。同时,设计了一种推理时的动态感知算法(Dynamic Perception Algorithm),通过重组特征(Flat-wise feature construction)来动态优化感知区域,从而在保持高精度的同时显著提升推理速度 [cite: 11]。
2. 背景与动机
为什么要研究这个问题?
遥感图像(RSI)中的物体检测面临着独特的挑战,主要体现在以下几个方面:
1. [cite_start]极小目标占比高:在 DOTA-v2.0 和 HRSID 等数据集中,小目标(像素)占比高达 80% 左右。传统的卷积神经网络在下采样过程中,这些小目标的特征极易丢失或被背景噪声淹没 [cite: 40]。
2. [cite_start]感受野不匹配:现有的检测器大多采用静态的感受野设计,无法适应 RSI 中从小汽车到大港口的多尺度变化,难以捕捉足够的上下文信息 [cite: 30, 31]。
3. [cite_start]多模态适应性差:光学图像纹理丰富但易受光照影响,SAR 图像全天候但存在相干斑噪声和特殊的散射特性。现有方法往往针对单一模态优化,缺乏统一且鲁棒的框架 [cite: 35, 109]。
4. [cite_start]静态推理效率低:大部分 RSI 图像中背景占据绝大面积(如大海中的几艘船),全图均匀计算会造成巨大的算力浪费 [cite: 78, 81]。
[在此处插入文中 Fig. 1]
(图注:遥感数据集中的目标尺寸统计与示例。可以看到小目标占比极高,且光学与 SAR 图像在视觉特征上有显著差异。)
3. 主要贡献点
本文的主要贡献可以归纳为以下四点:
1. 提出了 PG-DRFNet 统一框架
[cite_start]设计了一个能够同时兼容光学和 SAR 两种模态的检测框架。该框架没有使用繁琐的模态特定预处理,而是通过网络结构本身的设计(特别是位置导向机制)来增强对两类图像中小目标的鲁棒性,在 DOTA-v2.0、VEDAI(光学)以及 SSDD、HRSID(SAR)四个基准数据集上均取得了 SOTA 性能 [cite: 12, 13]。
2. 设计了基于位置导向关系的动态感受野 (DRF)
[cite_start]为了防止小目标特征消失,作者提出了一种跨层的“位置导向关系”。通过利用小目标的 Ground Truth (GT) 信息作为监督,显式地在不同特征层之间建立联系。这种机制不仅增强了特征融合,还生成了包含关键位置信息的逻辑值图(Logical Value map),用于后续指导检测头 [cite: 85, 187]。
3. 提出了组合检测头 (Combination Head, CH)
打破了传统单一检测头的限制,设计了包含基础头 (BH)、位置导向头 (PGH) 和动态感知头 (DPH) 的组合结构。
• PGH 负责在训练阶段学习位置导向信息;
• DPH 负责在推理阶段利用这些信息进行动态特征挖掘。
[cite_start]这种解耦设计使得训练过程监督更强,而推理过程更灵活高效 [cite: 86, 371]。
4. 开发了基于特征重构的动态感知算法
[cite_start]针对推理阶段,提出了一种“Flat-wise”(扁平化)特征构建算法。不同于简单的特征堆叠(Stacking-wise),该算法根据位置导向图,仅裁剪并聚合包含目标的有效区域进行计算。这在几乎不损失精度(仅下降 0.02% mAP)的情况下,将推理速度从 18.1 FPS 提升到了 27.0 FPS [cite: 87, 571]。
4. 方法细节(核心深度解析)
PG-DRFNet 的整体架构采用了 CSPDarkNet 作为骨干网络,核心创新在于中间的动态感受野(DRF)和末端的组合头(Heads)。
[在此处插入文中 Fig. 2]
(图注:PG-DRFNet 的整体架构图。Backbone 提取特征,Dynamic Receptive Field 融合特征并建立位置导向,Heads 部分包含 PGH、DPH 和 BH。)
4.1 动态感受野 (Dynamic Receptive Field, DRF)
DRF 旨在解决多尺度特征融合中的不平衡和小目标消失问题。
1. 多层特征融合与重加权:
网络提取了 四层特征,其中 是为了小目标保留的高分辨率特征。融合过程不仅是简单的相加,还引入了感受野权重 进行重加权(Re-weighting),公式如下:
[cite_start]这确保了网络不会过度关注某一单一尺度,避免大目标特征主导优化过程 [cite: 286]。
2. 位置导向关系的建立 (Positional Guidance Relationship):
这是本文的灵魂所在。为了让深层特征“知道”小目标在哪里,作者利用小目标的 GT 面积筛选出“小目标集合”,并将其映射到特征图网格上。
这个过程生成了一个位置导向逻辑值 ,它像一个“蒙版”,告诉网络哪些区域是必须保留的,哪些是背景可以忽略的。
• 距离计算:计算网格中心 与小目标中心 的距离 。
• [cite_start]关键位置生成:如果距离小于阈值 ,则该网格位置被标记为关键位置(Key Position, ),否则为 0 [cite: 338]。
[在此处插入文中 Fig. 3]
(图注:位置导向关系的建立过程。筛选出小面积的 GT,将其映射到特征层生成逻辑值,用于后续的额外监督。)
4.2 组合检测头 (Combination Head)
作者设计了三种头协同工作:
• Base Head (BH):处理最高层特征 ,仅负责常规的大目标检测,不参与导向。
• [cite_start]Positional Guidance Head (PGH):训练专用。它不仅学习分类和回归,还额外增加了一个分支来回归“位置导向逻辑值”。它的损失函数 包含了导向损失 (Focal Loss形式),强制网络学习区分小目标区域和背景 [cite: 381, 391]。
• Dynamic Perception Head (DPH):推理专用。它利用 PGH 学到的导向信息,在推理时动态选择特征区域。
4.3 动态感知算法 (Dynamic Perception Algorithm)
这是实现“即插即用”加速的关键。作者对比了两种特征构建方式:
1. 探索版 (Stacking-wise):将关键区域的特征在通道维度上进行堆叠。优点是快,但破坏了原始的空间分布,导致精度下降。
2. 优化版 (Flat-wise):最终采用方案。
[cite_start]这种方式既剔除了大量背景冗余计算,又保留了目标局部的空间结构(Algorithm 1)[cite: 358, 370]。
• Step 1: 根据 PGH 预测的导向图 和阈值 ,激活关键区域(Guidance Regions, GRs)。
• Step 2: 以 GR 为边界,对候选特征 进行裁剪(Cropping)。
• Step 3: 将裁剪出的有效区域进行聚合(Aggregation),形成一个新的、紧凑的特征图 。
[在此处插入文中 Fig. 4]
(图注:动态感知算法示意图。(a) 简单的堆叠方式破坏了空间结构;(b) 优化后的 Flat-wise 方式通过裁剪和聚合,保留了空间结构并实现了加速。)
5. 即插即用模块的作用与应用场景
本文提出的方法不仅仅适用于这一个网络,其中的某些模块具有很高的复用价值,可作为“即插即用”的组件改进其他检测器。
5.1 动态感知模块 (Dynamic Perception Module)
• 作用:在推理阶段,根据粗略的预测(或导向图)动态裁剪无效背景,仅计算有目标的区域。
• 适用场景:
• 稀疏小目标检测:如海面舰船检测(SAR/光学)、高空无人机对地侦察。背景是大面积海水或陆地,目标稀疏。
• 算力受限的边缘设备:在无人机、卫星星上处理芯片上,通过该模块可以大幅减少 FLOPs,实现实时处理。
• 具体应用:可以将此算法集成到 YOLO 系列或 RTMDet 中,作为推理加速插件。
5.2 位置导向损失 (Positional Guidance Loss)
• 作用:一种辅助监督信号。在训练阶段,强制网络的中间层特征“记住”小目标的位置,防止随着网络加深特征丢失。
• 适用场景:
• 所有基于 FPN 的小目标检测器:任何存在多尺度特征融合的网络(如 RetinaNet, FCOS),都可以引入这个辅助分支来提升对小目标的召回率。
• 弱小目标检测:如红外弱小目标检测,通过显式的位置监督增强特征表达。
5.3 组合头架构 (Combination Head Architecture)
• 作用:解耦训练和推理的需求。训练时用重型头(PGH)学知识,推理时用轻量化动态头(DPH)提速度。
• 具体应用:适用于任何需要平衡“高精度训练”和“高效率部署”的工业级检测模型开发。
总结:PG-DRFNet 通过“位置导向”解决了小目标特征难提取的痛点,通过“动态感知”解决了大图推理慢的痛点。这篇论文对于从事遥感图像处理、无人机视觉以及细粒度物体检测的研究人员具有很高的参考价值。
DNTR:基于去噪FPN与Transformer R-CNN的微小目标检测新范式
论文题目: A DeNoising FPN with Transformer R-CNN for Tiny Object Detection
论文来源: IEEE / arXiv:2406.05755v4
主要作者: Hou-I Liu, Hong-Han Shuai, Wen-Huang Cheng (National Yang Ming Chiao Tung University & NTU)
1. 核心思想 (Core Idea)
这篇论文提出了一种名为 DNTR (DeNoising FPN with Transformer R-CNN) 的新型检测框架,专门旨在解决微小目标检测(Tiny Object Detection, TOD)中的痛点。
其核心思想可以概括为两步走策略:
-
特征层面“去噪”:针对特征金字塔(FPN)在特征融合过程中产生的“噪声”(即几何信息和语义信息的失真),设计了一个DN-FPN模块。它利用对比学习,强制融合后的特征在几何上对齐底层特征,在语义上对齐高层特征,从而获得更纯净的特征表达。 -
检测头层面“精细化”:鉴于传统 CNN 检测头在捕获全局信息上的不足,以及标准 Transformer (如 DETR) 在微小目标上收敛难、背景误检高的问题,提出了一种Trans R-CNN检测头。它结合了 RPN 的定位能力和 Transformer 的自注意力机制,并通过“洗牌展开(Shuffle Unfolding)”增强局部细节。
2. 背景与动机 (Background & Motivation)
为什么要研究这个问题?
随着无人机和遥感技术的发展,城市规划、环境监测、海上救援等领域迫切需要对航拍图像中的物体进行检测。然而,这些物体往往极小(论文定义微小目标为小于 像素),在海量背景中如同大海捞针。
现有方法存在的问题
-
FPN 的特征融合噪声: 传统的 FPN 通过自顶向下的路径融合多尺度特征。然而,这一过程并不完美:
-
通道缩减(1×1 Conv) 会导致几何信息(Geometric Information)的损失或噪声。
-
上采样(Upsampling) 会引入冗余信息,导致语义信息(Semantic Information)的噪声。
-
对于大目标,这些微小的特征失真可能无关痛痒;但对于仅有几个像素的微小目标,这种噪声是致命的。
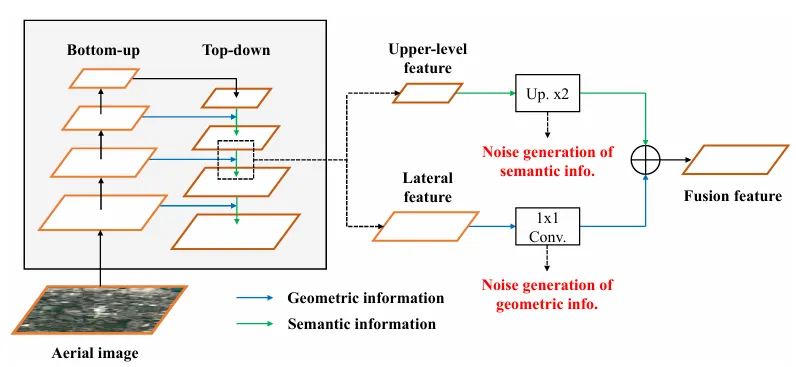
FPN 的特征融合噪声: 传统的 FPN 通过自顶向下的路径融合多尺度特征。然而,这一过程并不完美:
-
通道缩减(1×1 Conv) 会导致几何信息(Geometric Information)的损失或噪声。 -
上采样(Upsampling) 会引入冗余信息,导致语义信息(Semantic Information)的噪声。 -
对于大目标,这些微小的特征失真可能无关痛痒;但对于仅有几个像素的微小目标,这种噪声是致命的。
图1展示了传统FPN中,1×1卷积和上采样操作如何分别破坏几何信息和语义信息,从而产生噪声。
-
检测器的局限性:
-
两阶段检测器(如 Faster R-CNN):虽然定位准,但缺乏捕捉长距离依赖(全局上下文)的能力。 -
Transformer 检测器(如 DETR):虽然有全局视野,但直接处理整图特征导致计算量大,且容易被背景噪声干扰,导致对微小目标的高误报率(False Positives)。
3. 主要贡献点 (Major Contributions)
本文的贡献主要体现在以下三个方面:
(1) 提出了 DNTR 框架,刷新了 SOTA
作者提出了 DNTR 框架,结合了去噪的特征金字塔和增强的 Transformer 检测头。实验结果表明,该方法在 AI-TOD(微小目标检测基准数据集)上取得了 26.2% 的 AP,超越了当时的 SOTA 模型(如 RFLA, DetectoRS 等),特别是在极微小目标()指标上提升显著(比基线提升至少 17.4%)。
(2) 首创 DN-FPN:基于对比学习的特征去噪
这是本文最大的亮点之一。不同于以往通过添加复杂模块来增强 FPN 的方法,DN-FPN 引入了一种几何-语义对比学习(Geometric-Semantic Contrastive Learning)机制。
-
差异点:它不改变 FPN 的推理结构,仅在训练阶段通过损失函数约束特征,使其“去噪”。 -
优势:这意味着在推理阶段,参数量和计算量(FLOPs)的增加为零,但特征质量大幅提升。
(3) 设计了 Trans R-CNN 检测器
为了解决 Transformer 在微小目标上的适应性问题,作者设计了 Trans R-CNN。
-
Shuffle Unfolding(洗牌展开):通过打乱顺序的过采样技术,从有限的像素中提取更丰富的局部空间细节。
-
**MTE (Mask Transformer Encoder)**:利用带掩码的自注意力机制,既捕获了全局信息,又避免了分类任务和回归任务特征的相互干扰。
-
差异点:相比于标准的 ViT 或 R-CNN Head,这种设计专门针对 RoI(感兴趣区域)内部的微弱信号进行了强化。
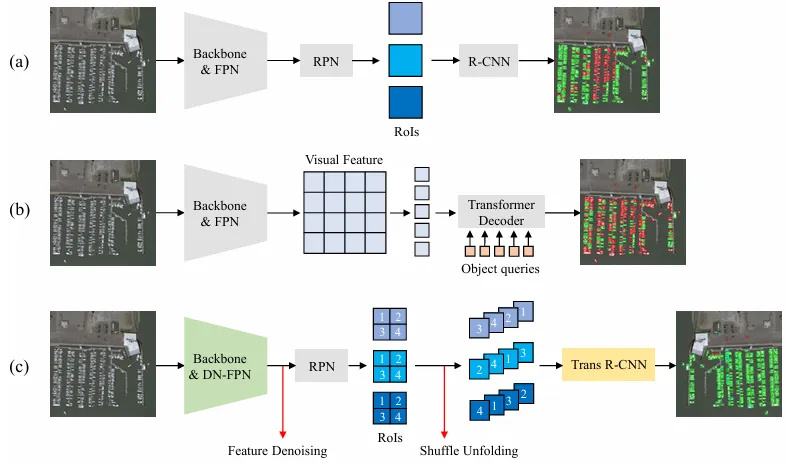
图2对比了 (a) CNN两阶段模型,(b) DETR类模型,和 (c) 本文提出的 DNTR。DNTR 结合了特定区域建议(RPN)的精准和 Transformer 的全局建模能力。
图2对比了 (a) CNN两阶段模型,(b) DETR类模型,和 (c) 本文提出的 DNTR。DNTR 结合了特定区域建议(RPN)的精准和 Transformer 的全局建模能力。
4. 方法细节 (Method Details)
4.1 总体架构
DNTR 的整体流程如下:图像经过骨干网(ResNet50)提取特征 -> 进入 DN-FPN 进行特征融合与去噪 -> 通过 RPN 生成候选框(Proposals) -> 使用 RoIAlign 提取特征 -> 进入 Trans R-CNN 进行最终的分类与回归。
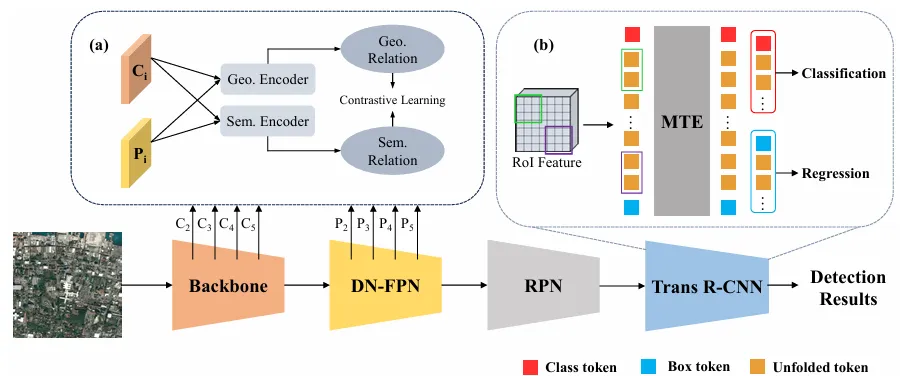
图3展示了 DNTR 的整体架构,左侧为 DN-FPN 模块,右侧为 Trans R-CNN 检测头。
图3展示了 DNTR 的整体架构,左侧为 DN-FPN 模块,右侧为 Trans R-CNN 检测头。
4.2 核心创新一:DN-FPN (去噪 FPN)
理念:融合后的特征 应该同时具备:
-
与底层特征 相同的几何信息。 -
与上层特征 相同的语义信息。
机制:作者使用了 InfoNCE Loss 进行对比学习。 为了实现这一点,设计了两个编码器:几何编码器(Geometric Encoder)和语义编码器(Semantic Encoder),将特征映射到嵌入空间。
公式解读:
-
**几何关系 (Geometric Relation)**: 我们希望融合特征 (Query)与侧向输入特征 (Positive Key)在几何表达上尽可能接近。而与其他层级或其它图像的特征(Negative Keys)尽可能远离。
几何对比损失函数定义为:
其中, 是融合特征的几何表示, 是对应的底层特征几何表示(正样本), 是负样本集合。
-
**语义关系 (Semantic Relation)**: 同理,融合特征 应该与上层特征 在语义上一致。
语义对比损失函数定义为:
通过最小化这两个损失,网络被迫学习如何“过滤”掉由上采样和降维带来的噪声。
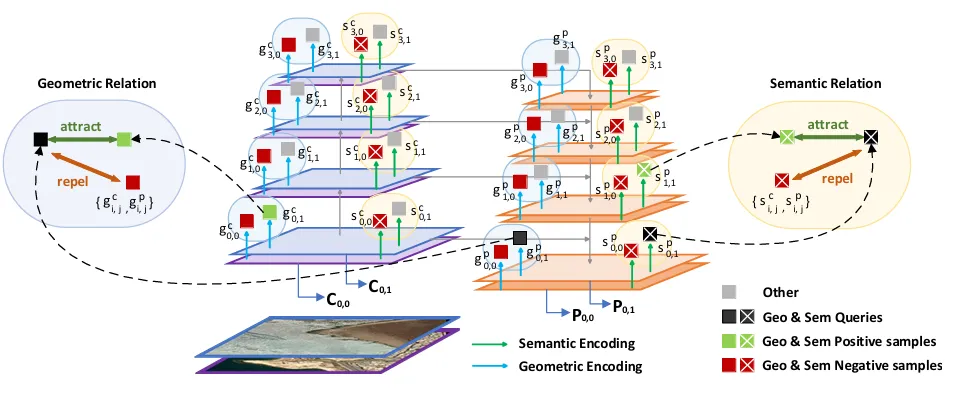
图4详细解释了对比学习的正负样本构造策略。
图4详细解释了对比学习的正负样本构造策略。
4.3 核心创新二:Trans R-CNN
该模块旨在处理 RoIAlign 后的特征,使其对微小目标更敏感。
-
**Shuffle Unfolding (洗牌展开)**: 微小目标的像素非常少。为了增加特征的多样性,作者没有使用传统的栅格扫描顺序将 RoI 展平,而是使用了滑动窗口 + 洗牌(Shuffle)策略。
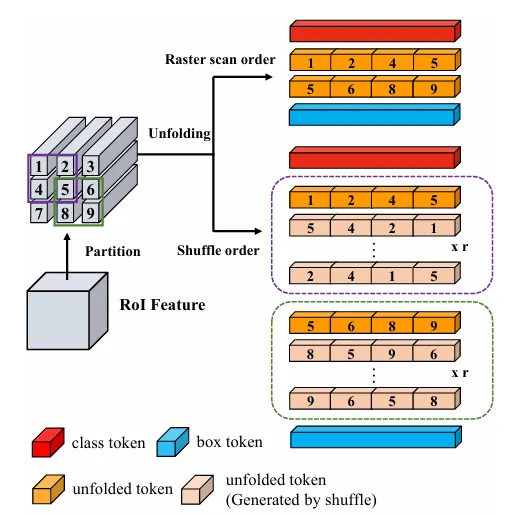
图6展示了如何通过洗牌操作生成多样化的 Unfolded Tokens。
图6展示了如何通过洗牌操作生成多样化的 Unfolded Tokens。
-
这实际上是一种过采样(Oversampling)技术,通过不同的排列组合,让 Transformer 看到更多的局部细节模式。 -
论文中提到,相比于标准扫描,Shuffle Order 可以极大地丰富 Token 的多样性。 -
**Mask Transformer Encoder (MTE)**: 输入序列包含三部分:分类 Token (),回归 Token (),以及展开的图像特征 Tokens ()。
-
机制:在 Self-Attention 计算时加入 Mask,切断 和 之间的联系。 -
目的:防止分类任务和定位任务的特征相互干扰(这是一个常见的 Two-stage 检测问题),同时让它们都能充分利用图像特征 的全局信息。 -
**Task Token Selection (任务 Token 选择)**: 经过 MTE 编码后,并不是所有图像 Token 对分类和回归都同等重要。作者根据注意力分数(Attention Score),动态地将图像 Token 分配给分类组 或回归组 ,进一步提升了特征的专一性。
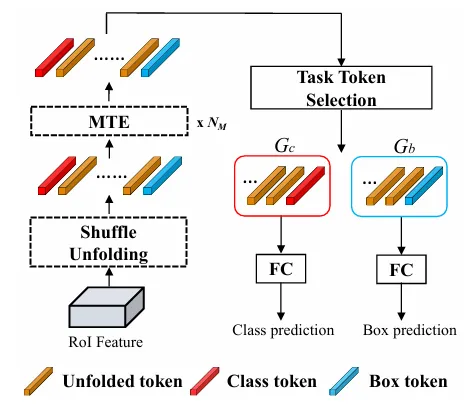
Fig. 5: The structure of Trans R-CNN
Fig. 5: The structure of Trans R-CNN
5. “即插即用”模块的作用与应用 (Plug-and-Play Analysis)
这篇论文最令人兴奋的部分在于 DN-FPN 模块的高度通用性。
模块特性
-
**训练时 (Training Phase)**:DN-FPN 作为一个辅助分支存在,包含几何/语义编码器,计算对比损失 和 。
-
推理时 (Inference Phase):完全移除。编码器和损失计算部分全部丢弃,只保留训练好的 FPN 参数。
-
成本:推理阶段 0 参数增加,0 FLOPs 增加。
适用场景
由于 FPN(特征金字塔)是目前绝大多数目标检测器的标配,DN-FPN 理论上可以“插入”到任何包含 FPN 结构的检测器中,用于提升特征质量。
具体应用罗列
论文在实验部分(Table VIII)展示了该模块强大的兼容性,以下场景均可直接应用:
-
**增强单阶段检测器 (One-Stage Detectors)**:
-
**YOLO 系列 (如 YOLOv8)**:论文展示了将 YOLOv8 的 PAN-FPN 替换/增强为 DN-FPN 后,在保持原有 FPS(速度)不变的情况下,AP 提升了 **61.2%**,(极微小目标)提升了 **97.1%**。这是非常惊人的提升。 -
FoveaBox / ATSS:对于 Anchor-free 的检测器,DN-FPN 同样带来了 5-7 个点的 AP 提升。 -
**增强两阶段检测器 (Two-Stage Detectors)**:
-
Faster R-CNN:经典老将加上 DN-FPN 后,微小目标检测能力显著增强。 -
DetectoRS:即使是像 DetectoRS 这样本身就具有递归特征金字塔的强力模型,DN-FPN 依然能进一步“净化”其特征,带来性能增益。 -
极端场景下的目标检测:
-
无人机巡检:电池续航敏感,不能上大模型。使用 DN-FPN 训练的小模型(如 YOLO-Small),可以在不增加推理负担的前提下,大幅提升对地面行人、车辆的识别率。 -
卫星遥感分析:处理超大尺幅图像时,DN-FPN 有助于保留降采样过程中易丢失的微弱信号。
总结
DN-FPN 是一个完美的“免费午餐”模块。如果你正在开发基于 FPN 的检测模型,且苦恼于小目标漏检,强烈建议在训练代码中加入 DN-FPN 的对比损失,这几乎不需要改变你的推理部署流程。
END
点分享

点收藏

点点赞

点在看

