 夜雨聆风
夜雨聆风





MCP加持下全自动化绕过验签&加密app
首发自先知社区:https://xz.aliyun.com/news/91055记录了一下工作中遇到的验签和加密的app的全自动化分析和绕过方案,其中值得关注的是如何不看一点代码和写一点代码就实现全自动化绕过的思路,本文只记录绕过方案,不涉及任何渗透测试操作
1.初始情况展示
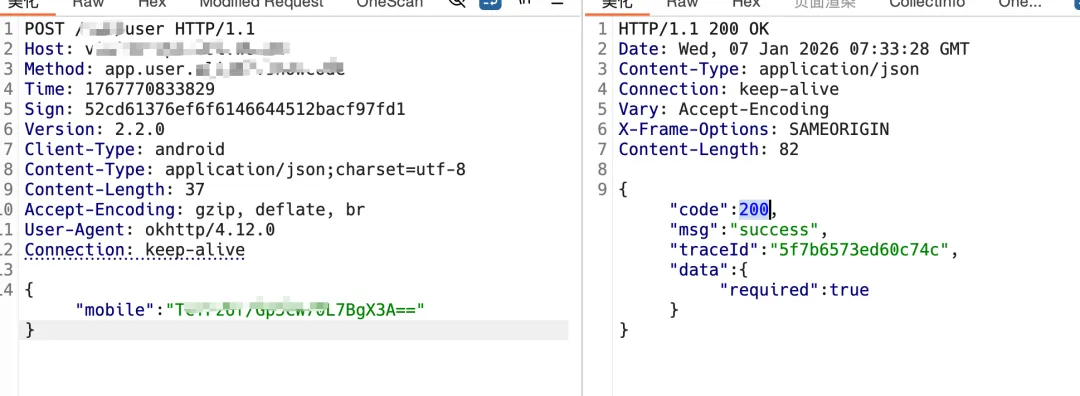
这是一个发送验证码操作的一个数据包,可以看到请求头做了相关验签操作,以及手机号是被加密的
目前我猜测的是Method Time Sign和请求体是有关联的 任何一个发生改变都会造成验签不通过 也就是老生常谈的防篡改
2.尝试手工寻找加密逻辑以及加密密钥
一般我喜欢用hooker这个工具先看看能不能hook到相关加解密密钥,以及看看从明文到密文的一个堆栈信息,工具地址如下,这是一个非常好用的工具
https://github.com/CreditTone/hooker?tab=readme-ov-file在发送验证码后抓包查看hook到的信息
从下图可以发现一处明文到密文的转变,以及相关的堆栈信息
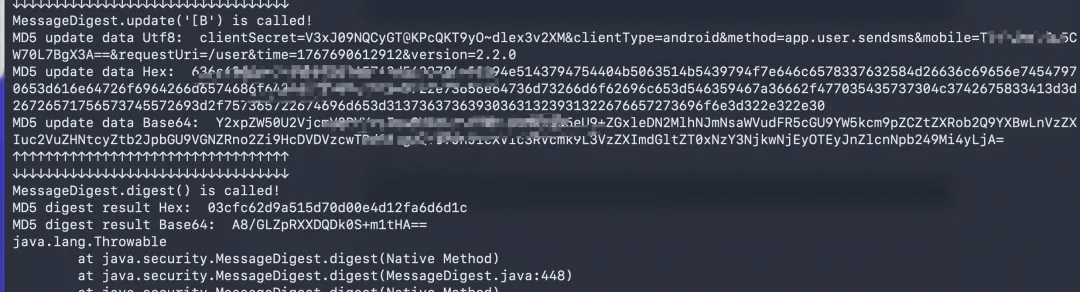
这里我并不清楚这个MessageDigest.update到底是什么作用,我只知道他生成的md5值与我数据包中的sign值相匹配
但是这个MessageDigest.digest方法应该就是将MessageDigest.update的结果md5加密的意思

sign的生成逻辑现在我们已经知道一半了,sign是由md5加密MessageDigest.update的结果生成的,但是MessageDigest.update这个方法的代码逻辑我们不清楚,这个问题先留着等会再看,先接着看看在发送验证码这一步,请求体加密的那一段的hook结果
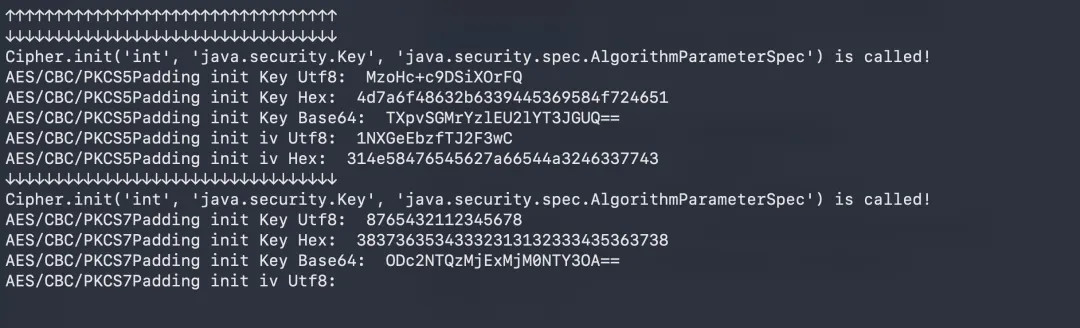
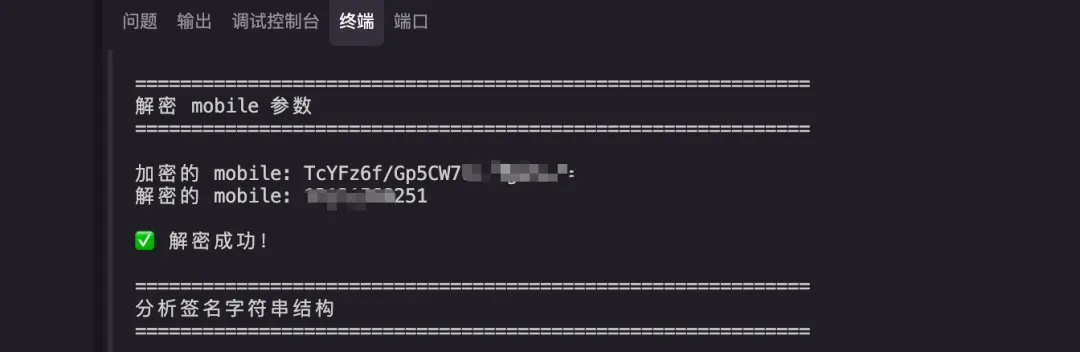
看到hook到两组密钥,不想动手叫ai写了个脚本验证了密钥是正确的
3.ida-pro-mcp初体验
此时可以说问题已经解决了三分之一,现在加密逻辑我已经知道了,sign生成的方式我也知道了,就是不知道被md5加密的这个值到底是怎么来的,因为不同接口,不同请求他被md5加密前的值是会变化的,最近刚好学习了各种mcp的一些手法,就想着试试用ida-pro-mcp去替我解决这个问题,相关的配置可以看看这篇文章
https://mp.weixin.qq.com/s/ey7oXVW0iUlmaCVRZnaH5A提示词可以分批完成,不要一口气把想干什么都告诉他,因为上下文有限,而且他不可能给我们一步到位,一步步来我们会知道问题出在哪里然后去纠正他(这里有点错别字)
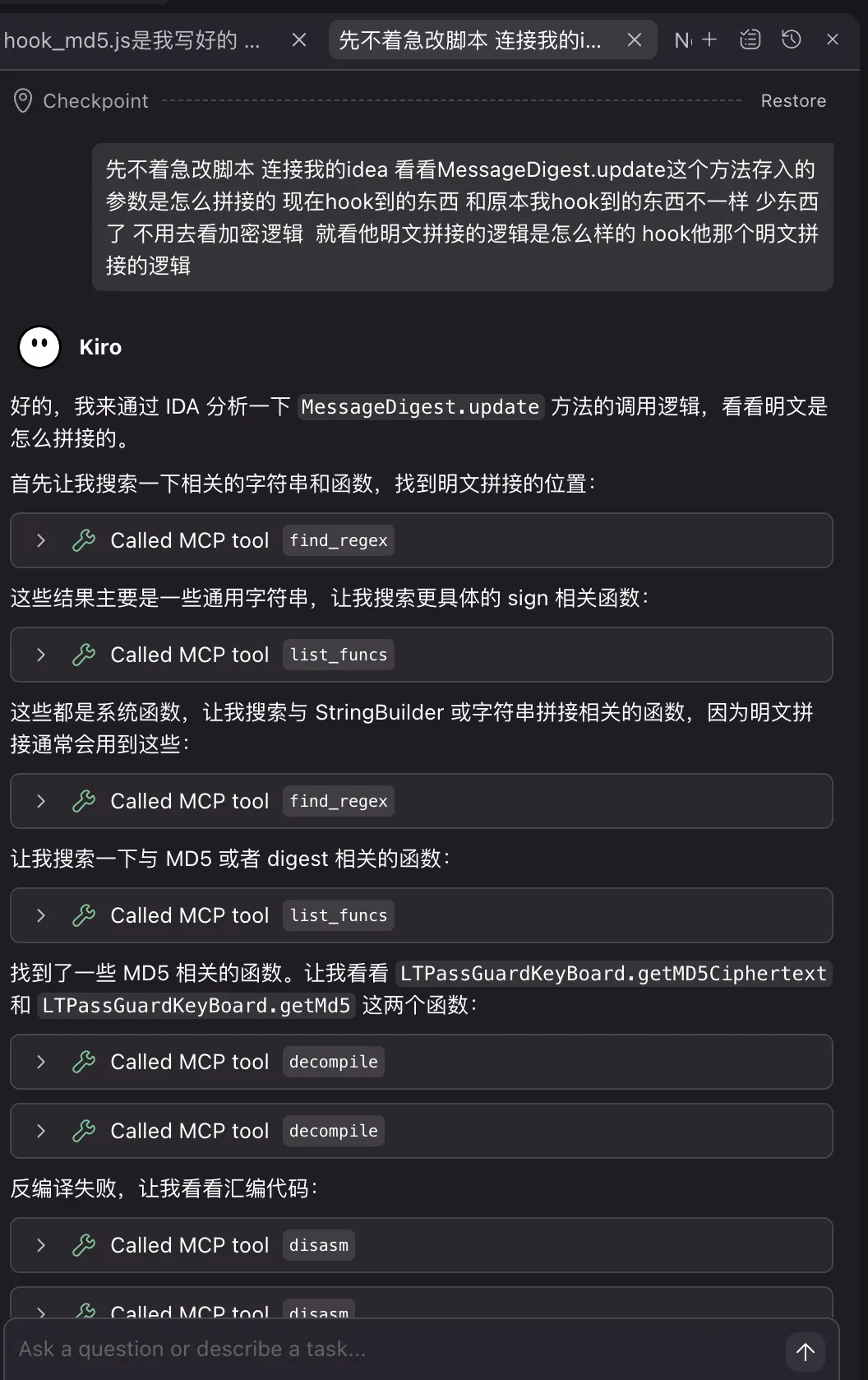
有点惊讶,图居然很快给了我一个答案,这个app是经过混淆的,人工去找得花不少功夫,下面是app脱壳后反编译的包名类名以及ai给我的回答结果
看到这个结果可能感觉已经找到一半了,但这时候我发现我的思路可能有点问题,我想去hook这个MessageDigest.update的值把他当成解密后的sign,但我完全没必要这么做,我不需要看到sign是什么东西,也不需要手动修改他,我只需要能修改请求体并绕过验签就行了
这时候观察了一下md5加密前的这一段字符串,发现其实是有迹可循的,有些东西是固定的,有些是请求头获取,有些是从请求体的json中提取进来的
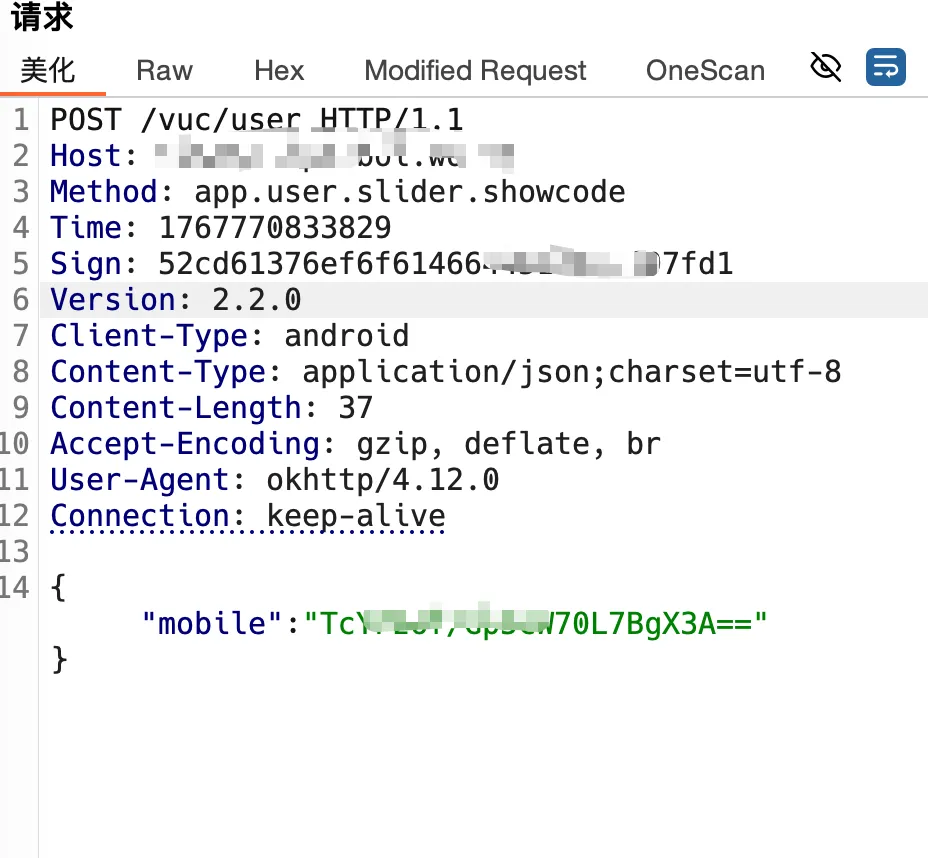

到这里我现在已经清楚了他整体的验签逻辑
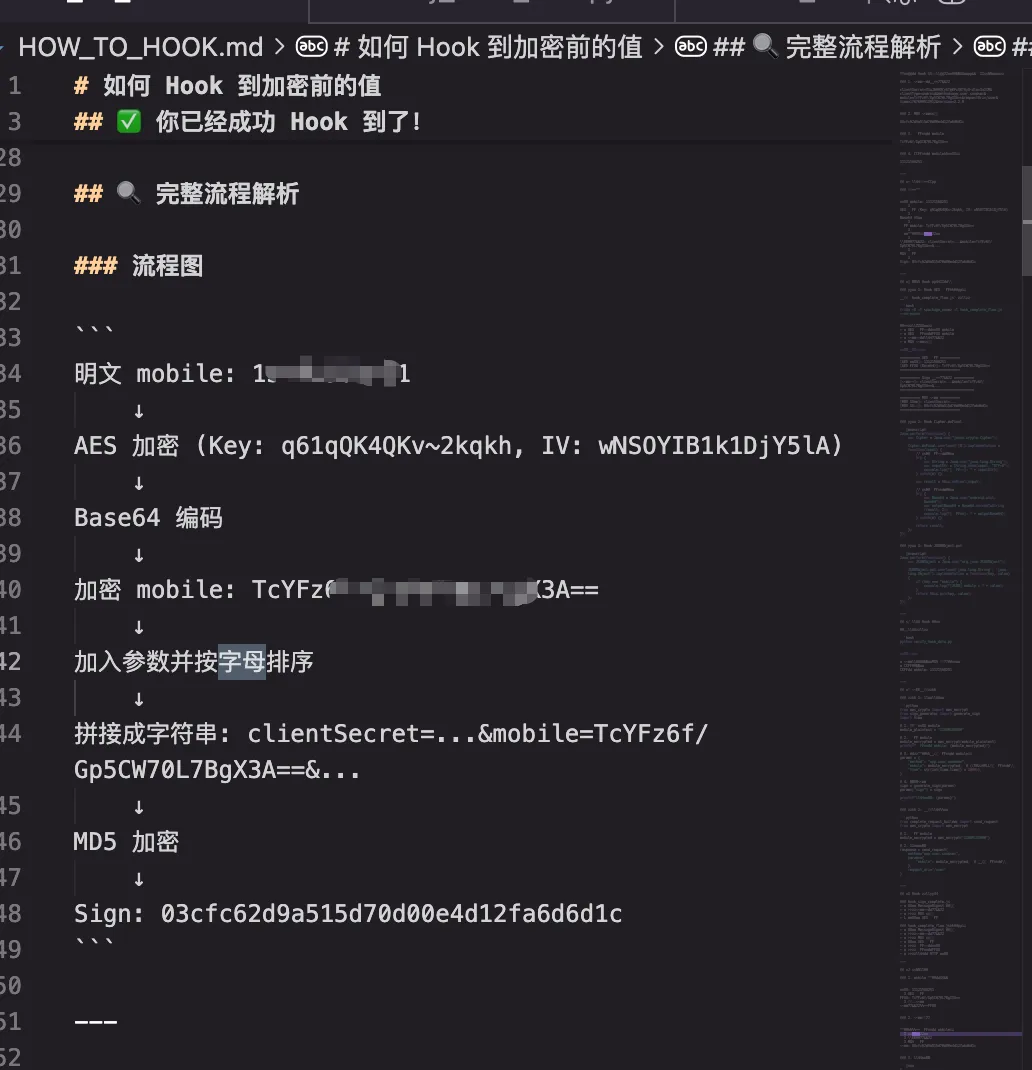
Method : 当前接口是对应类Time : 当前时间戳Sign : md5(clientSecret=固定的字符串&clientType=固定的手机型号&method=调用的类&mobile=从JSON请求体中循环取值并拼接后的字符串&requestUri=(请求路径 例如/vuc/user 去除/yuc)&time=时间戳&version=固定的请求头)Version: 版本号Client-Type:手机型号
这里还有一关键的问题,就是从JSON请求体中循环取值并拼接后的字符串,他并不是直接一个循环直接拼接过去的,我发现每个包拼接顺序和从json中直接提取数据拼接过去的字符串顺序不一样,这会影响到时候md5加密的值不同,导致验签失败
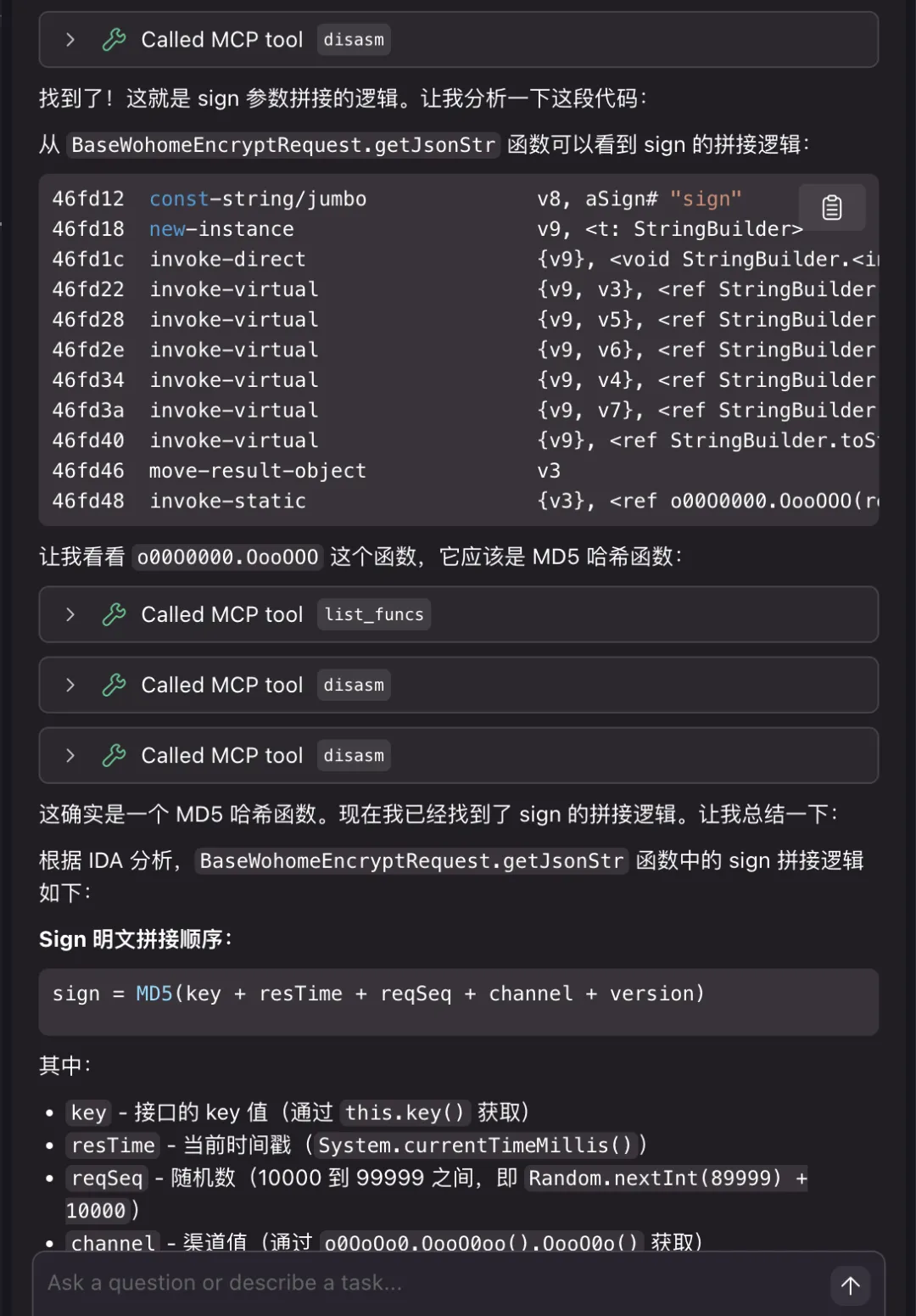
Sign : md5(clientSecret=固定的字符串&clientType=固定的手机型号&method=调用的类&mobile=从JSON请求体中循环取值并拼接后的字符串&requestUri=(请求路径 例如/vuc/user 去除/yuc)&time=时间戳&version=固定的请求头)这个问题,直接使用ida-mcp让它去给我找出来了这段拼接逻辑,他给出的结果是json中提取到的数据,按字母排序拼接,它给的说明文档如下所示
综上来看,我们渗透的时候一般只改变请求体,所以我们只需要把每次发包的请求体动态拼接成字符串然后md5加密,就能绕过这个验签了
4.flasktestheader.py&autodecrypt实现自动化绕过
接下来开始借助 AI 编写脚本,把之前做过的一些使用frida-rpc&flasktestheader.py&autodecrypt的脚本拉到工作区,让ai学习,参照我之前的例子对我本次要实现自动化加解密的需求重新改一份脚本,期间会出现一些问题,可以这些任务拆分成一些小任务,或者叫他打印日志,方便我们和ai分析问题出在哪,下面直接放图了
最终脚本如下:
# -*- coding:utf-8 -*-"""Sign 生成服务器 - 纯 Sign 生成版本配合 Burp autoDecoder 插件使用只负责生成 sign,不做任何加解密"""from flask import Flask, requestimport jsonimport hashlibimport re# ========== 配置参数 ==========# Sign 参数CLIENT_SECRET = "Vxxxxx3v2XM"CLIENT_TYPE = xxxxid"VERSION = "xxxx.0"URI_PREFIX = "/vxxx"FLASK_PORT = 8888app = Flask(__name__)# ========== HTTP 请求解析 ==========def parse_headers_string(headers_str):"""解析 autodecrypt 发送的 headers 字符串"""headers = {}path = ""lines = headers_str.replace("\r\n", "\n").split("\n")for i, line in enumerate(lines):if i == 0:parts = line.split(" ")if len(parts) >= 2:path = parts[1].split("?")[0]elif ": " in line:k, v = line.split(": ", 1)headers[k] = v.strip()return headers, pathdef build_sign(headers, path, body):"""构建 sign"""params = {"clientSecret": CLIENT_SECRET,"clientType": CLIENT_TYPE,"version": VERSION}# 提取 Method 和 Timefor k in ["Method", "method", "METHOD"]:if k in headers:params["method"] = headers[k]breakfor k in ["Time", "time", "TIME"]:if k in headers:params["time"] = headers[k]break# 提取 requestUriif path.startswith(URI_PREFIX):params["requestUri"] = path[len(URI_PREFIX):]else:params["requestUri"] = path# 从 body 提取参数(使用加密后的值)for k, v in body.items():if k != "sign" and v is not None:params[k] = str(v)# 按字母排序拼接plaintext = "&".join([f"{k}={params[k]}" for k in sorted(params.keys())])sign = hashlib.md5(plaintext.encode('utf-8')).hexdigest()print(f"[Sign明文] {plaintext}")print(f"[Sign] {sign}")return sign# ========== Flask 路由 ==========@app.route('/decode', methods=["POST"])def decode():"""解密接口 - 原样返回,不做任何处理"""body_str = request.form.get('dataBody', '')headers_str = request.form.get('dataHeaders', '')print(f"\n{'='*60}")print(f"[Decode 请求 - 原样返回]")print(f"{'='*60}\n")# 返回格式:headers + 4个\r\n + bodyif headers_str:headers_clean = headers_str.strip()headers_clean = headers_clean.replace('\r\n', '\n').replace('\n', '\r\n')return headers_clean + "\r\n\r\n\r\n\r\n" + body_strreturn body_str@app.route('/encode', methods=["POST"])def encode():"""加密接口 - 只生成 sign,不做任何加解密"""body_str = request.form.get('dataBody', '')headers_str = request.form.get('dataHeaders', '')print(f"\n{'='*60}")print(f"[Sign 生成请求]")if not headers_str:print("[错误] 没有 headers")return body_strheaders, path = parse_headers_string(headers_str)print(f"[路径] {path}")print(f"[Method] {headers.get('Method', 'N/A')}")print(f"[Time] {headers.get('Time', 'N/A')}")body = {}if body_str.strip():try:body = json.loads(body_str.strip())print(f"[Body] {body}")except Exception as e:print(f"[错误] {e}")# 生成新 signnew_sign = build_sign(headers, path, body)# 替换 Signsign_pattern = re.compile(r'(Sign:\s*)([^\r\n]+)', re.IGNORECASE)if sign_pattern.search(headers_str):new_headers = sign_pattern.sub(f'\\g<1>{new_sign}', headers_str)else:new_headers = headers_str.rstrip() + f"\r\nSign: {new_sign}"print(f"[新Sign] {new_sign}")print(f"{'='*60}\n")# 返回格式:headers + 4个\r\n + bodynew_headers_clean = new_headers.strip()new_headers_clean = new_headers_clean.replace('\r\n', '\n').replace('\n', '\r\n')return new_headers_clean + "\r\n\r\n\r\n\r\n" + body_str@app.route('/test', methods=["GET"])def test():"""测试接口"""return json.dumps({"status": "ok","message": "Sign 生成服务器运行中","version": "4.0 - 纯 Sign 生成版","endpoints": {"/encode": "生成 sign(不做加解密)","/decode": "原样返回(不做加解密)","/test": "测试接口"},"config": {"client_secret": CLIENT_SECRET[:10] + "..."}}, ensure_ascii=False, indent=2)if __name__ == '__main__':print("=" * 60)print("Sign 生成服务器 - 纯 Sign 生成版")print("=" * 60)print(f"端口: {FLASK_PORT}")print(f"接口:")print(f" /encode - 生成 sign(不做加解密)")print(f" /decode - 原样返回(不做加解密)")print(f" /test - 测试接口")print()print("说明:")print(" - 服务器只负责生成 sign")print(" - 不做任何 AES 加解密")print(" - 加解密由 Burp 插件或其他工具完成")print("=" * 60)app.run(host="0.0.0.0", port=FLASK_PORT, debug=False)
5.最终效果展示
至此,脚本就算是写好了,看看最终效果吧
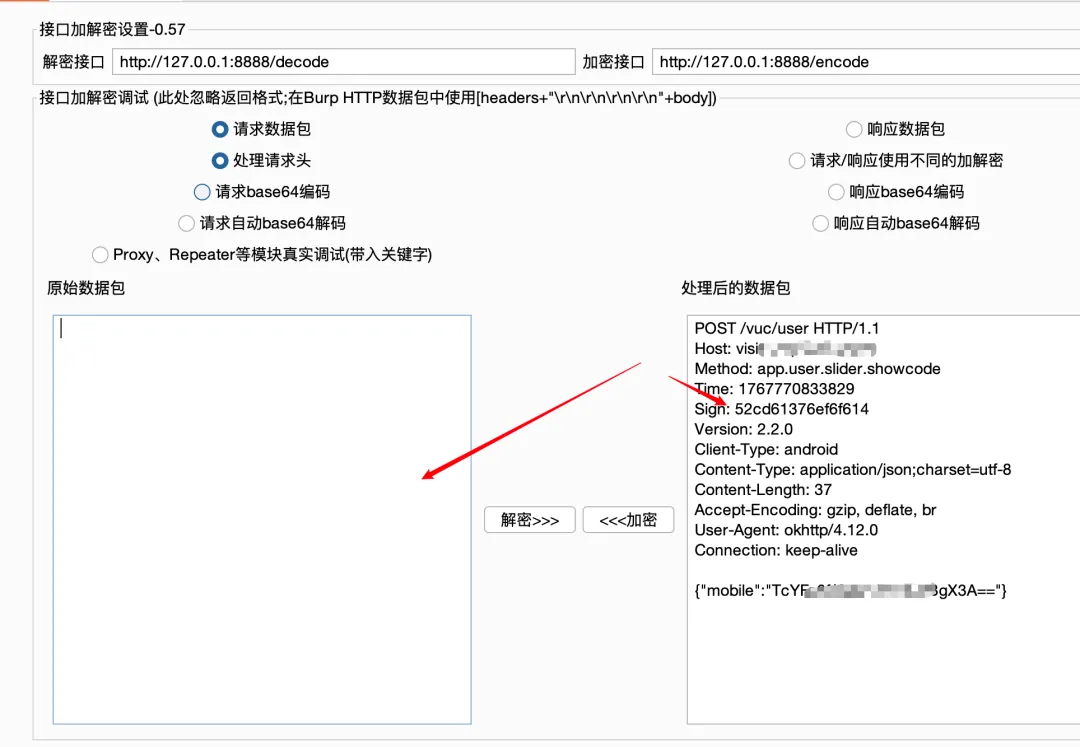
此时发包,已经绕过了验签,后续只需要开启autodecrypt中burp各模块的开关,就可以实现全自动的绕过验签
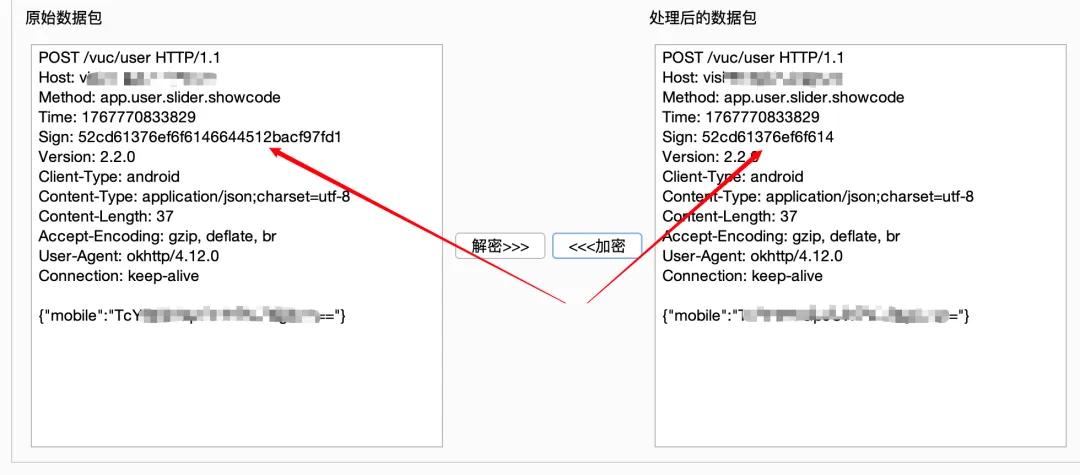
到结束,其实还有一步没有做,就是请求体的自动化加解密,因为我发现很多包的请求体没有使用aes加密,就直接生成了一个加密后的字典fuzz了一波,没有做成自动化加解密
感慨一下AI的强大,这个案例虽然不是特别难,但我真的一行代码没写,反编译后的东西我看到混淆了就不想动了,最后居然一行代码都不写就绕过了一个原本不算简单的问题.
