 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:消息结构里藏着的秘密
↑阅读之前记得关注+星标⭐️,😄,每天才能第一时间接收到更新
「Claude Code 源码揭秘」系列的第二篇,上一篇聊了 Agent 循环的细节,但那个循环操作的核心数据结构是什么?是消息数组。每一条用户输入、模型回复、工具请求、工具结果,全部通过这个数组流转。
今天拆解一下这个消息结构。有个设计让我第一次看到的时候愣了一下——工具结果居然是伪装成用户消息发的。
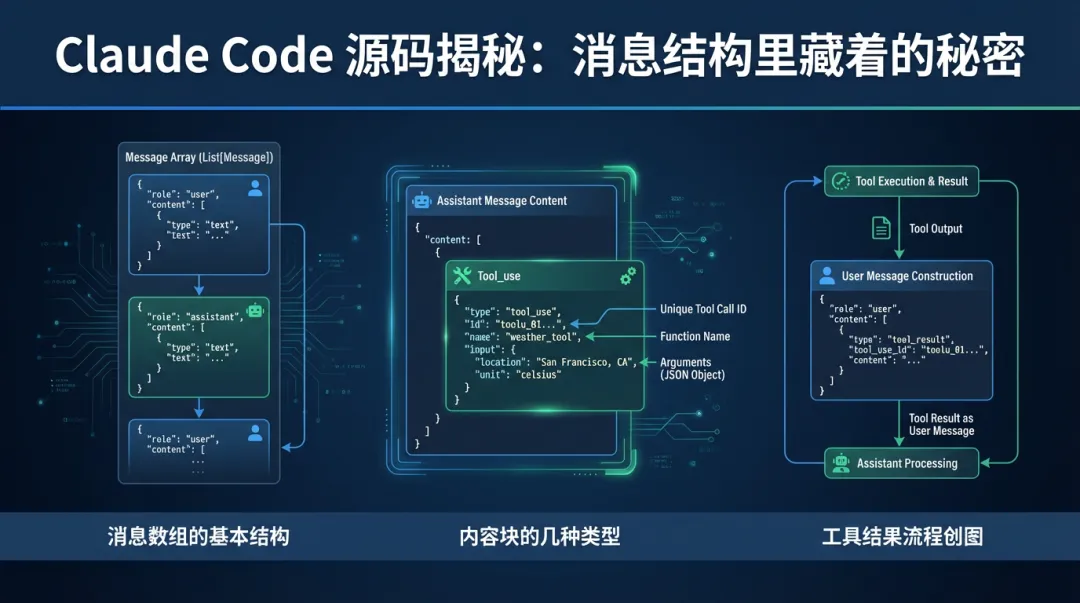
消息数组的基本结构
Claude Code 的对话状态就是一个消息对象数组,遵循 Anthropic Messages API 的格式。每条消息有两个关键字段:role(角色,只有 user 和 assistant 两种)和 content(内容,可以是字符串或内容块数组)。
messages = [ { role: "user", content: "..." }, { role: "assistant", content: [...] }, { role: "user", content: [...] }, { role: "assistant", content: [...] }]有一条死规矩:角色必须交替。用户消息后面必须是助手消息,助手消息后面必须是用户消息。这个约束影响了整个工具结果的处理方式。
内容块的几种类型
content 字段可以包含不同类型的内容块。
文本块——最简单的,两种角色都能用:
{ "type": "text", "text": "src 目录里有什么文件?"}工具调用块——只有 assistant 角色能发。模型想用工具的时候,就发这个:
{ "type": "tool_use", "id": "toolu_01ABC123", "name": "Read", "input": { "file_path": "/project/package.json" }}三个关键字段:id 是这次工具调用的唯一标识,name 是工具名称,input 是工具参数。
工具结果块——这里有意思了。工具结果是作为 user 消息发的,不是什么特殊角色:
{ "type": "tool_result", "tool_use_id": "toolu_01ABC123", "content": " 1\t{\n 2\t \"name\": \"my-project\",\n 3\t \"version\": \"2.0.0\"\n 4\t}", "is_error":false}tool_use_id 必须跟对应的 tool_use 块的 id 匹配。is_error 标记工具是否执行失败——这个字段很关键,后面会说。
图片块——只有 user 角色能发,用来附加图片:
{ "type": "image", "source": { "type": "base64", "media_type": "image/png", "data": "iVBORw0KGgoAAAANSUhEUg..." }}工具结果伪装成用户消息——这个设计挺巧妙
这是最容易让人困惑的地方:没有 tool 角色。工具输出被格式化成包含 tool_result 块的用户消息。
为什么这么设计?
因为角色必须严格交替。模型发了 tool_use 请求,按规矩下一条必须是 user 消息。工具结果正好可以”借用”这个位置。
更深层的原因是,模型需要把工具输出当成普通输入来处理。用用户消息的形式发送,对话就能保持严格的交替模式,模型把工具输出当成新信息来推理。
user: "package.json 里版本号是多少?"assistant: [tool_use: Read package.json] ← 模型请求工具user: [tool_result: 文件内容] ← CLI 把结果当用户消息发回去assistant: "版本号是 2.1.0" ← 模型回复我第一次看到这个设计的时候觉得有点”取巧”,但仔细想想,确实是最简洁的方案。不用引入新角色,不用改 API 规范,利用现有的交替规则就把问题解决了。
一个完整的对话示例
来看一个真实的多轮对话长什么样。
第一轮:用户提问
{ "role": "user", "content": "package.json 里的版本号是多少?"}第二轮:助手调用 Read 工具
{ "role": "assistant", "content": [ { "type": "text", "text": "我来读一下 package.json 文件。" }, { "type": "tool_use", "id": "toolu_01Read", "name": "Read", "input": { "file_path": "package.json" } } ], "stop_reason": "tool_use"}第三轮:工具结果(作为用户消息)
注意 Read 工具的输出带行号:
{ "role": "user", "content": [ { "type": "tool_result", "tool_use_id": "toolu_01Read", "content": " 1\t{\n 2\t \"name\": \"my-project\",\n 3\t \"version\": \"2.1.0\",\n 4\t \"description\": \"A sample project\"\n 5\t}" } ]}第四轮:助手最终回复
{ "role": "assistant", "content": [ { "type": "text", "text": "package.json 里的版本号是 2.1.0。" } ], "stop_reason": "end_turn"}一个简单的问题,四条消息。这也是为什么工具调用多的任务会快速消耗上下文窗口。
一次调用多个工具
助手可以在一条消息里请求多个工具:
{ "role": "assistant", "content": [ { "type": "text", "text": "我来搜索 TypeScript 文件并查找 TODO 注释。" }, { "type": "tool_use", "id": "toolu_01Glob", "name": "Glob", "input": { "pattern": "**/*.ts" } }, { "type": "tool_use", "id": "toolu_02Grep", "name": "Grep", "input": { "pattern": "TODO", "path": "src/" } } ], "stop_reason": "tool_use"}对应的工具结果也打包在一条用户消息里:
{ "role": "user", "content": [ { "type": "tool_result", "tool_use_id": "toolu_01Glob", "content": "src/index.ts\nsrc/utils.ts\nsrc/types.ts" }, { "type": "tool_result", "tool_use_id": "toolu_02Grep", "content": "src/index.ts:45: // TODO: refactor this" } ]}多个 tool_use 对应多个 tool_result,通过 id 匹配。清晰明了。
工具失败的处理
工具执行失败怎么办?用 is_error 标记:
{ "role": "user", "content": [ { "type": "tool_result", "tool_use_id": "toolu_01Edit", "content": "Error: old_string not found in file. The content may have changed.", "is_error":true } ]}模型看到这个错误,可以决定重新读文件、换个方法试、或者把失败情况告诉用户。
这个设计比硬编码异常处理灵活多了。不是代码来决定”文件读取失败后该干嘛”,而是让模型自己判断。上一篇也提到过这个思路。
System Prompt 不在消息数组里
还有个容易搞混的点:系统提示词不是消息数组的一部分,而是单独的参数:
await anthropic.messages.create({ model: "claude-sonnet-4-20250514", system: systemPrompt, // 单独的参数 messages: messages, // 对话历史 tools: toolDefinitions, stream: true});系统提示词包含身份指令、环境信息(工作目录、平台、日期)、CLAUDE.md 内容、工具使用指南、行为约束等。它保持不变,而消息数组随着交互不断增长。
消息验证规则
API 有严格的校验:
-
• 角色必须交替:user 和 assistant 必须轮流 -
• 第一条必须是 user:对话必须由用户发起 -
• tool_use_id 必须匹配:每个 tool_result 的 tool_use_id 必须对应前面某个 tool_use 的 id -
• 内容不能为空:消息不能有空的 content 数组 -
• JSON 必须合法:工具输入必须是有效的 JSON
违反这些规则会直接报 API 错误。
Token 消耗
不同内容类型消耗 token 不一样:
-
• 文本块:按普通文本分词 -
• 工具调用块:输入 JSON 分词,加大约 20 token 开销 -
• 工具结果块:内容按文本分词,加大约 10 token 开销 -
• 图片块:根据图片尺寸计算
一次工具调用循环就增加两条消息(助手请求 + 用户结果),这就是为什么工具调用多的对话会快速吃掉上下文。后面专门聊上下文管理的时候会深入讲这个问题。
理解了消息结构,很多之前觉得奇怪的行为就能解释了。比如为什么有时候模型会”忘记”之前读过的文件——可能是老消息被压缩掉了。比如为什么多轮对话越来越慢——消息数组越来越大,每次 API 调用都要发完整历史。
下一篇聊工具执行流程——从权限检查到结果格式化,工具调用经过了哪些环节。
本文基于 Claude Code 2.0.76 版本源码分析。
最后记得⭐️我,每天都在更新:欢迎点赞转发推荐评论,别忘了关注我

