你的App是怎么被检测到违规的?起底:“全国App技术检测平台”的自动化审查逻辑
2026年01月10日国家网信办就《互联网应用程序个人信息收集使用规定(征求意见稿)》公开征求意见,大家都知道,我国的法律并不是发布以后才开始执行,而是已经有了成熟的执法框架以后才发布正式文件。说明,国家在技术层面已经全面构建了一套自动化监管体系。
为了解决App多,但监测技术人员少的局面, 监管部门依托中国信通院(CAICT)与国家互联网应急中心(CNCERT),构建了一套全天候、全自动的合规探测体系。 App合规已从“人工抽查”时代全面进入“以网管网”的自动化监管时代。
作为开发者或法务,如果你还停留在“文案合规”层面,无异于裸奔。本文将结合技术实现细节,拆解监管系统探测违规的核心逻辑。
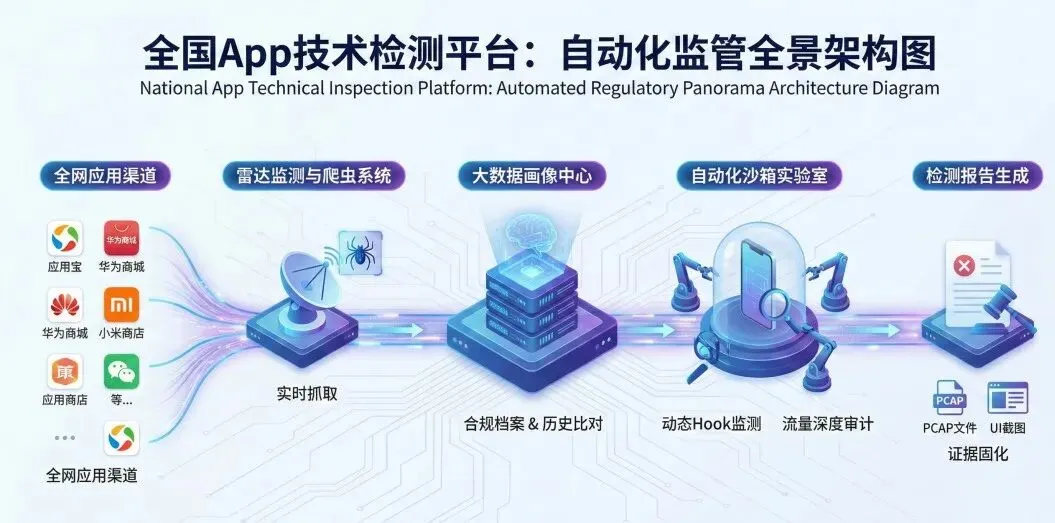
监管体系并非单一工具,而是一个庞大的自动化生态。监管的第一步是“看见”。全网监测系统通过爬虫技术,持续扫描各大主流应用商店(如华为、小米、应用宝等)及第三方下载站,实时抓取新上架或版本更新的App安装包(APK/IPA)。系统会自动解析App的元数据(版本号、开发者信息、权限列表),并将其纳入监管数据库。一旦发现高风险特征或接到专项整治指令,任务管理系统会将检测任务分发至下游的第三方检测机构(如泰尔终端实验室、中国电子技术标准化研究院等)
-
全网雷达: 爬虫系统实时监控主流渠道,新包上架即入库。
-
合规档案(信用机制): “大数据画像中心”记录了App的所有历史违规记录。 “屡教不改” (即上个版本刚整改,新版本又出现同样特征代码)会被系统自动标记为红色预警。
-
证据固化: 自动化测试系统在发现违规的瞬间,会自动截取UI画面、保存流量包(PCAP)及代码堆栈日志,形成 不可抵赖 的法律证据链。
静态代码分析(SAST)是检测的第一道防线。它最令企业头疼的逻辑在于“不一致性校验”。
得益于现在llm的日趋成熟成熟,监管系统充分利用NLP(自然语言处理)提取隐私政策中的相关描述,再结合解包反编译以后的配置资源文件进行对比分析。
比如关于“通讯录”的描述,同时通过静态扫描提取 AndroidManifest.xml 中的权限。
XML<uses-permission android:name="android.permission.READ_CONTACTS" /> <uses-permissionandroid:name="android.permission.ACCESS_FINE_LOCATION" /> ```### 1.2 示范代码:SDK硬编码指纹识别```java// 监管通过扫描包名识别第三方SDK (例如:某广告SDK)// 即便主程序未调用,只要包内含有该SDK的特征码,即视为集成import com.bad.ad.sdk.AdManager; public void initSDK() { // 监管扫描发现:使用了已知存在静默上传漏洞的旧版SDK (v1.0.2) AdManager.init(context, "app_key_001"); }
技术红线 :一旦发现代码申请了 READ_CONTACTS 但在文案中未提及,或者虽然提及但无实际功能支撑,系统会立即标记为“超范围收集”。
很多App开发者认为“那是第三方SDK收集的,我不知道”。但在检测工具眼中,SDK的包名、类名及特定的代码结构拥有独特的“指纹”。
技术视角 :监管实验室建立了庞大的SDK指纹库。如果App集成了带有静默上传行为的旧版SDK,检测系统会基于“开发者负有管理责任”的法律原则,直接将SDK的违规视同App违规。
如果说静态分析是“查户口”,那么动态行为监测(DAST)就是“装监控”。监管实验室通过在定制的沙箱中运行App,利用Frida等工具对底层API进行Hook。 当App在沙箱中运行时,一旦调用了敏感API(如获取定位、读取IMEI、访问剪切板),Hook程序会立即拦截该调用,并记录以下信息:
这是目前最核心的取证手段。它不仅记录App调用了什么,还记录了调用的上下文状态 。
// 这是一个模拟监管行为监测的逻辑片段// 它能精准捕捉:用户在点击“同意”按钮前,App是否已经偷跑了数据?Java.perform(function () { var TelephonyManager = Java.use("android.telephony.TelephonyManager"); // Hook 获取设备识别码的接口 TelephonyManager.getDeviceId.overload().implementation = function () { var isAgreed = checkUserConsent(); // 系统自动检查当前的UI状态 if(!isAgreed) { // 证据固化:记录时间、调用堆栈、当前屏幕截图 sendViolationEvidence({ type: "PRE_CONSENT_COLLECTION", api: "getDeviceId", stackTrace: getStackTrace(), timestamp: Date.now() }); } return this.getDeviceId(); };});
四、HTTPS流量深度审计(MITM):透视数据外泄
为了验证数据是否进行了脱敏,监管系统会在沙箱中实施中间人攻击(MITM),强制解密HTTPS流量,检查请求体(Request Body)中的明文信息。
系统会对解密后的HTTP Request Body进行正则匹配。如果发现传输的JSON或XML数据中包含了用户的明文身份证号、位置坐标或设备指纹,且这些数据未进行去标识化处理,或者传输的目的地与隐私政策声明的第三方域名不符,即构成违规。
针对“频繁收集”的认定,系统会统计特定API调用或数据包发送的频率。例如,工信部通报中常见的案例是“每隔5分钟读取一次位置信息”,而此时App处于后台且无导航功能运行。这种行为通过流量日志的时间戳分析一目了然
基于mitmproxy的内容审查,以下逻辑展示了监管系统如何从加密流量中识别出明文传输的个人敏感信息。
# 监管侧流量审计脚本片段 (Python/mitmproxy)from mitmproxy import httpimport redef request(flow: http.HTTPFlow) -> None: # 自动识别传输的目的地是否为隐私政策中声明的第三方域名 target_url = flow.request.pretty_url # 对解密后的Payload进行正则扫描 # 扫描是否包含明文手机号、身份证号、IMEI等 id_card_pattern = r"\d{17}[\d|x|X]" body_content = flow.request.get_text() if re.search(id_card_pattern, body_content): print(f"[!] 告警:在域名 {target_url} 的请求中发现明文身份证号传输") # 自动保存该数据包作为后续行政执法的PCAP证据 save_evidence(flow)
五、自动化UI遍历:识别“高频骚扰”与“强制索权”
监管利用自动化脚本(类似Monkey Test)遍历App的所有界面,验证交互逻辑是否违反T/TAF标准。
# 监管自动化脚本片段def test_permission_refusal_logic(): # 1. 触发权限弹窗并点击“拒绝” driver.find_element_by_id("permission_deny_btn").click() # 2. 检查App是否立即退出 (判定为:不给权限不让用) if is_app_crashed_or_exited(): log_violation("FORCED_AUTHORIZATION") # 3. 再次启动并检查是否在48小时内重复弹出同一权限请求 # 符合 T/TAF 078.4 判定标准
六、 规则的底层逻辑:T/TAF标准的演进到《规定征求意见稿》的完善
在征求意见稿出台之前,检测技术的逻辑基础是细化的行业标准,其中 T/TAF系列标准 是所有自动化检测脚本的“算法原型”,例如:
T/TAF 078.1(最小必要):这是判定“超范围收集”的量尺,详细规定了不同场景的收集上限。
T/TAF 078.3(收集行为):定义了“静默状态”和“高频收集”的技术阈值例如:后台定位频率不得高于XX分钟/次。
T/TAF 078.4(权限交互):针对“强制索权”和“频繁骚扰”的自动化判定逻辑,明确了“强制索权”、“捆绑授权”的自动化判定流程。
相信在《规定》正式发布以后,将会有了行政法规级别的依据,执法将会日趋规范。
在上述技术体系的穿透下,要实实在在做合规工作必须实现“技术语境”与“法律语境”的精准对接。
证据排查:当收到通报时,我们需要通过代码堆栈定位到究竟是哪个SDK在什么场景下调用的API,从而给出精准的法律抗辩或整改策略。
合同闭环:基于对SDK指纹识别逻辑的了解,在采购第三方技术服务时,应在合同中明确SDK违规引发的法律责任归属及技术约束条款。
全生命周期合规:从产品原型阶段(UI遍历逻辑)到上线运行阶段(API调用频率限制),建立一套动态的、可对标T/TAF标准以及新《规定》的防御体系。
作者简介: 本文作者拥有法学专业背景及5年软件开发实战经验(曾任技术总监)。致力于通过“技术实战+法律穿透”的双重能力,为数字化企业提供不仅仅停留在纸面上的数据合规服务。
 夜雨聆风
夜雨聆风