 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:SSE 事件序列 + Session State,Agent 的血液循环系统
↑阅读之前记得关注+星标⭐️,😄,每天才能第一时间接收到更新
「Claude Code 源码揭秘」系列的第五篇,上一篇《Claude Code 源码揭秘:AI 一行 rm -rf / 你就完了,15 道安全防线怎么拦》说的是命令执行之前要过多少道检查。但有个更基础的问题还没展开讲:数据是怎么从 API 流到 CLI 的?
第一篇聊核心循环的时候提了一嘴 SSE(Server-Sent Events),说响应是”一点点流过来的”。但当时没展开讲细节——事件序列是怎样的?工具参数为什么要”攒着”才能解析?用户按 Escape 的时候流是怎么断掉的?
还有个更隐蔽的问题:Claude Code 跑着跑着,状态栏上的费用数字在跳动,当前用的什么模型、花了多少钱、跑了多久——这些信息存在哪里?谁在更新它们?
这一篇补上这两块:SSE 流处理和Session State 管理。听起来是两个独立的话题,但其实紧密相关——SSE 是数据流入的管道,Session State 是数据落地的仓库。理解了这两块,再看核心循环的代码就会更清晰。
先说 SSE 流处理。
你用 Claude Code 的时候,模型的回复是一个字一个字蹦出来的,不是等半天然后”啪”一下全出来。这不是为了好看,而是有实际意义的设计。
流式响应有三个好处:
第一,用户体验好。能看到模型在”思考”,不用干等。
第二,支持取消。用户按 Escape,流可以立刻中断。如果是传统的请求-响应模式,你得等完整响应回来才能说”我不要了”。
第三,早失败早知道。如果模型一开始就跑偏了,用户能及时打断,不用等它生成完一大堆废话。
实现流式响应用的是 SSE 协议。这是个很老的技术了,HTTP 长连接,服务器往客户端单向推数据。比 WebSocket 简单,够用就行。
翻 src/streaming/sse.ts,Claude Code 实现了一套完整的 SSE 解析器。核心是两个类:NewlineDecoder 处理字节级的换行,SSEDecoder 处理事件协议。
export class SSEDecoder { private eventType: string | null = null; private dataLines: string[] = []; private chunks: string[] = []; decode(line: string): SSEEvent | null { // 空行意味着一个事件结束 if (!line) { if (this.dataLines.length === 0) { return null; } const event: SSEEvent = { event: this.eventType, data: this.dataLines.join('\n'), raw: this.chunks, }; // 重置状态,准备下一个事件 this.eventType = null; this.dataLines = []; this.chunks = []; return event; } // 解析 event: 和 data: 字段 if (line.startsWith('event:')) { this.eventType = line.slice(6).trim(); } else if (line.startsWith('data:')) { this.dataLines.push(line.slice(5).trim()); } this.chunks.push(line); return null; }}为什么要分两层?因为网络数据是按字节块到达的,一个事件可能跨多个块,一个块也可能包含多个事件。NewlineDecoder 先把字节流切成行,SSEDecoder 再把行组装成事件。分层处理,逻辑清晰。
事件序列是固定的,理解这个很重要。
每个 API 响应都遵循同样的模式:
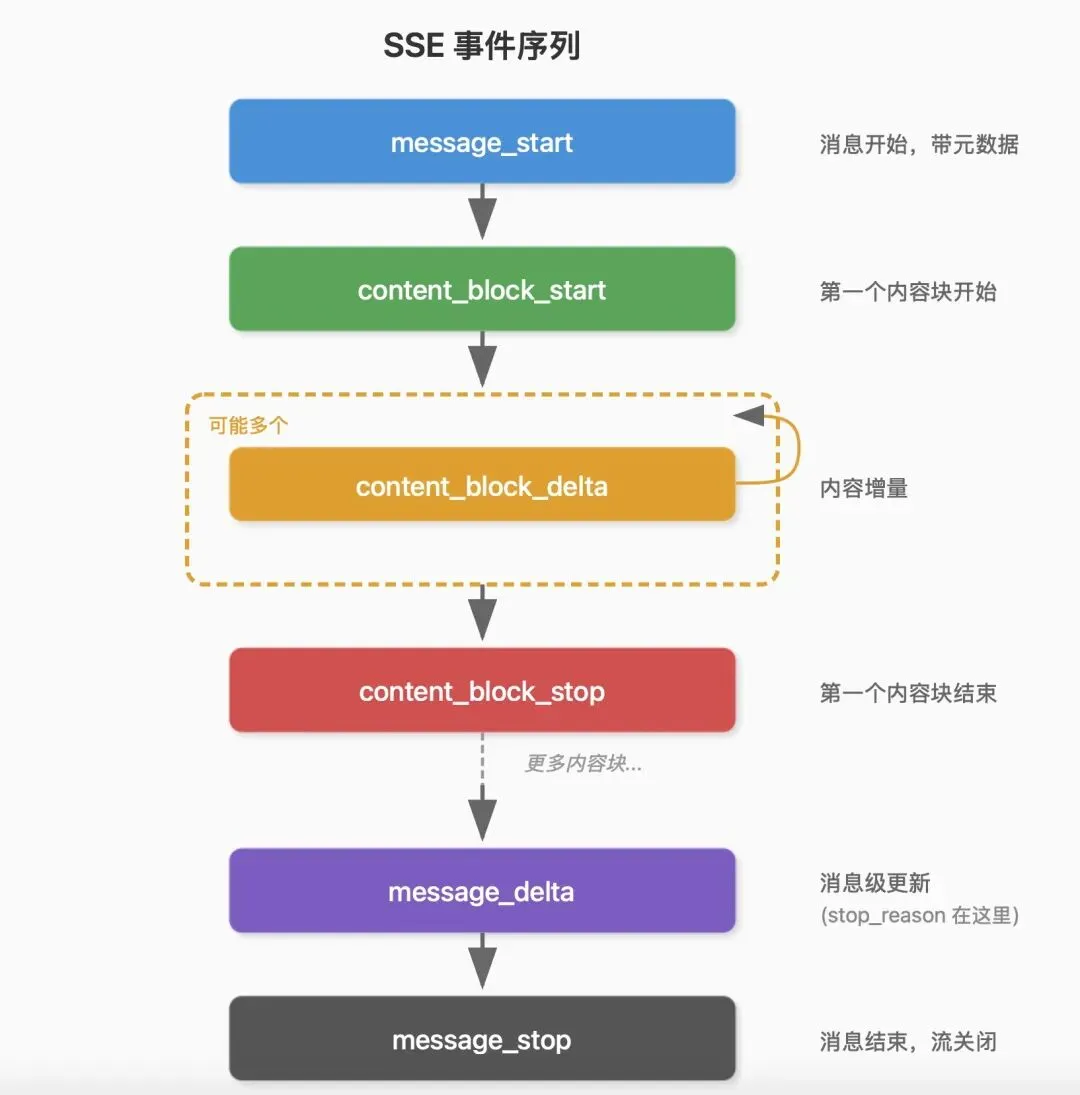
message_start 是开场白,告诉你消息 ID、模型名称、输入 token 数:
{ type: "message_start", message: { id: "msg_01ABC123", role: "assistant", model: "claude-sonnet-4-20250514", usage: { input_tokens: 1500, output_tokens: 0 } }}content_block_start 告诉你一个内容块要开始了,可能是文本,也可能是工具调用:
// 文本块{ type: "content_block_start", index: 0, content_block: { type: "text" } }// 工具调用块{ type: "content_block_start", index: 1, content_block: { type: "tool_use", id: "toolu_01DEF", name: "Read"}}content_block_delta 是真正的内容,一点一点到达:
// 文本增量{ type: "content_block_delta", index: 0, delta: { type: "text_delta", text: "我来" } }{ type: "content_block_delta", index: 0, delta: { type: "text_delta", text: "看看" } }// 工具参数增量(JSON 是分片的!){ type: "content_block_delta", index: 1, delta: { type: "input_json_delta", partial_json: '{"file_' } }{ type: "content_block_delta", index: 1, delta: { type: "input_json_delta", partial_json: 'path":"' } }{ type: "content_block_delta", index: 1, delta: { type: "input_json_delta", partial_json: '/src/index.ts"}' } }这里有个关键细节:工具参数的 JSON 是分片到达的。
你看上面那个例子,{"file_path":"/src/index.ts"} 被切成了三片。CLI 不能收到第一片就去解析,会报语法错误。必须一直攒着,等 content_block_stop 信号来了,才能把完整的 JSON 拼起来解析。
let jsonString = "";for await (const event of stream) { if (event.type === "content_block_delta" && event.delta.type === "input_json_delta") { // 攒着,不能解析 jsonString += event.delta.partial_json; } if (event.type === "content_block_stop") { // 现在可以解析了 const toolInput = JSON.parse(jsonString); // { file_path: "/src/index.ts" } }}这解释了为什么工具不能立即执行——必须等完整的参数到达。文本可以边收边渲染,工具调用不行。
message_delta 带来消息级的更新,最重要的是 stop_reason:
{ type: "message_delta", delta: { stop_reason: "tool_use" }, usage: { output_tokens: 150 }}stop_reason 决定核心循环下一步干什么。tool_use 意味着要执行工具然后继续;end_turn 意味着模型说完了,等用户输入。
我之前做实时数据推送的时候也用过类似的事件序列设计。数据不是一坨扔过来,而是有明确的开始、内容、结束信号。这样接收端能知道自己处于什么状态,出错了也好定位。
流式处理最有意思的是取消机制。
用户按 Escape 的时候,你不希望干等模型说完。Claude Code 用 AbortController 实现取消:
const controller = new AbortController();// 监听用户中断process.on('SIGINT', () => { controller.abort();});// 传给 API 调用const stream = await anthropic.messages.create({ model: "claude-sonnet-4-20250514", messages: messages, stream: true, signal: controller.signal // ← 关键});try { for await (const event of stream) { processEvent(event); }} catch (error) { if (error.name === "AbortError") { // 用户取消,优雅退出 return { cancelled: true }; } throw error;}AbortController 是浏览器 API 后来被 Node.js 采纳的,专门用来取消异步操作。调用 abort() 之后,所有关联的请求都会立刻中断,抛出 AbortError。
src/streaming/message-stream.ts 里的 EnhancedMessageStream 类把这套机制封装得更完善,还加了心跳检测:
export class EnhancedMessageStream extends EventEmitter { private abortController: AbortController; private lastActivityTime: number = Date.now(); private heartbeatInterval: NodeJS.Timeout | null = null; private setupHeartbeat(): void { const HEARTBEAT_INTERVAL = 5000; // 5秒检测一次 const HEARTBEAT_TIMEOUT = 30000; // 30秒无活动则超时 this.heartbeatInterval = setInterval(() => { const timeSinceActivity = Date.now() - this.lastActivityTime; if (timeSinceActivity > HEARTBEAT_TIMEOUT) { const error = new Error('Stream heartbeat timeout'); this.handleError(error); return; } }, HEARTBEAT_INTERVAL); } abort(): void { if (this.aborted || this.ended) return; this.aborted = true; this.abortController.abort(); this.cleanup(); }}心跳检测是为了处理一种边缘情况:网络连接还在,但服务器卡住了不发数据。30 秒没收到任何事件,就认为流挂了,主动断开。
这些细节在”正常情况”下感知不到,但在生产环境里太重要了。网络不稳定、服务器过载、用户中途关掉终端… 各种情况都要处理好。
错误重试是另一个关键机制。
API 调用会失败,这是事实。Claude Code 把错误分成”可重试”和”不可重试”两类:
const RETRYABLE_ERRORS = [ 'overloaded_error', // 服务过载 'rate_limit_error', // 限流 'api_error', // 通用 API 错误 'timeout', // 超时 'ECONNRESET', // 连接重置 'ETIMEDOUT', // 连接超时];const RETRYABLE_STATUS_CODES = [408, 429, 500, 502, 503, 504];429 是限流,API 会在响应头里告诉你等多久:
handleRateLimitResponse(retryAfter?: number): void { this.state.isRateLimited = true; if (retryAfter) { setTimeout(() => { this.state.isRateLimited = false; this.processQueue(); // 继续处理排队的请求 }, retryAfter * 1000); }}529 是服务过载,没有明确的等待时间,用指数退避:
function calculateRetryDelay(attempt: number): number { const baseDelay = 1000; const maxDelay = 30000; // 指数增长:1s → 2s → 4s → 8s → 16s → 30s(封顶) let delay = baseDelay * Math.pow(2, attempt); // 加点随机抖动,避免所有客户端同时重试 const jitter = delay * 0.1; delay += Math.random() * jitter * 2 - jitter; return Math.min(delay, maxDelay);}指数退避的思路是:第一次重试等 1 秒,第二次等 2 秒,第三次等 4 秒… 给服务器喘息的时间。加抖动是为了避免”惊群效应”——如果一万个客户端都在同一时刻重试,服务器会更挂。
我之前做支付系统的时候,对接银行接口也是这套策略。银行系统出了名的不稳定,没有完善的重试机制根本扛不住。
还有一种特殊错误:上下文溢出。
"input length and `max_tokens` exceed context limit: 195000 + 8192 > 200000"输入 + 输出超过了模型的上下文窗口。Claude Code 会自动调整 max_tokens 重试:
function calculateAdjustedMaxTokens(overflow: ContextOverflowError): number | null { const { inputTokens, contextLimit } = overflow; // 留点 buffer const available = Math.max(0, contextLimit - inputTokens - 1000); // 至少要 3000 tokens 输出空间,否则没意义 if (available < 3000) { return null; // 无法恢复,需要压缩上下文 } return available;}这个设计挺聪明的。不是一遇到溢出就报错,而是尝试缩小输出预算,能救则救。
SSE 流处理讲完了,现在说 Session State。
你用 Claude Code 的时候,状态栏上显示着当前模型、花费金额、运行时间。这些数据存在哪里?
答案是一个全局状态对象。源码里有时候叫 sessionState,内部变量名是 r0。这玩意儿就像整个系统的”仪表盘”——核心循环在更新它,UI 在读取它,工具在查询它。
看看它的结构:
interface SessionState { // 身份信息 sessionId: string; // UUID,唯一标识这次会话 cwd: string; // 当前工作目录 originalCwd?: string; // 启动时的工作目录 startTime: number; // 会话开始时间 // 成本统计 totalCostUSD: number; // 总花费 totalAPIDuration: number; // API 调用总耗时 totalToolDuration?: number; // 工具执行总耗时 // 模型使用明细(支持多模型) modelUsage: Record<string, ModelUsageStats>; // 代码变更统计 totalLinesAdded?: number; totalLinesRemoved?: number; // 会话级权限 alwaysAllowedTools?: string[]; // Todo 列表 todos: Array<{ content: string; status: 'pending' | 'in_progress' | 'completed'; }>;}cwd 和 originalCwd 为什么要分开?因为会话过程中可能会 cd 到别的目录。originalCwd 记住启动位置,出了问题能追溯。
modelUsage 是个字典,key 是模型名,value 是使用统计:
interface ModelUsageStats { inputTokens: number; outputTokens: number; cacheReadInputTokens?: number; // 缓存读取 cacheCreationInputTokens?: number; // 缓存写入 thinkingTokens?: number; // Extended Thinking requests?: number; // API 请求次数 costUSD: number;}为什么要按模型分开统计?因为 Claude Code 支持多模型混用——主循环用 Sonnet,子代理可能用 Haiku。分开统计能看出钱花在哪了。
成本计算是用户最关心的。Claude Code 怎么算钱?
API 返回的 token 计数有好几种:
-
• input_tokens:输入 token 总数 -
• output_tokens:输出 token 数 -
• cache_read_input_tokens:从缓存读取的 token 数 -
• cache_creation_input_tokens:写入缓存的 token 数
缓存 token 的计价不一样。读缓存只要正常价格的 10%,写缓存要多付 25%。
function calculateCost(usage: TokenUsage, model: string): number { const pricing = MODEL_PRICING[model]; // claude-sonnet-4: input $3/M, output $15/M // 区分缓存和非缓存的输入 const regularInput = usage.inputTokens - (usage.cacheReadInputTokens || 0) - (usage.cacheCreationInputTokens || 0); let cost = 0; // 正常输入 cost += (regularInput / 1_000_000) * pricing.input; // 缓存读取(90% 折扣) cost += (usage.cacheReadInputTokens / 1_000_000) * pricing.input * 0.1; // 缓存写入(25% 加价) cost += (usage.cacheCreationInputTokens / 1_000_000) * pricing.input * 1.25; // 输出 cost += (usage.outputTokens / 1_000_000) * pricing.output; return cost;}你用 /cost 命令看到的数字就是这么算出来的。如果 cache_read_input_tokens 很高,说明缓存命中率好,省钱了。
每次 API 调用完成,Session 会更新统计:
updateUsage(model: string, usage: TokenUsage, cost: number, duration: number): void { // 初始化模型统计 if (!this.state.modelUsage[model]) { this.state.modelUsage[model] = { inputTokens: 0, outputTokens: 0, costUSD: 0, // ... }; } const stats = this.state.modelUsage[model]; // 累加 stats.inputTokens += usage.inputTokens; stats.outputTokens += usage.outputTokens; stats.cacheReadInputTokens += usage.cacheReadInputTokens || 0; stats.requests = (stats.requests || 0) + 1; stats.costUSD += cost; // 更新全局统计 this.state.totalCostUSD += cost; this.state.totalAPIDuration += duration;}这些更新是实时的。状态栏上的数字跳动,就是每次 API 调用后触发的。
时间追踪也有讲究。Session State 分开记录 totalAPIDuration 和 totalToolDuration。
为什么要分开?因为诊断慢会话需要知道时间花在哪了。
如果 API Duration 占大头,说明瓶颈在模型推理或网络延迟。可能是 prompt 太长,也可能是服务器忙。
如果 Tool Duration 占大头,说明瓶颈在本地工具执行。可能是跑了个耗时的测试套件,或者 grep 了一个巨大的代码库。
// 伪代码示意const apiStart = Date.now();const response = await callAPI();const apiDuration = Date.now() - apiStart;session.updateAPIDuration(apiDuration);const toolStart = Date.now();const result = await executeTool(toolRequest);const toolDuration = Date.now() - toolStart;session.updateToolDuration(toolDuration);我之前做性能监控系统的时候,也是类似的思路。不能只看总耗时,要拆开看各阶段的耗时,用arthas做接口调用耗时分析,很容易定位到请求是时间消耗在了哪里,然后再做有针对性的优化。
会话持久化是个重要特性。
你跑了半天的会话,关掉 Claude Code 后还能恢复。靠的就是会话持久化。
const SESSION_DIR = path.join(os.homedir(), '.claude', 'sessions');save(): string { const sessionFile = path.join(SESSION_DIR, `${this.state.sessionId}.json`); const data = { version: '2.0', // 版本控制,方便以后格式升级 state: this.state, messages: this.messages, metadata: { gitBranch: this.gitInfo?.branchName, projectPath: this.state.cwd, created: this.state.startTime, modified: Date.now(), messageCount: this.messages.length, }, }; fs.writeFileSync(sessionFile, JSON.stringify(data, null, 2)); return sessionFile;}存储路径是 ~/.claude/sessions/,每个会话一个 JSON 文件,用 sessionId 命名。
文件里存了什么?
-
• state:完整的会话状态(成本、时间、配置等) -
• messages:完整的消息历史 -
• metadata:元数据(git 分支、项目路径、创建时间等)
version 字段是个好习惯。以后如果格式变了,可以根据版本号做兼容处理。
有个细节:保存的时候加了文件锁。
private acquireLock(): void { this.lockFile = path.join(SESSION_DIR, `.${this.state.sessionId}.lock`); if (fs.existsSync(this.lockFile)) { const lockTime = parseInt(fs.readFileSync(this.lockFile, 'utf-8'), 10); // 5分钟超时,防止僵尸锁 if (Date.now() - lockTime > 5 * 60 * 1000) { fs.unlinkSync(this.lockFile); } else { throw new Error(`Session is locked by another process`); } } fs.writeFileSync(this.lockFile, Date.now().toString());}为什么要锁?防止两个进程同时写一个会话文件,导致数据损坏。虽然正常使用不太会遇到,但边缘情况处理好了,系统才稳定。
--resume 是怎么恢复会话的?
claude --resume这个命令会列出最近的会话,让你选一个恢复。选中后:
function resumeSession(sessionId: string): Session { const sessionFile = path.join(SESSION_DIR, `${sessionId}.json`); const data = JSON.parse(fs.readFileSync(sessionFile, 'utf-8')); // 重建会话状态 const session = new Session(); session.state = data.state; session.messages = data.messages; // 如果消息太多,生成摘要 if (session.messages.length > SUMMARY_THRESHOLD) { const summary = generateSummary(session.messages); session.injectResumeMessage(summary); } return session;}如果历史消息太多,不能全塞进上下文。Claude Code 会生成一个摘要,告诉模型”之前聊了什么”:
function buildResumeMessage(summary: string): string { return `This session is being continued from a previous conversation.The conversation is summarized below:${summary}Please continue from where we left off.`;}这个摘要会作为第一条消息注入,模型看到后就能”接上”之前的上下文。
我之前做过一个在线客服系统,也有类似的”会话恢复”功能。用户断线重连后,要能接着之前的对话继续。思路差不多,都是把历史状态持久化,恢复时重新加载。
环境变量也是 Session State 的一部分。
Claude Code 支持一堆环境变量来调整行为:
ANTHROPIC_API_KEY # API KeyCLAUDE_MODEL # 默认模型BASH_MAX_OUTPUT_LENGTH # Bash 输出截断长度BASH_DEFAULT_TIMEOUT_MS # Bash 超时时间CLAUDE_TELEMETRY_DISABLED # 禁用遥测这些变量在会话启动时读取,存入 Session State。运行中改环境变量不会影响当前会话。
// 启动时读取const config = { model: process.env.CLAUDE_MODEL || 'claude-sonnet-4-20250514', bashTimeout: parseInt(process.env.BASH_DEFAULT_TIMEOUT_MS || '120000'), telemetryDisabled: process.env.CLAUDE_TELEMETRY_DISABLED === 'true',};session.state.config = config;把 SSE 和 Session State 串起来看,数据流是这样的:
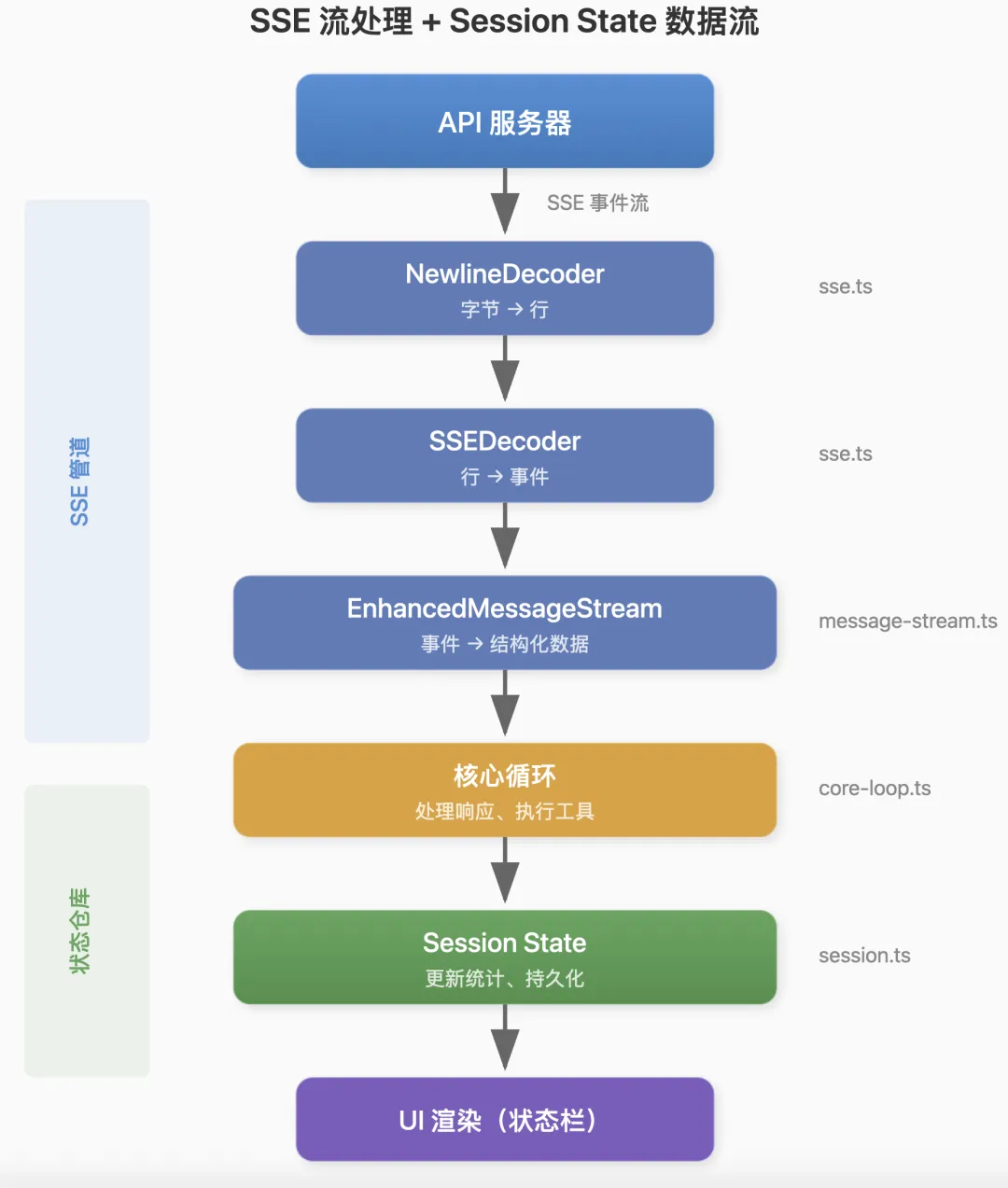
SSE 是管道,Session State 是仓库。管道把数据送进来,仓库把状态存起来。
这套设计的核心思想是:单一状态源。
不管是成本统计、token 计数、还是会话历史,都存在一个地方。任何组件想知道”现在花了多少钱”,去 Session State 查就行。不会出现”这边算出来 0.5 刀,那边算出来 0.6 刀”的情况。
我之前带团队做过一个状态管理乱七八糟的系统,状态散落在各个服务里,出了 bug 排查起来要命。后来重构成单一状态源,维护成本直接降了一半。道理是相通的。
翻完这部分代码,几点收获:
流式处理不只是为了”好看”,还支持取消、早失败、实时反馈。实现起来比想象的复杂,要处理分片到达、心跳检测、优雅中断。
错误重试要分类处理。可重试的错误(限流、超时)用指数退避;不可重试的错误(参数错误)直接报错。还要加抖动避免惊群。
全局状态要有”单一真相源”。谁都能读,但更新要走统一的接口。这样系统才可预测、好调试。
会话持久化要考虑版本兼容和并发安全。文件锁虽然看起来土,但管用。
下一篇聊权限系统。危险命令要拦,但正常命令也不能随便跑——什么时候该问用户,什么时候可以静默执行,这里面的门道也不少。
本文基于 Claude Code 2.0.76 版本源码分析,主要文件:src/streaming/sse.ts、src/streaming/message-stream.ts、src/core/session.ts、src/network/retry.ts。
最后记得⭐️我,每天都在更新:欢迎点赞转发推荐评论,别忘了关注我

