 夜雨聆风
夜雨聆风





大模型2025年12月论文分享(含源码)
-
SuperCLIP: CLIP with Simple Classification Supervision[NeurIPS2025]
-
论文:https://arxiv.org/pdf/2512.14480
-
代码:https://github.com/hustvl/SuperCLIP
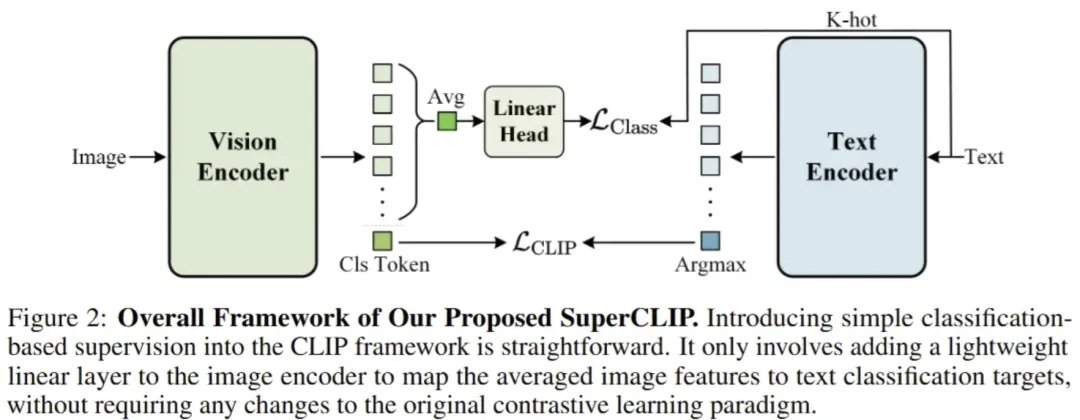
总结:这篇论文提出了一种名为 SuperCLIP 的简单高效视觉–语言预训练框架,通过在标准 CLIP 的对比学习目标中引入 基于分类的监督信号,使模型能够利用文本中 所有单词级别的语义信息 来显著增强视觉–文本细粒度对齐能力,而无需额外标注数据且只增加极少的计算量(约 0.077% FLOPs)。实验证明,SuperCLIP 在零样本分类、图像–文本检索以及纯视觉任务上均比原始 CLIP 有稳定提升,同时也缓解了 CLIP 在小批量训练下性能下降的问题。
-
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning[AAAI2026]
-
论文:https://arxiv.org/pdf/2512.15433
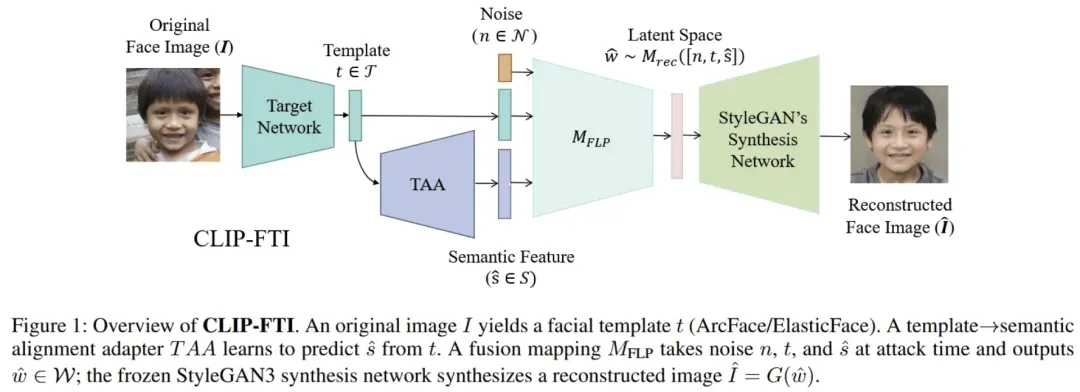
总结:这篇论文提出了一种新的 基于 CLIP 的细粒度人脸模板反演(face template inversion)攻击框架 CLIP-FTI,用于从泄露的面部识别模板中重建更高精度、更具细节的面部图像。与以往只利用模板直接映射到生成模型潜在空间的方法相比,它通过 借助 CLIP 提取人脸特征的语义嵌入(如眼睛、鼻子、嘴巴等属性)并与模板融合,再映射到预训练 StyleGAN 的中间潜在空间,从而生成 既保持身份一致性又包含更细粒度属性的重建人脸。实验证明,该方法在 识别准确度、属性相似性、细节恢复和跨模型攻击迁移性 等方面都优于先前的方法,是首个利用 CLIP 语义信息加强模板反演的工作。
-
CausalCLIP: Causally-Informed Feature Disentanglement and Filtering for Generalizable Detection of Generated Images[AAAI2026]
-
论文:https://arxiv.org/pdf/2512.13285
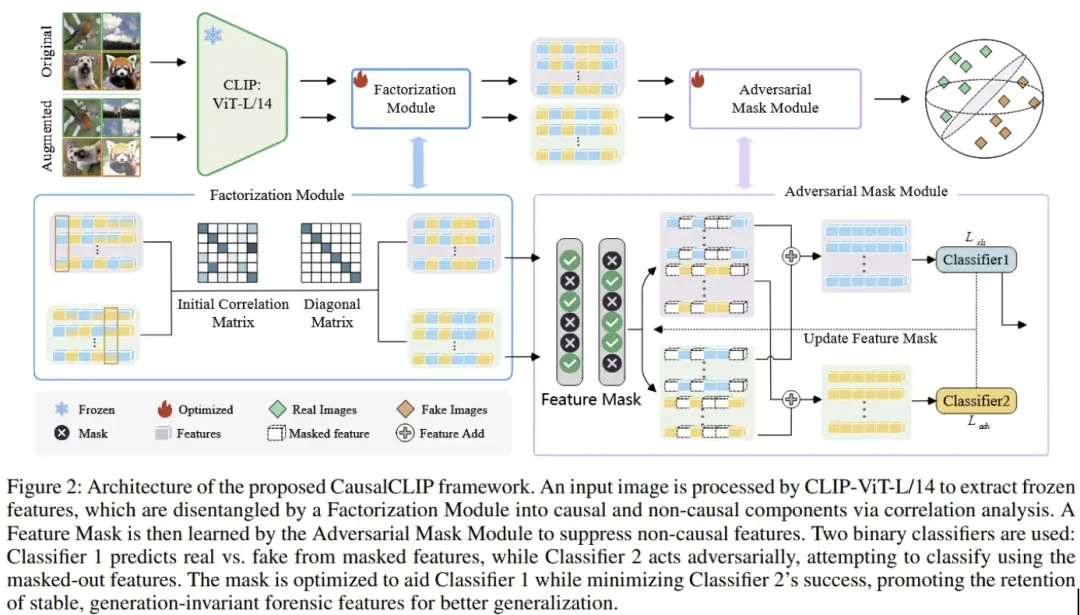
总结:这篇论文提出了一种新颖的 因果引导视觉–语言模型检测框架 CausalCLIP,用于提高对 AI 生成图像检测的 跨生成模型泛化能力。现有方法往往在特征空间中混合了真正有助于区分真实/生成图像的因果线索和与特定数据/模型关联的非因果信息,导致泛化性能受限。CausalCLIP 首先利用结构因果模型和特征分离机制,将 CLIP 提取的特征显式分解为因果(稳定)与非因果(伪相关)两部分,然后通过对非因果部分的对抗屏蔽与统计独立约束筛除干扰,只保留对检测最有用的因果特征。实验证明,该方法在面对不同系列、未见过的生成模型时,相比现有方法显著提升了检测准确率和平均精度,展现了更强的泛化能力。
-
MeViS: A Multi-Modal Dataset for Referring Motion Expression Video Segmentation[TPAMI]
-
论文:https://arxiv.org/pdf/2512.10945
-
代码:https://henghuiding.com/MeViS/
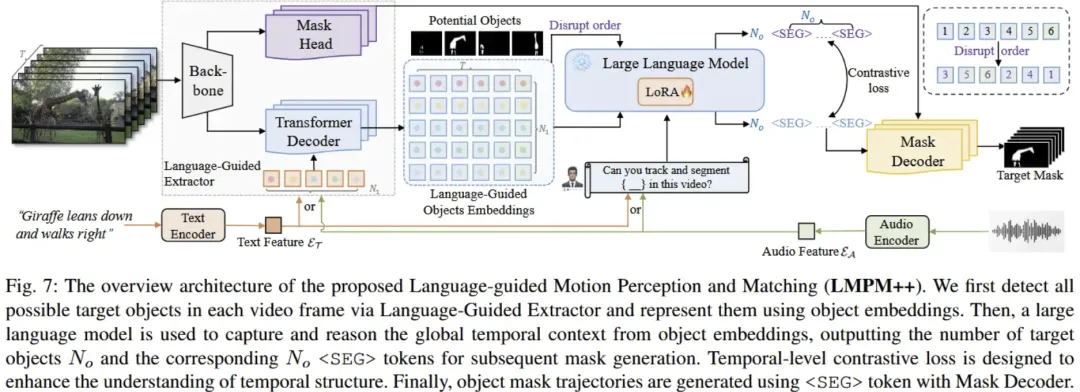
总结:这篇论文提出并发布了一个 大规模多模态数据集 MeViS(及其升级版 MeViSv2),专注于视频中基于语言描述的运动表达(motion expression)来完成像素级目标分割与跟踪任务,弥补了现有数据集中静态属性过多、运动线索不足的问题。MeViS 包含 33,072 条文本与音频运动表达、8,171 个对象、2,006 段复杂视频场景,支持至少 4 种任务:指向性视频目标分割(RVOS)、音频引导视频目标分割(AVOS)、多目标跟踪(RMOT)和运动表达生成(RMEG)。作者不仅对 15 种现有方法进行了全面基准测试,揭示了它们在处理运动表达视频理解时的不足,还提出了一个基线方法 LMPM++ 来提升这些任务的性能。该数据集及代码将对运动表达驱动的视频理解算法研究提供重要平台。
-
MedForget: Hierarchy-Aware Multimodal Unlearning Testbed for Medical AI
-
论文:https://arxiv.org/pdf/2512.09867
-
代码:https://github.com/fengli-wu/MedForget
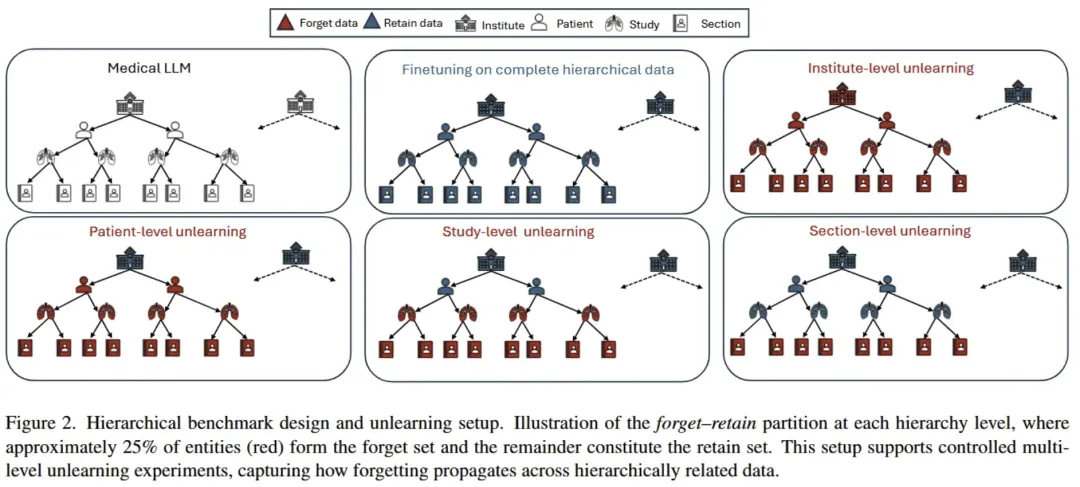
总结:这篇论文介绍了一个面向 医疗多模态大模型(MLLM) 的 层次感知遗忘(unlearning)测试基准 MedForget,用于系统评估在敏感临床数据上实现“被遗忘权”时的实际效果与挑战,特别是在 HIPAA/GDPR 等隐私法规下的合规性。该基准将医院数据按照 机构 → 患者 → 检查 → 报告部分 构建成四层嵌套层次,并提供明确的保留/遗忘划分以及重述变体的评估集,共包含 3840 条图像–提问–答案实例,以检验不同层次和粒度的遗忘需求。论文实验证明,目前最先进的遗忘方法在无需显著降低诊断性能的前提下难以完全且层次感知地删除信息,尤其细粒度遗忘存在被重构攻击恢复敏感内容的风险,从而强调了医疗 AI 中细粒度、结构感知遗忘研究的重要性。
-
DashFusion: Dual-stream Alignment with Hierarchical Bottleneck Fusion for MultimodalSentiment Analysis[TNNLS]
-
论文:https://arxiv.org/pdf/2512.05515
-
代码:https://github.com/ultramarineX/DashFusion
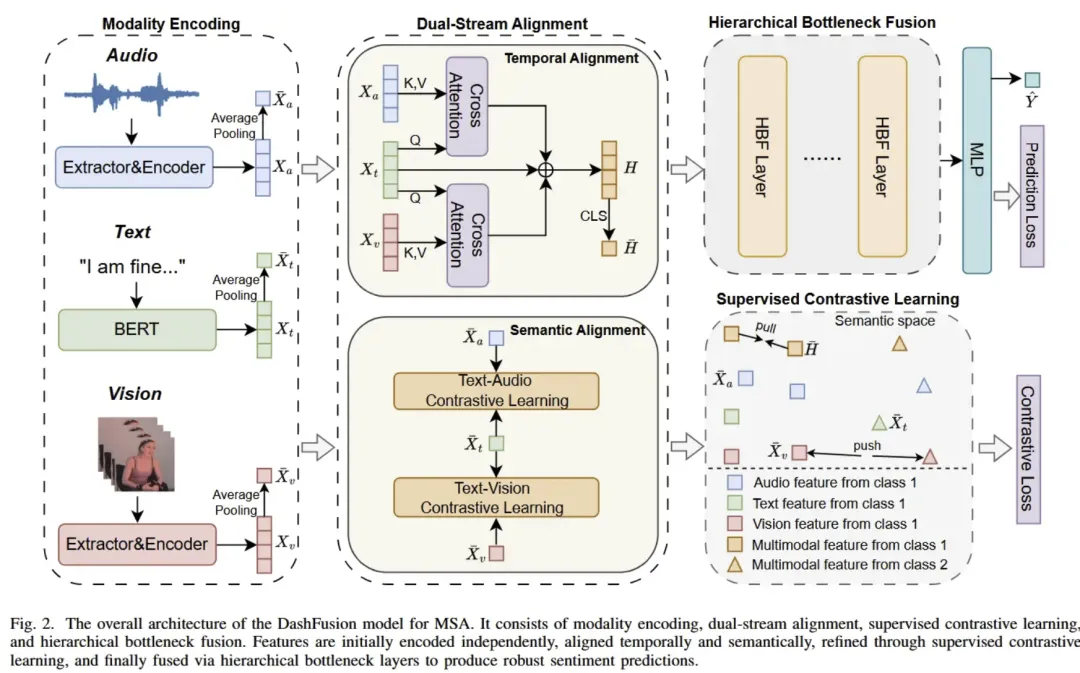
总结:这篇论文提出了一种新颖的多模态情感分析框架 DashFusion,旨在同时解决多模态情感分析中的 时间与语义对齐 以及 多模态融合 难题。作者通过一个 双流对齐模块 来在时间和语义两个层面同步不同模态(文本、图像、音频)的特征,并结合 有监督对比学习 提升特征判别能力;随后引入 分层瓶颈融合机制,通过逐步压缩信息瓶颈令不同模态更高效地融合,兼顾性能与计算效率。实验证明,DashFusion 在 CMU-MOSI、CMU-MOSEI 和 CH-SIMS 等标准数据集上达到了最先进的情感分析表现。
-
OneThinker: All-in-one Reasoning Model for Image and Video
-
论文:https://arxiv.org/pdf/2512.03043
-
代码:https://github.com/tulerfeng/OneThinker
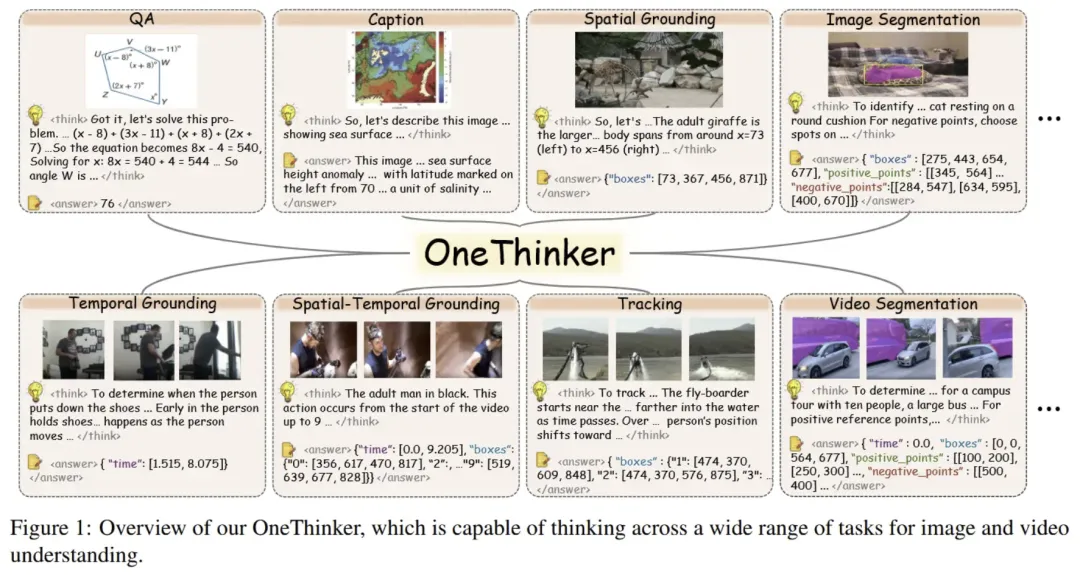
总结:这篇论文提出了一种统一的多模态视觉推理通用模型OneThinker,旨在跨图像和视频理解多个基础视觉任务(如问答、描述生成、空间/时间定位、跟踪与分割)实现一体化处理,而不是像现有方法那样为每项任务训练独立模型。作者构建了一个大规模训练语料 OneThinker-600k 及其经商业模型 Chain-of-Thought 注释的子集 OneThinker-SFT-340k,并提出 EMA-GRPO 强化学习算法来平衡不同任务的奖励异质性,最终使模型在 31 个基准、10 类视觉理解任务上稳定表现优异,展现了知识迁移与初步的零样本泛化能力,是朝向统一图像+视频视觉推理通用体的一大步。
-
SAM Fails to Segment Anything? — SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation, and More
-
论文:http://tianrun-chen.github.io/SAM-Adaptor/
-
代码:http://tianrun-chen.github.io/SAM-Adaptor/
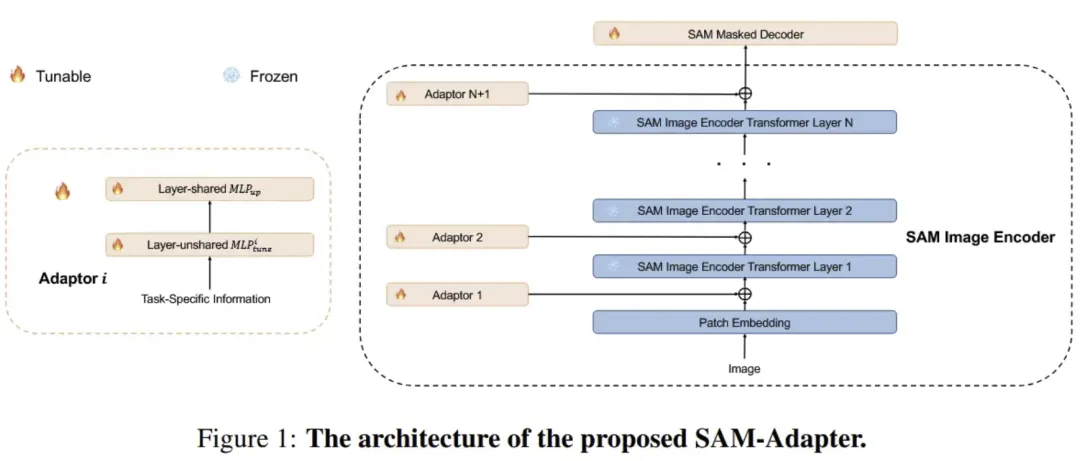
总结:SAM-Adaptor是一项面向 Segment Anything Model(SAM) 的高效迁移与适配工作,核心目标是在冻结 SAM 主体参数的前提下,使其能够快速适应不同下游分割任务(如医学图像、遥感、工业场景等)。该方法通过在 SAM 编码器和解码器中引入 轻量级、即插即用的 Adaptor 模块,仅需训练极少量参数即可实现领域特征对齐与任务定制,避免了全量微调带来的高成本与过拟合风险。实验结果表明,SAM-Adaptor 在多种专业分割场景中显著优于直接使用 SAM 或传统微调方案,在性能、参数效率和泛化能力之间取得了良好平衡,是推动 SAM 向真实垂直领域落地的重要一步。
