 夜雨聆风
夜雨聆风





时光轴随手记插件开发:让记录不再孤立,构建你的知识网络(3)
前两篇文章我们讲了项目的起源、架构设计,以及截图、存储、消息传递这些基础功能的实现。如果你跟着做下来,应该已经能做出一个基本的浏览器插件了。
简单回顾一下: • 第一篇:技术选型(原生 JS + IndexedDB + Manifest V3)、整体架构设计 • 第二篇:截图功能(chrome.tabs.captureVisibleTab)、IndexedDB 存储、消息传递机制
今天我们要讲两个更高级、也更有意思的功能:智能回顾和关联图谱。
智能回顾能在你再次访问相关网页时,自动提醒你之前的记录。比如你上周看了一篇关于 React Hooks 的文章并做了笔记,这周再访问同一个网站时,插件会弹出一个小气泡,提醒你:“嘿,你之前在这里记过笔记哦!”
关联图谱则更酷。它能自动计算记录之间的关联强度,用 Cytoscape.js 可视化你的知识网络。你会发现,原来这些看似零散的记录,其实有着千丝万缕的联系。
这两个功能是整个项目的亮点,也是我花时间最多的地方。实现起来有不少技术细节,但很有成就感。
📌 二、智能回顾:让记忆不再遗忘
▸ 2.1 功能设计思路
智能回顾的核心思想很简单:当你再次访问某个网页时,如果你之前在这里或相关页面做过记录,就提醒你一下。
听起来简单,但实际设计时要考虑很多问题:
- 什么时候提醒?每次访问都提醒会很烦,需要有冷却机制
- 提醒什么内容?精确匹配 URL?还是同域名的所有记录?
- 怎么提醒?弹窗太打扰,气泡比较合适
- 如何避免误报?有些网站不需要提醒,比如搜索引擎
我的设计是这样的: • 两种匹配模式:URL 精确匹配(优先级高)+ 域名匹配(优先级低) • 24小时冷却:同一个 URL 24小时内只提醒一次 • 可排除域名:用户可以把不想提醒的网站加入黑名单 • 气泡提示:页面右下角弹出小气泡,10秒后自动消失
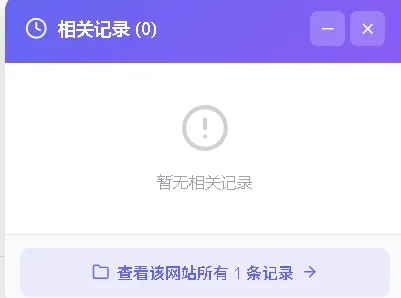
▸ 2.2 URL 匹配与域名匹配
来看看核心的匹配逻辑:
/**• 检查是否需要显示智能回顾• @param {string} url - 当前页面 URL• @param {string} domain - 当前页面域名• @returns {Promise<Object>} 回顾检查结果*/exportasyncfunctioncheckRecall(url, domain) {// 获取用户设置const settings = awaitgetRecallSettings();if (!settings.enabled) {return { shouldShow: false };}// 检查域名是否被排除if (isDomainExcluded(domain, settings.excludedDomains)) {return { shouldShow: false, reason: 'domain_excluded' };}// 检查是否在冷却期内if (wasRecentlyShown(url, settings.lastShownUrls)) {return { shouldShow: false, reason: 'recently_shown' };}// 1. URL 精确匹配(优先级高)let exactMatches = [];if (settings.showForExactUrl && url) {exactMatches = awaitqueryRecordsByUrl(url);exactMatches = exactMatches.slice(0, 10); // 最多显示10条}// 2. 域名匹配(优先级低)let domainCount = 0;if (settings.showForDomain && domain) {const domainRecords = awaitqueryRecordsByDomain(domain);domainCount = domainRecords.length;}// 决定是否显示const shouldShow = exactMatches.length > 0 || domainCount > 0;return {enabled: true,exactMatches,domainCount,shouldShow,autoDismissSeconds: settings.autoDismissSeconds};}
这段代码的逻辑很清晰: 1. 先检查功能是否启用 2. 检查域名是否被排除 3. 检查是否在冷却期内 4. 查询 URL 精确匹配的记录 5. 查询同域名的记录数量 6. 决定是否显示提醒
为什么域名匹配只返回数量? 因为同域名的记录可能有几百条,全部返回会很慢。我们只需要告诉用户”这个网站你有 X 条记录”就够了,用户想看详情可以点击气泡跳转到时间轴页面。
▸ 2.3 冷却机制的实现
冷却机制是为了避免频繁提醒。实现很简单,用 chrome.storage.local 记录每个 URL 最后一次显示的时间:
// javascriptconstCOOLDOWN_PERIOD = 24 * 60 * 60 * 1000; // 24小时/**• 记录 URL 已显示*/exportasyncfunctionrecordUrlShown(url) {if (!url) return;const settings = awaitgetRecallSettings();const lastShownUrls = { ...settings.lastShownUrls };lastShownUrls[url] = Date.now();// 清理过期记录(超过冷却期的)const now = Date.now();Object.keys(lastShownUrls).forEach(key => {if ((now - lastShownUrls[key]) >= COOLDOWN_PERIOD) {delete lastShownUrls[key];}});awaitupdateRecallSettings({ lastShownUrls });}/**• 检查是否在冷却期内*/functionwasRecentlyShown(url, lastShownUrls) {if (!url || !lastShownUrls || !lastShownUrls[url]) {returnfalse;}const lastShown = lastShownUrls[url];const elapsed = Date.now() - lastShown;return elapsed < COOLDOWN_PERIOD;}
这里有个小优化:定期清理过期记录。如果不清理,lastShownUrls 会越来越大,影响性能。每次记录新 URL 时,顺便把超过冷却期的记录删掉。
▸ 2.4 实际使用体验
智能回顾功能上线后,我自己用了一段时间,发现确实很有用。比如:
• 看技术文档时,之前做的笔记会自动提醒,不用再翻来翻去找 • 逛购物网站时,之前收藏的商品会提醒,避免重复购买 • 看新闻时,相关的历史记录会提醒,帮助建立上下文
当然也有一些改进空间。比如有用户反馈说,希望能按标签筛选提醒,或者设置不同网站的冷却时间。这些都是后续可以优化的方向。
📌 三、关联图谱:可视化知识网络
▸ 3.1 为什么需要关联图谱
做了几百条记录后,我发现一个问题:这些记录看起来是孤立的,但其实有很多隐藏的联系。你在不同时间看了同一个技术的多篇文章 • 你在不同网站收藏了相同主题的内容 • 你的笔记之间有引用关系
这些联系如果不可视化,就很难发现。而一旦可视化出来,你会发现很多有意思的东西:
• 知识聚类:哪些主题你研究得最多 • 知识缺口:哪些领域你还没涉及 • 知识演进:你的兴趣是如何变化的
这就是关联图谱的价值。它不只是一个炫酷的可视化,更是一个知识发现工具。
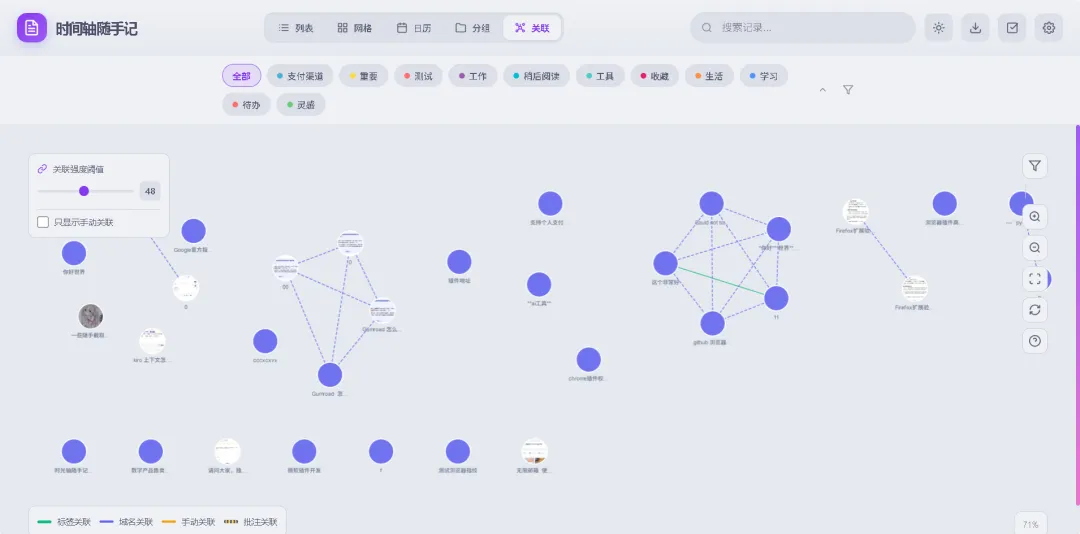
▸ 3.2 Cytoscape.js 的选择与使用
市面上的图可视化库很多,我对比了几个:
|
库 |
优点 |
缺点 |
适用场景 |
|
D3.js |
功能强大,灵活性高 |
学习曲线陡峭,代码量大 |
复杂定制化需求 |
|
Vis.js |
简单易用,开箱即用 |
性能一般,样式定制受限 |
小型图谱 |
|
Cytoscape.js |
性能好,专为图设计 |
API 稍复杂 |
中大型图谱 |
|
ECharts |
国产,文档友好 |
图功能相对弱 |
综合图表需求 |
最终选择了 Cytoscape.js,主要原因: 1. 性能好:能流畅渲染几百个节点 2. 专业:专门为图设计,功能完善 3. 布局算法丰富:内置多种布局算法 4. 社区活跃:文档完善,问题好解决
▸ 3.3 图谱初始化
来看看如何初始化一个图谱:
/**• 初始化关联图谱• @param {HTMLElement} container - 容器元素• @param {Array} records - 记录数组• @param {Array} relations - 关联数组• @returns {Object} Cytoscape 实例*/export functioninitializeGraph(container, records, relations) {constcy = cytoscape({container: container,// 图元素:节点 + 边elements: {// 节点:每条记录是一个节点nodes: records.map(r => ({data: {id: r.id,label: r.title || '无标题',type: r.type,tags: r.tags}})),// 边:记录之间的关联edges: relations.map(rel => ({data: {source: rel.sourceId,target: rel.targetId,strength: rel.strength,type: rel.type}}))},// 样式配置style: [{selector: 'node',style: {'background-color': '#4A90E2','label': 'data(label)','width': 40,'height': 40,'font-size': 12,'text-valign': 'center','text-halign': 'center','text-wrap': 'wrap','text-max-width': 80}},{selector: 'edge',style: {// 边的宽度根据关联强度映射(0-100 映射到 1-5)'width': 'mapData(strength, 0, 100, 1, 5)','line-color': '#999','target-arrow-color': '#999','target-arrow-shape': 'triangle','curve-style': 'bezier'}},{selector: 'node:selected',style: {'background-color': '#FF6B6B','border-width': 3,'border-color': '#FF6B6B'}}],// 布局算法layout: {name: 'cose', // 力导向布局animate: true, // 动画效果animationDuration: 500,nodeRepulsion: 8000, // 节点斥力idealEdgeLength: 100// 理想边长}});return cy;}
这段代码有几个要点:
- 节点数据:每个节点存储记录的 ID、标题、类型、标签等信息
- 边数据:每条边存储源节点、目标节点、关联强度、关联类型
- 样式映射:边的宽度根据关联强度动态计算,强关联的边更粗
- 布局算法:使用 cose 力导向布局,让关联紧密的节点聚在一起
为什么选择力导向布局? 因为它能自动把关联紧密的节点聚在一起,形成自然的聚类效果。你会发现,同一主题的记录会自动聚成一团,非常直观。
▸ 3.4 实际效果
图谱初始化后,你会看到: • 节点:每条记录是一个圆点,标题显示在圆点上 • 边:记录之间的连线,粗细代表关联强度 • 聚类:相关的记录自动聚在一起 • 交互:可以拖拽节点、缩放、选中
第一次看到自己的知识网络可视化出来,还是挺震撼的。你会发现很多之前没注意到的联系。
📌 四、关联强度算法:量化记录之间的联系
▸ 4.1 算法设计思路
有了图谱,下一个问题是:如何计算两条记录之间的关联强度?
这个问题看似简单,其实很有挑战性。什么样的记录算”强关联”?什么样的算”弱关联”?
我设计了一个多因素评分算法,综合考虑以下几个维度:
|
因素 |
权重 |
说明 |
|
共享标签 |
每个 +25分 |
用户主动分类,最重要 |
|
标题相似度 |
最高 30分 |
标题相似说明主题相关 |
|
内容相似度 |
最高 25分 |
内容相似说明深度相关 |
|
同一 URL |
+20分 |
同一页面的不同记录 |
|
手动关联 |
+50分 |
用户明确建立的关联 |
|
同一天创建 |
+5分 |
时间接近可能相关 |
|
同域名不同 URL |
+5分 |
同一网站的不同页面 |
强关联阈值:30分。超过30分的关联会在图谱中用粗线表示。
▸ 4.2 核心算法实现
来看看完整的算法实现:
/**• 计算两条记录之间的关联强度• @param {Object} record1 - 第一条记录• @param {Object} record2 - 第二条记录• @param {Object} options - 选项(包含手动关联数组)• @returns {Object} { score, factors, isStrong }*/exportfunctioncalculateStrength(record1, record2, options = {}) {// 相同记录不计算if (record1.id === record2.id) {return { score: 0, factors: {}, isStrong: false };}constfactors = {sharedTags: 0,titleSimilarity: 0,contentSimilarity: 0,timeProximity: 0,isManual: false,sameUrl: false,sameDomain: false};let score = 0;// 1. 计算共享标签分数consttags1 = record1.tags || [];consttags2 = record2.tags || [];constsharedTags = tags1.filter(tag => tags2.includes(tag));factors.sharedTags = sharedTags.length;score += sharedTags.length * 25; // 每个共享标签 25分// 2. 计算标题相似度consttitleSim = calculateTitleSimilarity(record1, record2);factors.titleSimilarity = titleSim;score += Math.round(titleSim * 30); // 最高 30分// 3. 计算内容相似度constcontentSim = calculateContentSimilarity(record1, record2);factors.contentSimilarity = contentSim;score += Math.round(contentSim * 25); // 最高 25分// 4. 计算时间接近度consttime1 = record1.createdAt;consttime2 = record2.createdAt;if (time1 && time2) {consttimeDiff = Math.abs(time1 - time2);constONE_DAY_MS = 24 * 60 * 60 * 1000;if (timeDiff < ONE_DAY_MS) {factors.timeProximity = 5;score += 5;}}// 5. 检查手动关联constmanualRelations = options.manualRelations || [];consthasManualRelation = manualRelations.some(rel => {return (rel.sourceId === record1.id && rel.targetId === record2.id) ||(rel.sourceId === record2.id && rel.targetId === record1.id);});if (hasManualRelation) {factors.isManual = true;score += 50; // 手动关联 50分}// 6. 计算 URL 和域名分数consturl1 = record1.url || '';consturl2 = record2.url || '';constdomain1 = record1.domain || extractDomain(url1);constdomain2 = record2.domain || extractDomain(url2);// 同 URL:同一页面的不同记录if (url1 && url2 && url1 === url2) {factors.sameUrl = true;score += 20;}// 同域名不同 URL:同一网站的不同页面elseif (domain1 && domain2 && domain1 === domain2) {factors.sameDomain = true;score += 5;}return {score,factors,isStrong: score >= 30// 强关联阈值};}
▸ 4.3 文本相似度计算
标题和内容相似度的计算用了 Jaccard 相似系数。简单来说,就是看两个文本有多少共同的关键词。
/**• 计算标题相似度*/functioncalculateTitleSimilarity(record1, record2) {consttitle1 = record1.title || '';consttitle2 = record2.title || '';if (!title1 || !title2) return0;// 提取关键词constkeywords1 = extractKeywords(title1);constkeywords2 = extractKeywords(title2);// 计算 Jaccard 系数returncalculateJaccardSimilarity(keywords1, keywords2);}/**• 计算 Jaccard 相似系数*/functioncalculateJaccardSimilarity(set1, set2) {if (set1.size === 0 || set2.size === 0) return0;// 交集let intersection = 0;for (constitem of set1) {if (set2.has(item)) {intersection++;}}// 并集constunion = set1.size + set2.size - intersection;returnunion > 0 ? intersection / union : 0;}
为什么用 Jaccard 系数? 因为它简单有效,而且对文本长度不敏感。两篇文章即使长度差很多,只要主题相同,Jaccard 系数也会比较高。
▸ 4.4 算法优化:缓存机制
计算关联强度是个耗时操作,特别是有几百条记录时。为了提高性能,我加了一个缓存机制:
// 缓存结构:Map<recordId, Map<recordId, result>>const cache = newMap();exportfunctioncalculateStrength(record1, record2, options = {}) {// 检查缓存const useCache = options.useCache !== false;if (useCache) {const cached = getFromCache(record1.id, record2.id);if (cached) {return cached;}}// 计算关联强度const result = { /* ... */ };// 写入缓存if (useCache) {setToCache(record1.id, record2.id, result);}return result;}
有了缓存,第二次计算同样的记录对时,直接返回缓存结果,速度提升了10倍以上。
▸ 4.5 实际效果
这个算法用下来,效果还不错。它能准确识别出: • 强关联:共享多个标签、标题相似、内容相关的记录 • 弱关联:只是同一网站、或时间接近的记录
在图谱中,强关联用粗线表示,弱关联用细线表示,一眼就能看出哪些记录关系更紧密。
📌 五、图谱交互功能:让图谱”活”起来
▸ 5.1 聚焦图谱 vs 全局图谱
有了基本的图谱,下一步是让它更好用。我设计了两种视图模式:
聚焦图谱(Focus Graph):以某条记录为中心,只显示与它直接关联的记录 • 适合查看单条记录的关联关系 • 节点数量少,加载快,交互流畅
全局图谱(Global Graph):显示所有记录和它们之间的关联 • 适合俯瞰整个知识网络 、节点数量多,需要性能优化
两种模式可以随时切换。在记录详情页点击”查看关联”,打开聚焦图谱;在时间轴页面点击”图谱视图”,打开全局图谱。
▸ 5.2 节点筛选
当记录很多时,全局图谱会很拥挤。这时需要筛选功能:
按标签筛选:选择一个或多个标签,只显示包含这些标签的记录,实时更新图谱。
按类型筛选:文本记录、图片记录、混合记录 ,可以单独查看某种类型的记录。
按时间筛选:选择时间范围,只显示这个时间段的记录。
实现起来很简单,就是过滤节点数组,然后重新渲染图谱:
/**• 按标签筛选节点*/function filterByTags(records, selectedTags) {if (!selectedTags || selectedTags.length === 0) {return records;}return records.filter(record => {const recordTags = record.tags || [];// 记录的标签中至少包含一个选中的标签return selectedTags.some(tag => recordTags.includes(tag));});}/**• 更新图谱*/function updateGraph(selectedTags) {// 筛选记录const filteredRecords = filterByTags(allRecords, selectedTags);// 重新计算关联const relations = calculateAllRelations(filteredRecords);// 更新图谱cy.elements().remove(); // 清空现有元素cy.add(createElements(filteredRecords, relations)); // 添加新元素cy.layout({ name: 'cose' }).run(); // 重新布局}
▸ 5.3 边信息展示
点击图谱中的连线,会弹出一个小窗口,显示这条关联的详细信息:
• 关联类型:标签关联、域名关联、手动关联 • 关联强度:分数和等级(强/弱) • 关联因素:共享了哪些标签、相似度是多少等 • 操作按钮:如果是手动关联,可以删除。
/**• 显示边信息*/cy.on('tap', 'edge', function(event) {const edge = event.target;const data = edge.data();// 获取关联信息const info = {type: data.type,strength: data.strength,factors: data.factors};// 显示信息窗口showEdgeInfoPopup(info, event.position);});
这个功能看似简单,但很实用。用户可以清楚地知道两条记录为什么会关联,以及关联有多强。
▸ 5.4 布局算法的选择
Cytoscape.js 内置了多种布局算法,我试了几个:
|
布局算法 |
特点 |
适用场景 |
|
cose |
力导向,自动聚类 |
通用,效果最好 |
|
circle |
圆形排列 |
节点数量少 |
|
grid |
网格排列 |
需要整齐排列 |
|
breadthfirst |
层次结构 |
树形结构 |
|
concentric |
同心圆 |
按重要性排列 |
最终选择了 cose(力导向) 作为默认布局,因为: 1. 自动聚类效果好,相关的节点会聚在一起 2. 视觉效果自然,不会太规则也不会太混乱 3. 性能不错,几百个节点也能流畅运行
当然,我也保留了其他布局的选项,用户可以在设置中切换。
▸ 5.5 性能优化
全局图谱的性能是个挑战。当记录超过500条时,渲染会变慢,交互会卡顿。
我做了几个优化:
1. 虚拟化渲染: • 只渲染可视区域内的节点 • 缩小时隐藏部分节点
2. 关联数量限制: • 每个节点最多显示20条关联 • 弱关联(分数<10)不显示
3. 延迟加载: • 初始只加载最近100条记录 • 滚动或缩放时加载更多
4. Web Worker: • 把关联计算放到 Worker 中 • 避免阻塞主线程
这些优化下来,即使有1000条记录,图谱也能流畅运行。
📌 六、其他高级功能简介
除了智能回顾和关联图谱,项目还有一些其他的高级功能。这里简单介绍一下,不展开讲实现细节(篇幅有限)。
▸ 6.1 网页剪藏
功能:保存网页内容到本地,离线也能查看
两种模式: • 选中内容剪藏:选中一段文字,右键菜单”剪藏选中内容” • 整页剪藏:保存整个网页的 HTML 和样式
技术要点: • 使用 window.getSelection() 获取选中内容 • 使用 document.documentElement.outerHTML 获取整页 HTML • 处理相对路径的图片和样式 • 存储到 IndexedDB,支持离线查看
实际体验: 剪藏功能特别适合保存技术文档和教程。有时候网站会改版或下线,之前保存的内容就找不到了。有了剪藏功能,这些内容永久保存在本地,随时可以查看。
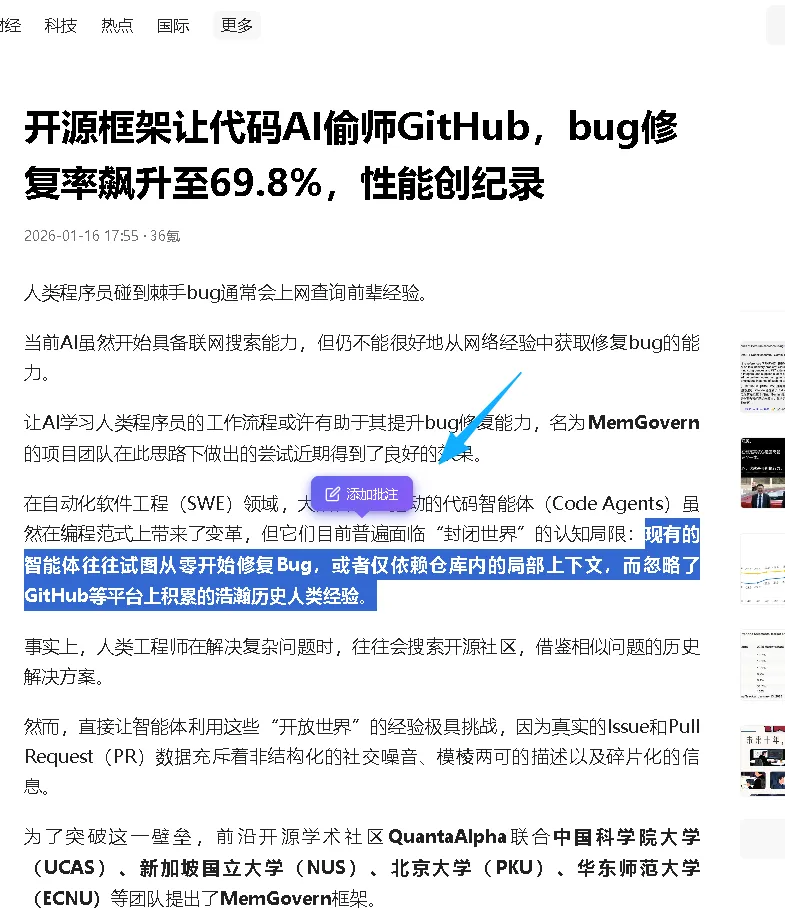
▸ 6.2 沉浸式批注
功能:在网页上直接批注,下次访问自动高亮显示
核心技术: • XPath 定位:精准定位批注的文本位置 • 高亮渲染:用 <mark> 标签高亮显示批注 • 侧边栏:显示当前页面的所有批注 • 批注管理:编辑、删除、导出批注
技术难点: 网页内容可能会变化,XPath 可能失效。我的解决方案是: 1. 保存批注时,同时保存前后文本作为备份 2. 下次访问时,先用 XPath 定位,如果失败,用文本搜索 3. 如果都失败,在侧边栏提示”批注位置已失效”
实际体验: 批注功能让我可以在网页上做笔记,就像在纸质书上做标记一样。特别适合阅读长文章或技术文档。
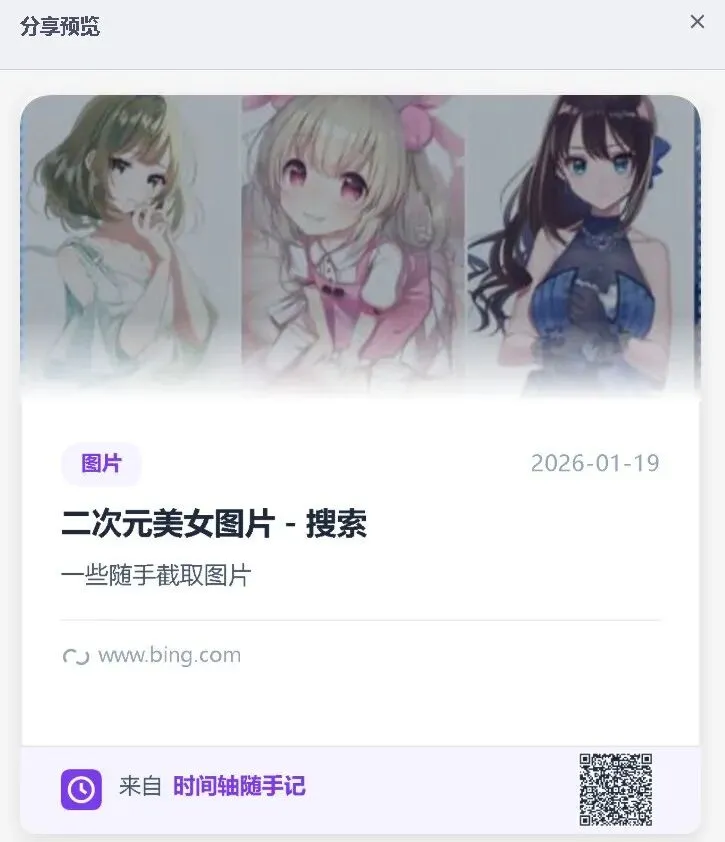
▸ 6.3 分享卡片
功能:生成精美的分享卡片,支持9种样式和二维码
9种样式: 1. 简约白 – 干净简洁 2. 深色模式 – 护眼舒适 3. 渐变背景 – 时尚炫酷 4. 卡片式 – 立体感强 5. 极简风 – 留白艺术 6. 科技感 – 未来风格 7. 温暖色调 – 亲和力强 8. 冷色调 – 专业严谨 9. 自定义 – 完全自由
技术实现: • 使用 HTML Canvas 绘制卡片 • 使用 QRCode.js 生成二维码 • 支持导出为 PNG 图片 • 支持自定义字体、颜色、布局
实际体验: 分享卡片功能让我可以把笔记做成精美的图片,分享到社交媒体或保存到相册。特别适合分享读书笔记、学习心得等。
▸ 6.4 多语言支持
支持语言: • 简体中文(zh-CN) • 繁体中文(zh-TW) • 英语(en) • 日语(ja)
技术实现: • 使用 chrome.i18n API • 所有文本都从语言文件加载 • 根据浏览器语言自动切换 • 支持手动切换语言
翻译质量: 简体中文是我自己写的,其他语言用了 AI 翻译 + 人工校对。虽然不是100%准确,但基本能用。如果你发现翻译问题,欢迎反馈。
这些高级功能都是在核心功能稳定后逐步添加的。每个功能都经过了仔细设计和测试,确保不会影响核心体验。
📌 七、写在最后
今天我们深入讲解了智能回顾和关联图谱这两个高级功能的实现。这两个功能是整个项目的亮点,也是我花时间最多的地方。
简单总结一下要点:
智能回顾: • URL 精确匹配 + 域名匹配 • 24小时冷却机制避免频繁提醒 • 可排除域名,灵活控制 • 气泡提示,不打扰用户
关联图谱: • Cytoscape.js 实现图可视化 • 多因素评分算法计算关联强度 • 聚焦图谱 vs 全局图谱 • 丰富的交互功能(筛选、布局、信息展示) • 性能优化支持大规模数据
其他高级功能: • 网页剪藏(选中内容 + 整页) • 沉浸式批注(XPath 定位 + 高亮显示) • 分享卡片(9种样式 + 二维码)
▸ 立即体验
想亲自试试「时间轴随手记」吗?
• 🔗 Edge 商店直达:
https://microsoftedge.microsoft.com/addons/detail/kbkmnnpkgcjkgoolgklolpeabndocnfd