 夜雨聆风
夜雨聆风





OpenCode源码解读(一)-提示词管理
OpenCode是一个开源的Claude Code,之前已经做了一个大概的介绍。虽然我觉得OpenCode还不足以替换我现在用的Cursor,但作为一个Agent来说已经非常成熟,其设计理念是非常值得学习的,因此我将详细对其源码进行解读,尽可能的理解一个成熟Agent需要考虑的细节
引言
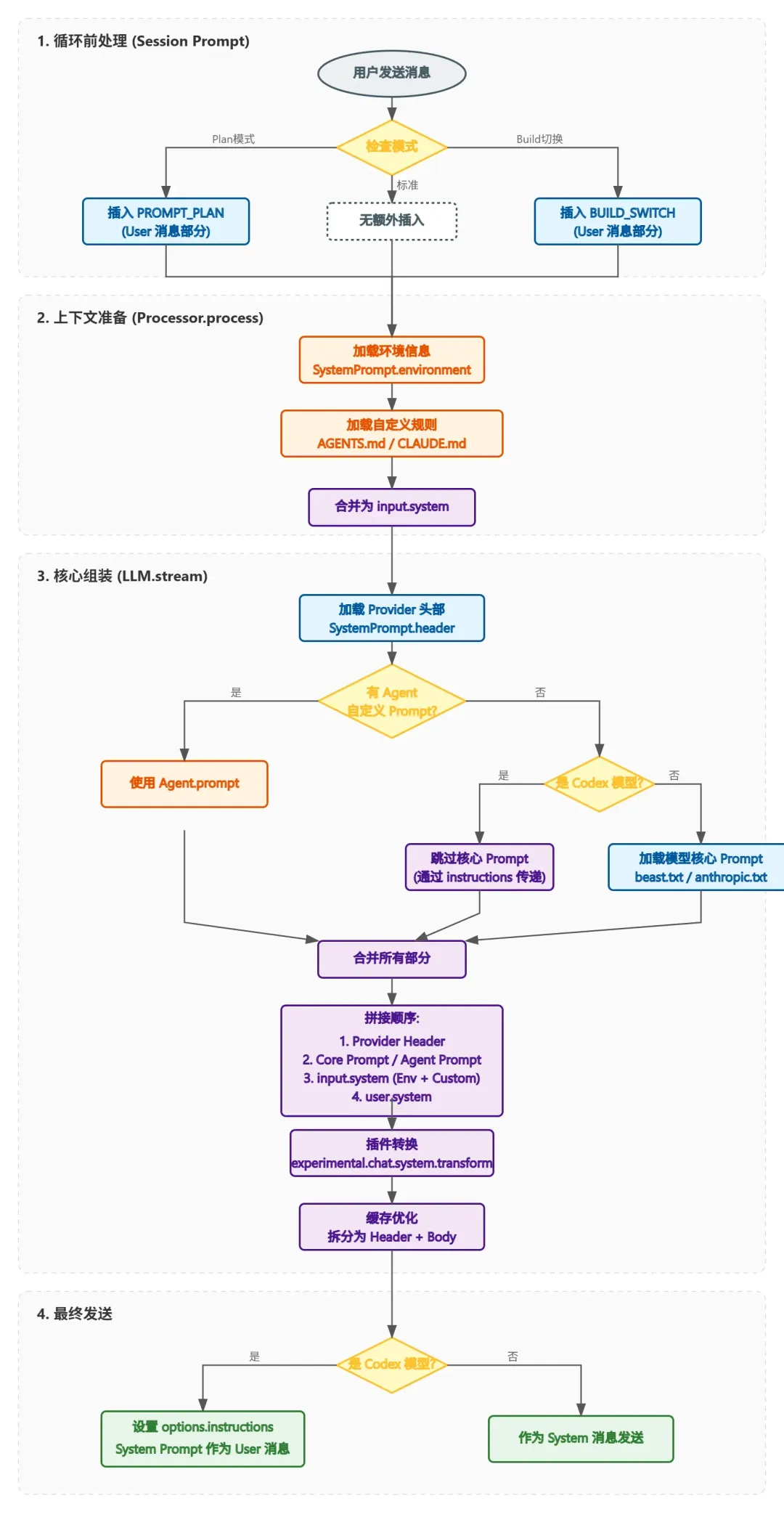
提示词决定了 AI 到底能不能听懂人话。OpenCode 的处理方式很有意思,它没有把所有东西塞进一个大字符串,而是搞了一套分层结构。
这篇文章我们直接拆解它的源码,看看它是怎么把环境信息、用户规则和核心指令组装在一起的。
实际场景:它到底在干什么?
先看几个实际场景,弄清楚系统到底在后台干了什么。
1. 标准对话
也就是你直接让它干活,比如”帮我写个登录页”。
这时候 OpenCode 会做几件事:
- 搜集情报
:它会去读你的当前目录、Git 状态、操作系统版本。 - 找规矩
:看看项目根目录下有没有 AGENTS.md,或者全局配置里有没有自定义规则。 - 选模板
:如果你用的是 GPT-4o,它就加载 beast.txt;如果是 Claude 3.5,就用anthropic.txt。 - 打包发送
:把上面这些信息拼在一起,丢给 LLM。
2. Plan 模式(只读规划)
如果你不想让 AI 乱改代码,只让它出方案,就会进入这个模式。
系统会自动插入一段 PROMPT_PLAN。这段话里写死了”只读约束”,禁止 AI 调用任何写文件的工具。这时候 AI 就只能看代码、写文档,动不了你的源文件。
3. 加载项目规范
很多时候我们需要 AI 遵守特定的代码风格。你可以在项目根目录放一个 AGENTS.md:
# 项目特定规则- 必须用 TypeScript 严格模式OpenCode 构建提示词时会往上级目录找这个文件,找到了就把它塞进 System Prompt 里。
搞清楚了表面流程,再看代码实现。
提示词文件都在哪?
都在
packages/opencode/src/session/prompt/下面,全是.txt文件。简单粗暴,但好维护。核心文件清单
针对不同模型,OpenCode 准备了不同的”人设”:
anthropic.txt
– Claude 系列专用。 beast.txt
– GPT 系列(包括 o1、o3)专用。名字起得挺野,强调自主解决问题。 codex.txt
– GPT-5 专用。 plan.txt
– 规划模式专用。 build-switch.txt
– 告诉 AI “可以开始写代码了”。
这些文件在编译时直接 import 进来,不是运行时读文件的,速度快一点。
代码怎么组装 Prompt?
核心逻辑在 packages/opencode/src/session/system.ts 里的 SystemPrompt 命名空间。它用四个函数来拼凑最终的提示词。
1. header():处理兼容性
export function header(providerID: string) {if (providerID.includes("anthropic")) return [PROMPT_ANTHROPIC_SPOOF.trim()]return []主要是为了伺候 Anthropic 的模型,给它加个特定的头,防止它”水土不服”。
2.
provider():选核心指令export function provider(model: Provider.Model) {if (model.api.id.includes("gpt-") || model.api.id.includes("o1"))return [PROMPT_BEAST]if (model.api.id.includes("claude")) return [PROMPT_ANTHROPIC]return [PROMPT_ANTHROPIC_WITHOUT_TODO]这里就是根据你选的模型来定”调子”。GPT 用
PROMPT_BEAST,Claude 用PROMPT_ANTHROPIC。不同模型”口味”不一样,得喂不同的 Prompt。3.
environment():告诉 AI 它在哪export async function environment() {const project = Instance.projectreturn [[`Here is some useful information about the environment you are running in:`,`<env>`,` Working directory: ${Instance.directory}`,` Is directory a git repo: ${project.vcs === "git" ? "yes" : "no"}`,` Platform: ${process.platform}`,` Today's date: ${newDate().toDateString()}`,`</env>`,// ...].join("\n"),]把当前目录、Git 状态、日期这些信息塞进去。这样 AI 才知道自己在干嘛,而不是在瞎猜。
4.
custom():加载你的私货export async function custom() {// ...// 1. 查找本地文件(向上查找 AGENTS.md, CLAUDE.md 等)// 2. 查找全局文件 (~/.claude/CLAUDE.md 等)// ...这一步负责找
AGENTS.md或者CLAUDE.md。它会先找项目目录,再找全局目录。你想让 AI 每次都用中文回答,或者必须写单元测试,就写在这些文件里。什么时候加载?
主要分两步:
1. 循环前注入 (
insertReminders)在进入对话循环之前,先检查状态。
- Plan 模式
:直接插入 PROMPT_PLAN,锁死文件修改权限。 - Build 模式
:如果是从 Plan 切过来的,插入 BUILD_SWITCH,告诉 AI “好了,动手吧”。
2. 组装 (stream 函数)
真正拼字符串是在 llm.ts 里。顺序很重要,优先级从高到低:
- Header (Provider 头部)
- 核心指令 (Agent 自定义 或
provider()选出来的模板) - Input System (外面传进来的)
- Environment (环境信息)
- Custom (
AGENTS.md等) - 插件修改 (最后给插件一个机会改写)
缓存优化
OpenCode 把 System Prompt 拆成了两截:Header + Body。
3031323334// 保持两部分结构以提升缓存命中率if (system.length > 2 && system[0] === header) {const rest = system.slice(1)system.length = 0system.push(header, rest.join("\n"))这么做是为了省钱省时间。Header 通常是不变的,可以被 LLM 的 KV Cache 缓存住。Body(环境信息、自定义规则)是动态的,每次重新算。
总结一下
OpenCode 的这套设计其实就三个词:分层、缓存、可扩展。
它没有把 Prompt 当成一段死的文本,而是当成一个可以组装的程序。静态的归静态,动态的归动态,既方便维护,又能利用缓存省点 Token。
给你的建议:
别浪费了这个机制。在项目根目录建个
AGENTS.md,把你的代码规范写进去。AI 真的会听。相关文件:
-
SystemPrompt 实现: packages/opencode/src/session/system.ts -
提示词加载逻辑: packages/opencode/src/session/llm.ts -
循环前注入: packages/opencode/src/session/prompt.ts -
提示词文件目录: packages/opencode/src/session/prompt/*.txt
