 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:Opus 干重活 Haiku 打杂,模型调度的精打细算
💡 阅读前记得关注+星标,及时获取更新推送
「Claude Code 源码揭秘」系列的第十二篇,上一篇《Claude Code 源码揭秘:11 个部分动态拼接,System Prompt 不是写死的》,说的是 11 个部分怎么拼接成最终的提示词。但 prompt 最终要发给哪个模型?这个选择也有讲究。

用 Claude Code 的时候,你可能注意到它有时候反应快,有时候慢一点但回答更深入。
这不是网络波动,而是它在背后切换不同的模型。
探索代码库的时候用 Haiku,速度快成本低;规划复杂任务的时候用 Sonnet,能力和成本平衡;真正需要深度思考的时候上 Opus,虽然贵但效果好。
翻 src/models/ 目录,发现这套模型管理系统比想象中复杂——不只是「选个模型调 API」那么简单,还有 Thinking 预算控制、自动回退、成本预警、使用统计… 一整套精打细算的机制。
我之前做过一个多模型网关,给不同业务线分配不同的模型配额。当时最头疼的就是成本控制——有的业务线一天烧掉几千块,老板看账单脸都绿了。后来加了预警机制和自动降级,才算控制住。Claude Code 这套设计,思路是一样的,但做得更细致。
你平时用的是什么?怎么改?
如果你平时用 Claude Code 没有特意调整过模型和预算,那你用的就是默认值:
// 源码里的默认配置 (src/config/index.ts)const DEFAULT_CONFIG = { model: 'sonnet', // 默认 Sonnet,平衡之选 maxTokens: 8192, // 默认最大输出 8192 tokens temperature: 1, // 默认温度 1 maxRetries: 3, // 默认重试 3 次 // ... 其他默认值};CLI 参数也有默认值:
// src/cli.ts.option('-m, --model <model>', 'Model for the current session', 'sonnet').option('--max-tokens <tokens>', 'Maximum tokens for response', '8192').option('--max-budget-usd <amount>', 'Maximum dollar amount for API calls (only with --print)')注意 --max-budget-usd 这个预算参数只在 --print 模式(非交互模式)下有效。交互模式下没有预算限制——所以你平时用的时候,其实是「敞开了花」。
四种修改方式,按优先级从低到高
源码里定义了完整的配置优先级链(src/config/index.ts 第 320-328 行):
// 官方优先级链(从低到高):// 1. default (内置默认值)// 2. userSettings (~/.claude/settings.json)// 3. projectSettings (.claude/settings.json)// 4. localSettings (.claude/settings.local.json - 机器特定)// 5. envSettings (环境变量)// 6. flagSettings (命令行标志)// 7. policySettings (企业策略 - 最高优先级)这意味着:命令行参数 > 环境变量 > 本地配置 > 项目配置 > 用户配置 > 默认值。
方式一:命令行参数(临时生效,最高用户可控优先级)
# 切换模型claude -m opus "帮我分析这个复杂的架构问题"claude -m haiku "简单查一下这个函数在哪"# 调整输出长度claude --max-tokens 16384 "生成一份详细的技术文档"# 设置预算上限(仅 --print 模式)claude -p --max-budget-usd 5 "分析这个代码库"# 指定回退模型(主模型过载时自动切换)claude --fallback-model haiku "这个任务"这是最直接的方式,但只对当前会话有效。
方式二:配置文件(持久化)
用户级配置 ~/.claude/settings.json:
{ "model": "opus", "maxTokens": 16384, "temperature": 0.8}项目级配置 .claude/settings.json(会覆盖用户级):
{ "model": "sonnet", "maxTokens": 8192}本地配置 .claude/settings.local.json(机器特定,应加入 .gitignore):
{ "model": "haiku"}源码里会自动把 settings.local.json 加入 .gitignore:
private ensureGitignore(claudeDir: string): void { const patterns = [ '.claude/settings.local.json', '# Claude Code local settings (machine-specific)', ]; // 自动添加到 .gitignore}方式三:环境变量
export CLAUDE_CODE_MAX_OUTPUT_TOKENS=16384目前环境变量支持的配置项不多,主要是 tokens 和一些开关。
方式四:企业策略(最高优先级,用户无法覆盖)
如果你在企业环境,管理员可以通过 ~/.claude/managed_settings.json 强制设置:
{ "enforced": { "model": "sonnet", "maxTokens": 8192 }, "disabledFeatures": ["bypassPermissions"]}enforced 里的配置用户无法覆盖,即使用命令行参数也不行。这是给企业做成本控制用的。
什么时候该调整?
几个典型场景:
-
• 需要深度思考、复杂推理:切 Opus。比如架构设计、代码重构决策、复杂 bug 分析。 -
• 快速查询、简单任务:切 Haiku。比如「这个函数在哪」「这个变量什么意思」。 -
• 日常开发:用默认的 Sonnet 就够了,平衡能力和成本。 -
• 项目有特殊要求:在 .claude/settings.json里配置,让团队统一。 -
• 跑批量任务、自动化脚本:用 --print模式 +--max-budget-usd设预算上限,避免失控。
我自己的习惯是:大部分时候用默认的 Sonnet,遇到复杂问题临时 -m opus,探索代码库的时候让系统自动用 Haiku(Explore Agent 默认就是 Haiku)。这样既不浪费钱,又能在需要的时候用上最强的模型。
三大模型家族
Claude Code 支持三个模型系列,每个系列有多个版本:
const KNOWN_MODELS = [ // Opus 系列 —— 最强大 { id: 'claude-opus-4-5-20251101', displayName: 'Opus 4.5', aliases: ['opus', 'opus-4-5', 'claude-opus-4-5'], contextWindow: 1_000_000, // 100万 tokens maxOutputTokens: 32768, supportsThinking: true, supportsVision: true, supportsPdf: true, family: 'opus', }, // Sonnet 系列 —— 平衡之选 { id: 'claude-sonnet-4-5-20250929', displayName: 'Sonnet 4.5', contextWindow: 1_000_000, maxOutputTokens: 16384, supportsThinking: true, family: 'sonnet', }, // Haiku 系列 —— 快速轻量 { id: 'claude-haiku-4-5-20251001', displayName: 'Haiku 4.5', contextWindow: 200_000, // 20万 tokens,比其他小 maxOutputTokens: 8192, supportsThinking: false, // 不支持 Thinking family: 'haiku', },];三个家族的定位很清晰:
Opus —— 旗舰级,上下文窗口最大(100万 tokens),输出最长(32K),支持所有高级功能。适合复杂推理、长文档分析、需要深度思考的任务。缺点是贵,响应也慢一些。
Sonnet —— 主力级,能力和成本平衡。大部分任务用它就够了。
Haiku —— 轻量级,上下文窗口只有 20 万,不支持 Thinking。但速度快、成本低,适合简单任务。
注意 Haiku 不支持 Thinking 模式。这是个重要的限制,后面会讲到。
别名解析
你可以用简写来指定模型:
resolveAlias('opus') // → 'claude-opus-4-5-20251101'resolveAlias('sonnet') // → 'claude-sonnet-4-5-20250929'resolveAlias('haiku') // → 'claude-haiku-4-5-20251001'resolveAlias('opus-4-5') // → 'claude-opus-4-5-20251101'写 opus 比写完整的模型 ID 方便多了。系统会自动解析成最新版本。
子代理的模型选择
上一篇聊子代理系统的时候提到,不同类型的子代理用不同的模型。默认配置是这样的:
const AGENT_MODEL_DEFAULTS = { 'general-purpose': 'sonnet', // 通用任务:中等能力 'Explore': 'haiku', // 代码探索:快速轻量 'Plan': 'sonnet', // 架构规划:中等能力 'claude-code-guide': 'haiku', // 文档查询:快速轻量 'statusline-setup': 'haiku', // 配置任务:快速轻量};Explore 代理只是搜索文件、读取代码,不需要复杂推理,用 Haiku 就够了。Plan 代理要做架构设计,需要更强的能力,用 Sonnet。
这个设计的精髓是:用最便宜的模型完成任务。不是所有任务都需要 Opus,杀鸡不用牛刀。
关于模型自动切换的两个误解
有人问:计划模式会自动切换模型吗?比如我用 Sonnet 开始对话,切换到计划模式后模型会变吗?
答案是不会。看 planmode.ts 的实现:
// EnterPlanMode 工具的核心逻辑toolPermissionContext.mode = 'plan';计划模式只是改变了权限上下文的 mode 值,跟模型选择完全是两码事。你进入计划模式之前用的是 Sonnet,进去之后还是 Sonnet。计划模式的本质是改变工具的行为权限(比如限制直接写代码,只允许做规划),不会触发模型切换。
另一个常见问题:简单任务会自动切换到 Haiku 吗?
也不会。模型的切换是跟着 Agent 类型 走的,不是跟着任务难度走的。你让它探索代码库,它启动 Explore Agent,这个 Agent 默认用 Haiku;你让它做规划,它启动 Plan Agent,默认用 Sonnet;主对话始终用你指定的模型(默认 Sonnet)。
不存在「Claude Code 觉得这个任务简单就自动降级到 Haiku」这种智能调度。当前版本的模型调度策略是静态映射——按 Agent 类型匹配,不是动态评估任务复杂度。虽然代码里定义了 ModelSelectionStrategy 有 cost-optimized、performance-optimized、balanced 几种策略,但实际实现还是比较简单的预设分工。
我之前做的多模型网关,一开始没有这种分级策略,所有请求都走最贵的模型。结果一个月账单下来,老板问我是不是在挖矿。后来按业务类型分配模型,成本降了 60%。
模型选择还有三层继承机制:
getModelForAgent(agentType, userModel?, globalDefault?): 用户明确指定 > Agent 类型覆盖 > Agent 类型默认 > 全局默认 > 系统默认 (sonnet)用户说「用 opus」,那就用 opus,覆盖所有默认配置。用户没说,就按 Agent 类型的默认值来。
还有三种选择策略:
type ModelSelectionStrategy = 'cost-optimized' | 'performance-optimized' | 'balanced';cost-optimized 模式下,所有 Agent 都用 Haiku,省钱。performance-optimized 模式下,通用任务和规划任务用 Opus,其他用 Sonnet,效果好但贵。balanced 是默认配置,折中。
接入第三方模型时,子代理会出问题吗?
有人用 Kimi K2 接入 Claude Code,问我:子代理默认用 haiku/sonnet,这些 Claude 的模型 ID 发给 Kimi API 不会报错吗?
一开始我也觉得会出问题。代码里写死了:
const AGENT_MODEL_DEFAULTS = { 'Explore': 'haiku', // 解析后变成 'claude-haiku-4-5-20251001' 'Plan': 'sonnet', // 解析后变成 'claude-sonnet-4-5-20250929' // ...};发给 Kimi API 一个 claude-sonnet-4-5-20250929,它能认识?
实际测试发现:能正常工作。
原因有两层兼容机制——
第一层:客户端环境变量覆盖
官方 Claude Code 支持这些环境变量来覆盖默认模型:
ANTHROPIC_DEFAULT_OPUS_MODEL="kimi-k2-thinking-turbo"ANTHROPIC_DEFAULT_SONNET_MODEL="kimi-k2-thinking-turbo"ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi-k2-thinking-turbo"CLAUDE_CODE_SUBAGENT_MODEL="kimi-k2-thinking-turbo" # 专门给子代理用的配了这些环境变量,resolveAlias('sonnet') 就不会变成 Claude 的模型 ID,而是你配置的 Kimi 模型。
第二层:服务端模型映射
即使你没配这些环境变量,Kimi 的 /anthropic 兼容端点也会在服务端做模型 ID 映射:
客户端发送: model: "claude-sonnet-4-5-20250929" ↓Kimi API 网关识别到这是 Claude 模型 ID ↓自动映射到: kimi-k2-xxx ↓正常返回结果这是个聪明的设计。作为兼容 Anthropic API 的第三方服务,不做这层映射的话,用户每次都得配一堆环境变量,体验太差。
所以如果你用第三方 API(如 Kimi、DeepSeek 的兼容端点),不用太担心子代理模型的问题——服务端通常会兜底处理。当然,为了保险起见,还是建议配上那几个环境变量,客户端服务端双重保障。
Thinking 模式
Thinking 是 Claude 的一个高级功能——让模型在回答之前先「思考」一番,输出思考过程。
const DEFAULT_THINKING_CONFIG = { enabled: false, // 默认关闭 budgetTokens: 10000, // 默认 1 万 tokens 预算 showThinking: false, // 是否显示思考过程 timeout: 120000, // 2 分钟超时};为什么要有「预算」?因为 Thinking 是按 token 计费的,不设上限的话,模型可能会「想」很久,花很多钱。
预算推荐值根据任务复杂度:
recommendBudget(complexity): simple: 2000 tokens // 简单任务 medium: 10000 tokens // 中等任务 complex: 50000 tokens // 复杂任务复杂任务给 5 万 tokens 的思考预算,简单任务给 2000 就够了。
不是所有模型都支持 Thinking:
supportsThinking(modelId): Opus 4.5: true,预算范围 1024-128000 Sonnet 4.5: true,预算范围 1024-128000 Haiku 4.5: false // 不支持!Haiku 不支持 Thinking,这是它便宜的代价之一。如果你的任务需要深度思考,就不能用 Haiku。
API 请求的时候,Thinking 参数是这样传的:
{ thinking: { type: 'enabled', budget_tokens: 10000 }}响应里会包含思考过程和实际使用的 tokens:
{ thinking: "让我分析一下这个问题...", thinkingTokens: 8456, // 实际用了 8456 tokens budgetExhausted: false, // 没超预算}如果实际使用量接近预算(>=95%),说明思考被截断了,可能需要更大的预算。
模型回退机制
API 不是 100% 可用的。高峰期可能过载,网络可能抖动。Claude Code 有一套回退机制:
async executeWithFallback(operation) { // 1. 尝试主模型,最多重试 maxRetries 次 for (let attempt = 0; attempt < maxRetries; attempt++) { try { return await operation(); } catch (error) { if (isRetryable(error)) { // 指数退避:delay = baseDelay * 2^attempt await sleep(baseDelay * Math.pow(2, attempt)); continue; } throw error; } } // 2. 主模型都失败了,切换到回退模型 this.switchToFallback(); return await operation(); // 用回退模型重试}可重试的错误类型:
const RETRYABLE_ERRORS = [ 'overloaded_error', // 服务器过载 'rate_limit_error', // 限流 'api_error', // API 错误 'timeout', // 超时 'ECONNRESET', // 连接重置 'ETIMEDOUT', // 连接超时 'capacity_exceeded', // 容量超限 'model_unavailable', // 模型不可用];指数退避是个经典策略——第一次重试等 1 秒,第二次等 2 秒,第三次等 4 秒… 避免在服务器已经过载的时候继续加压。
回退模型通常是「降一级」的选择:Opus 挂了用 Sonnet,Sonnet 挂了用 Haiku。
模型切换会被记录:
interface ModelSwitchEvent { fromModel: string; toModel: string; reason: 'fallback' | 'manual' | 'capacity'; timestamp: number; error?: string;}这些记录可以用来分析回退率,看看哪个模型最不稳定。
我之前做支付系统的时候,也有类似的通道切换机制。主通道挂了切备用通道,备用通道挂了走人工审核。没有这些兜底,双十一那种流量高峰根本扛不住。
成本控制
这是我最喜欢的部分。Claude Code 有一套完整的成本预警机制。
首先是定价表:
const PRICING = { 'claude-opus-4-5-20251101': { input: 15, // 每百万 tokens 15 美元 output: 75, // 每百万 tokens 75 美元 cacheRead: 1.5, // 缓存读取只要 10% thinking: 75, // Thinking 按输出价格计费 }, // Sonnet 和 Haiku 更便宜};然后是配额管理:
quotaManager.setLimit('cost', 10.0); // 设置 10 美元限制设置限制后,系统会自动生成四级预警:
50% ($5.00) → info 级别80% ($8.00) → warning 级别95% ($9.50) → critical 级别100% ($10) → exceeded 级别,停止执行可以注册回调,在达到阈值时收到通知:
quotaManager.onThresholdReached((alert, status) => { console.log(`成本预警:已使用 ${status.percentage}%`);});quotaManager.onLimitExceeded((type, status) => { throw new Error('成本超限,停止执行');});随时可以查询当前状态:
const status = quotaManager.getBudgetStatus('cost');// {// type: 'cost',// current: 3.45,// limit: 10,// percentage: 34.5,// remaining: 6.55,// alertLevel: 'info',// exceeded: false// }除了成本,还可以限制 tokens 总数和 API 调用次数:
quotaManager.setLimit('tokens', 1000000); // 100 万 tokensquotaManager.setLimit('requests', 100); // 100 次调用这套机制对企业用户特别重要。我之前帮一个客户做 AI 应用,他们的需求是「每个用户每天最多花 1 块钱」。如果没有这种配额控制,一个用户就能把整个月的预算烧光。
使用统计
Claude Code 会统计各种使用数据:
interface ModelUsageStats { inputTokens: number; outputTokens: number; cacheReadTokens: number; // 缓存命中的 tokens cacheCreationTokens: number; thinkingTokens: number; webSearchRequests: number; costUSD: number; contextWindowUsage: number; // 上下文窗口使用率 apiCalls: number; apiDurationMs: number; toolDurationMs: number;}缓存是个省钱的好东西。缓存读取的成本只有正常输入的 10%。如果你的 prompt 有很多重复的部分(比如系统提示词),缓存能省不少钱。
性能指标也有计算:
getPerformanceMetrics(): averageApiLatency: API 平均延迟 averageToolLatency: 工具平均延迟 tokensPerSecond: 吞吐量 cacheHitRate: 缓存命中率这些数据可以帮你优化使用策略。比如发现缓存命中率很低,可能是 prompt 变化太频繁,可以考虑稳定化。
成本计算实例
举个具体的例子。假设一个复杂任务:
输入:50000 tokens输出:10000 tokensThinking:23456 tokens模型:Opus 4.5成本计算:
输入成本 = 50000 / 1000000 * 15 = $0.75输出成本 = 10000 / 1000000 * 75 = $0.75Thinking 成本 = 23456 / 1000000 * 75 = $1.76总成本 = $3.26Thinking 占了一半多的成本!这就是为什么要控制 Thinking 预算。
如果同样的任务用 Haiku(假设它能完成),成本大概只有 Opus 的十分之一。但 Haiku 不支持 Thinking,复杂任务可能完成不了。这就是成本和能力之间的权衡。
整个模型管理的架构
把各个模块串起来看:
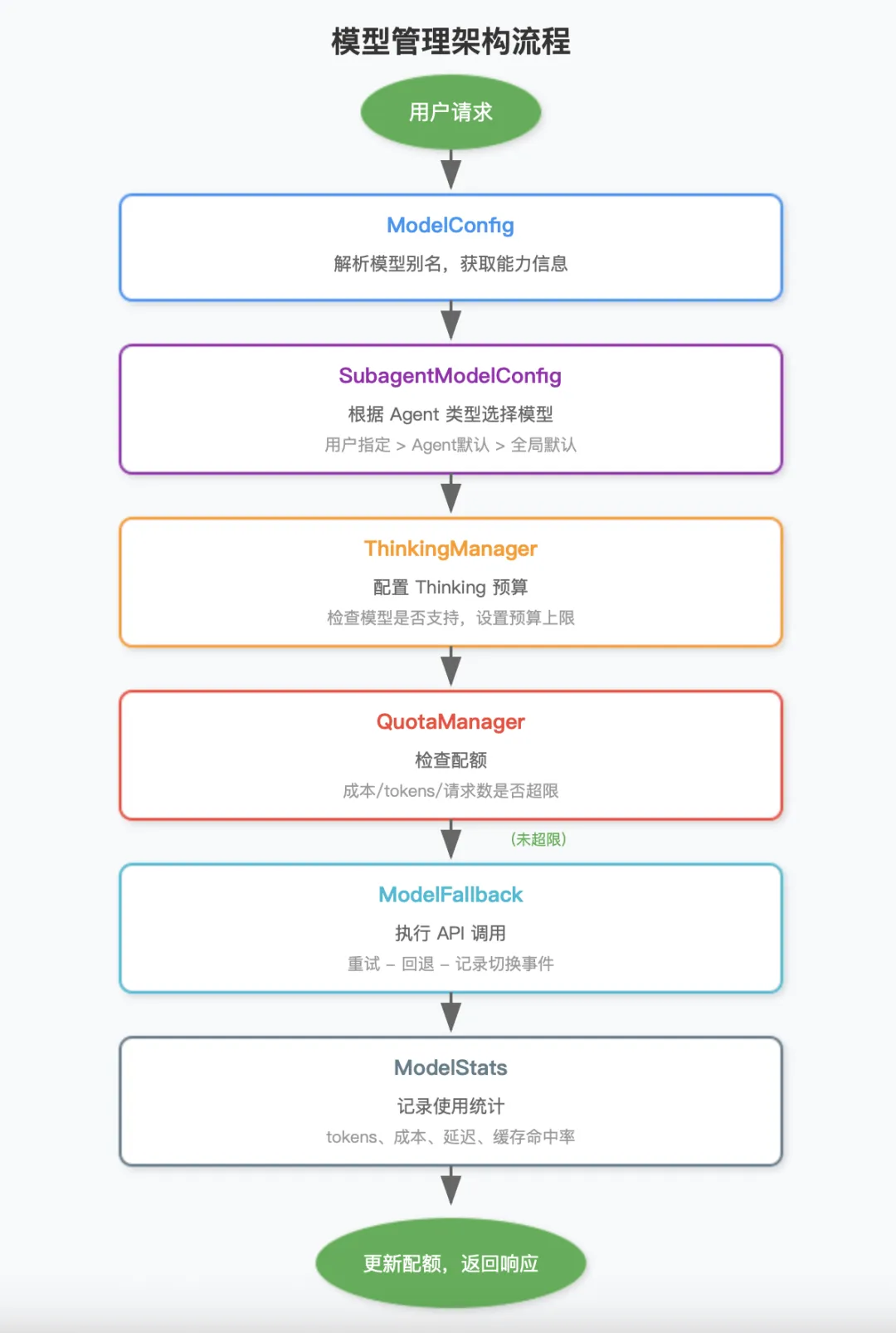
每一层都有自己的职责,组合起来形成一个完整的模型管理体系。
翻完这部分代码,我最大的感受是:模型管理不只是选个模型那么简单。
要考虑成本——不同模型价格差十倍,不能无脑用最贵的。要考虑能力——Haiku 不支持 Thinking,有些任务完成不了。要考虑稳定性——API 可能挂,需要回退机制。要考虑监控——使用量、成本、性能都要跟踪。
Claude Code 这套系统把这些都考虑到了,而且设计得很优雅。分层清晰,各司其职,可配置性强。
下一篇聊 MCP 协议。Claude Code 是怎么通过 MCP 连接外部工具的?那个「服务器」是什么意思?配置文件怎么写?
本文基于 Claude Code 2.0.76 版本源码分析,主要文件:src/models/config.ts、src/models/thinking.ts、src/models/fallback.ts、src/models/quota.ts。
