夜雨聆风
夜雨聆风





Flink Core API 源码深度解析

Flink Core API 源码深度解析
模块: flink-core-api版本: Apache Flink 2.2.0仓库: https://github.com/apache/flink整理时间: 2026-01-25
文章概述
本文深入分析 Flink 的 flink-core-api 模块。作为 Flink API 层的核心基础模块,它定义了整个流处理框架的接口契约,是理解 Flink 整体架构的关键入口。
通过本文,你将了解到:
-
• flink-core-api 的设计定位与职责边界 -
• 核心接口体系的设计思想 -
• 状态接口的分层架构 -
• 函数接口的设计模式 -
• 水印机制在 API 层的抽象
一、模块定位与职责
1.1 模块简介
flink-core-api 是 Apache Flink 的核心 API 模块,它定义了流处理框架的公共接口,是整个 Flink 体系的”宪法”。该模块本身不包含任何实现逻辑,完全由接口和抽象类组成,体现了”面向接口编程”的设计原则。
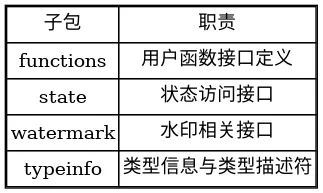
从包结构来看,该模块主要包含以下核心子包:
表 1-1:flink-core-api 子包职责表
1.2 在 Flink 架构中的位置
图 1-1:flink-core-api 架构层次图
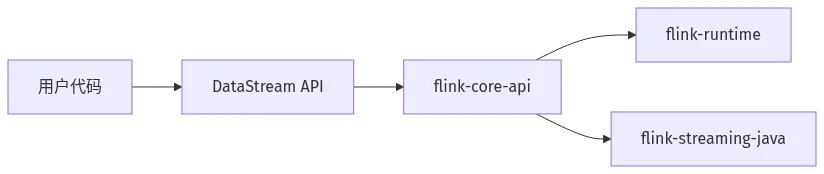
从架构层次来看,flink-core-api 处于承上启下的关键位置:
-
• 向上:为 DataStream API、Table API 提供基础接口 -
• 向下:定义运行时必须实现的服务契约 -
• 横向:为所有连接器和库提供统一的抽象
1.3 设计原则
通过代码分析,该模块体现了以下设计原则:
-
1. 接口隔离原则(ISP):每个接口职责单一,不强迫实现类依赖不使用的方法 -
2. 依赖倒置原则(DIP):高层模块依赖抽象,不依赖具体实现 -
3. 开闭原则(OCP):通过接口扩展功能,对修改关闭 -
4. 单一职责原则(SRP):每个接口只定义一类行为
二、整体架构设计
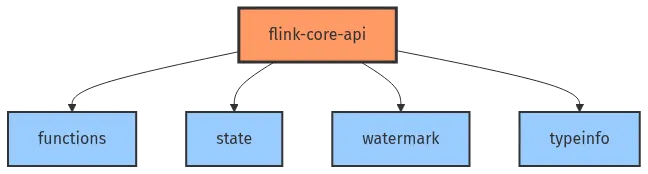
2.1 核心子包划分
flink-core-api 的架构可以概括为”四大支柱”:
图 2-1:flink-core-api 四大支柱架构
2.2 模块架构图
图 2-2-1:flink-core-api 模块架构图
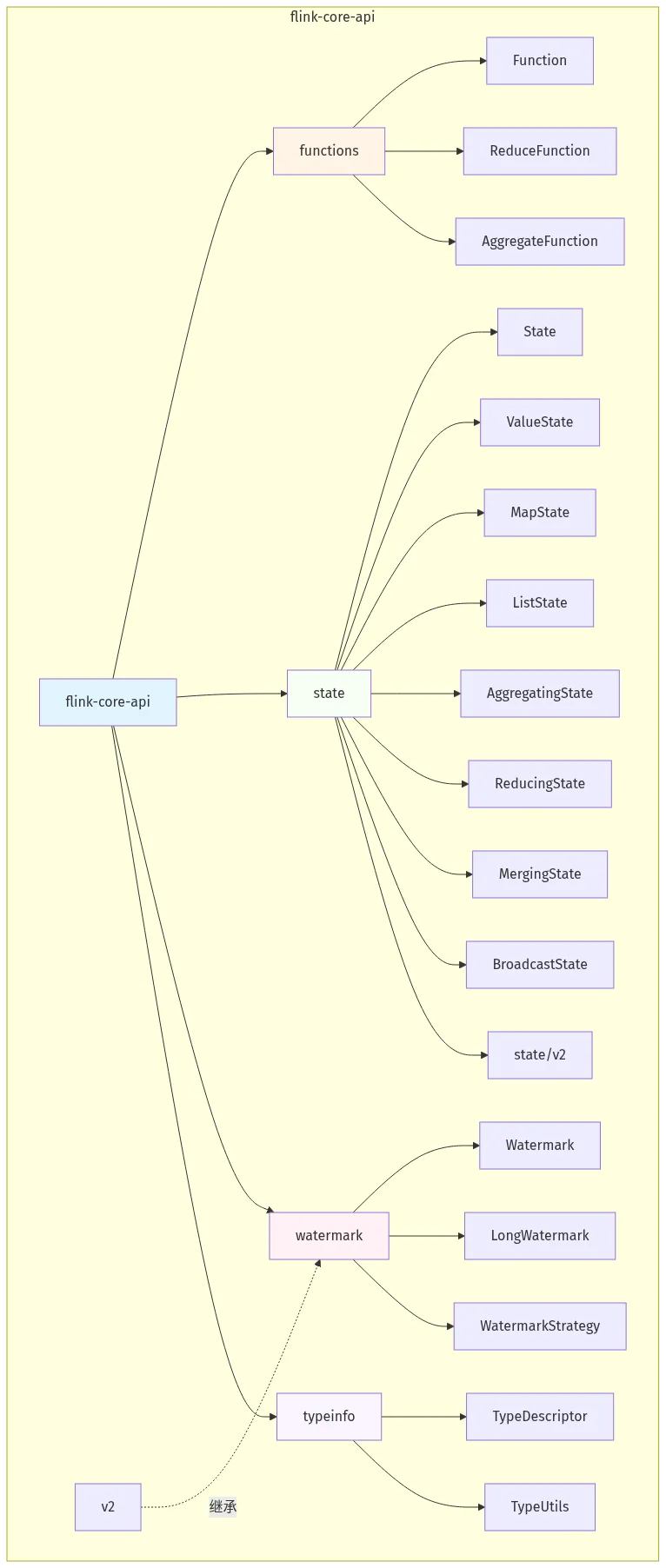
图 2-2-2:flink-core-api 核心接口类图

2.3 接口分层架构
从接口的继承层次来看,flink-core-api 采用了精巧的分层设计:
图 2-3:Function 接口层次结构
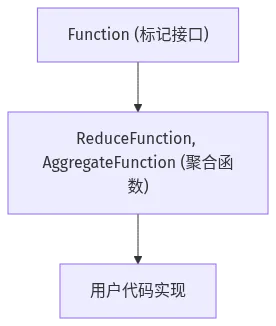
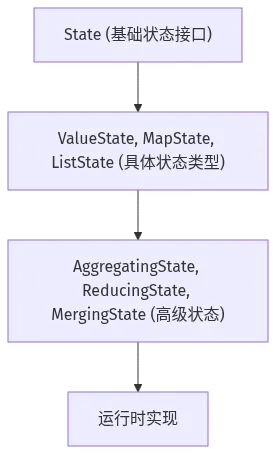
图 2-4:State 接口层次结构
这种分层设计的优势:
-
• 渐进式复杂度:从简单的标记接口到复杂的状态抽象 -
• 向后兼容:v2 接口支持演进,同时保持 v1 接口稳定 -
• 扩展性强:新的状态类型可以在不破坏现有接口的情况下添加
三、函数接口体系
3.1 标记接口设计
Function.java 是整个函数体系的根基:
@Publicpublic interface Function extends java.io.Serializable {}这个接口的设计非常巧妙:
-
1. 空接口(Marker Interface):不定义任何方法 -
2. 可序列化:继承 Serializable,支持分布式计算 -
3. Lambda 友好:保持为 SAM(Single Abstract Method)接口
为什么设计为空接口?
空接口允许子接口成为 SAM 接口,从而支持 Java 8 Lambda 表达式和匿名类。如果 Function 接口包含任何方法,所有子接口都将继承该方法,不再是 SAM 接口。
3.2 ReduceFunction 接口
ReduceFunction 定义了归约操作的契约:
@Public@FunctionalInterfacepublic interface ReduceFunction<T> extends Function, Serializable { T reduce(T value1, T value2) throws Exception;}设计特点分析:
-
1. 二合一操作: reduce(T value1, T value2)将两个值合并为一个 -
2. 结合律友好:要求用户函数满足结合律,以便并行优化 -
3. 异常容忍:允许抛出异常,框架会处理失败重试 -
4. 泛型设计: <T>支持任意类型的数据流
归约过程可视化:
图 3-1:flink-core-api 归约过程可视化

3.3 函数接口设计模式
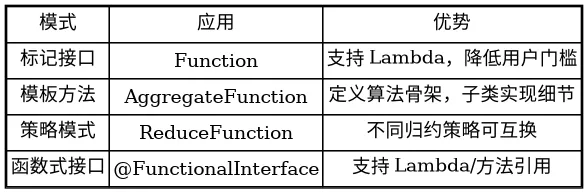
flink-core-api 的函数接口采用了以下设计模式:
表 3-1:flink-core-api 函数接口设计模式表
四、状态接口架构
4.1 State 基础接口
State 是所有状态接口的根基:
@PublicEvolvingpublic interface State { void clear();}这个接口的设计极简,只定义了 clear() 方法:
-
• 语义明确:清除当前 key 对应的状态 -
• 职责单一:不做假设,留给子接口扩展
4.2 状态类型层次结构
flink-core-api 定义了丰富的状态类型,形成了完整的状态体系:
图 4-1:flink-core-api 状态类型类图
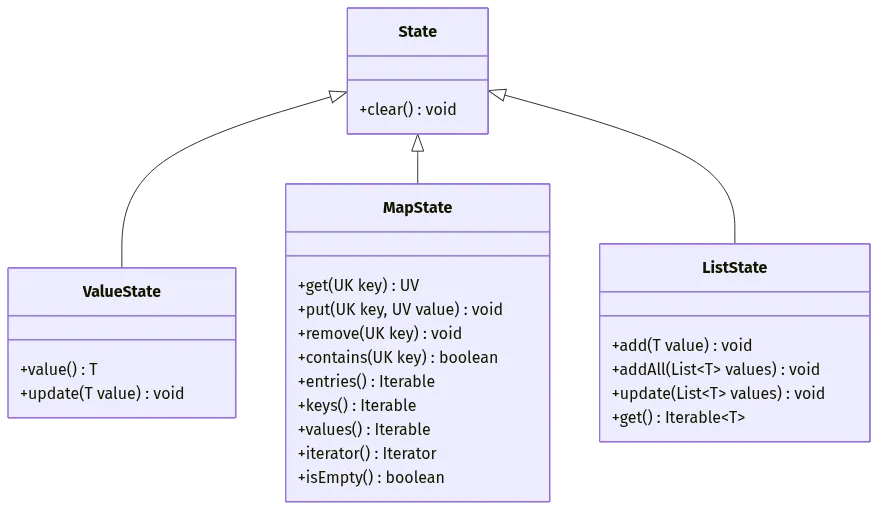
4.3 核心状态类型详解
ValueState:单值状态
使用场景:存储单个值(如计数器、配置项)
ValueState<Long> count = context.getState(valueStateDescriptor);count.update(count.value() + 1);设计亮点:
-
• 泛型 <T>支持任意类型 -
• value()返回当前值(未设置时返回 null) -
• update()更新值(设为 null 会删除状态)
MapState:键值对状态
使用场景:存储映射关系(如窗口去重、侧输出累积)
MapState<String, Integer> map = context.getState(mapStateDescriptor);map.put(key, map.get(key) + 1);设计亮点:
-
• 支持完整的 Map 操作:get, put, remove, contains -
• 提供 Iterable 视图:entries(), keys(), values() -
• 支持批量操作:putAll(Map) -
• 提供 Iterator:用于遍历(注意:不要在 iterator 中修改状态)
ListState:列表状态
使用场景:存储元素序列(如窗口数据累积)
ListState<String> list = context.getState(listStateDescriptor);list.add("event1");list.addAll(Arrays.asList("event2", "event3"));设计亮点:
-
• 支持单个添加:add(T) -
• 支持批量添加:addAll(List) -
• 支持全量更新:update(List) -
• 提供 Iterable 视图:get()
4.4 高级状态接口
AggregatingState:聚合状态
用于累加器模式的聚合操作:
AggregatingState<IN, OUT> state = context.getState(descriptor);state.add(value1);state.add(value2);OUT result = state.get();设计思想:
-
• 用户只管 add(),框架负责聚合 -
• 分离”输入”与”聚合逻辑” -
• 支持增量聚合,适合窗口计算
ReducingState:归约状态
类似于 ReduceFunction,但是有状态的版本:
ReducingState<T> state = context.getState(descriptor);state.add(value1);state.add(value2);T result = state.get();与 AggregatingState 的区别:
-
• ReducingState: 输入输出类型相同<T> -
• AggregatingState: 输入输出类型不同<IN, OUT>
MergingState:合并状态
用于合并多个数据流的状态:
MergingState<IN, OUT> state = context.getState(descriptor);state.add(inputStream1Value);state.add(inputStream2Value);OUT result = state.get();典型应用场景:
-
• Union 多流合并 -
• Broadcast 连接 -
• 侧输出流
4.5 BroadcastState:广播状态
特殊的分布式状态,所有并行实例都能访问:
BroadcastState<String, String> bcState = context.getState(bcStateDescriptor);bcState.put(configKey, configValue);// 在其他算子中读取ReadOnlyBroadcastState<String, String> readOnly = context.getBroadcastState(bcStateDescriptor);String value = readOnly.get(configKey);设计特点:
-
• 所有并行实例共享同一份数据 -
• 支持动态更新(广播变量) -
• 提供只读视图: ReadOnlyBroadcastState
4.6 状态接口设计模式总结
表 4-1:flink-core-api 状态接口设计模式表
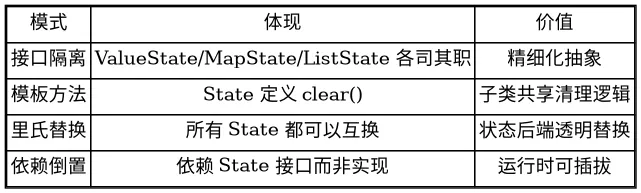
五、水印机制抽象
5.1 Watermark 接口
Watermark 定义了水印的基本契约:
@Experimentalpublic interface Watermark extends Serializable { String getIdentifier();}设计分析:
-
1. 实验性注解 @Experimental:表明这是一个演进中的接口 -
2. 唯一标识符: getIdentifier()用于区分不同类型的水印 -
3. 可序列化:支持分布式传递
为什么设计为通用接口?
Flink 2.0 开始支持多种类型的水印(事件时间水印、处理时间水印、自定义水印),统一的 Watermark 接口使扩展更加灵活。
5.2 LongWatermark:长整型水印
最常用的水印类型:
public interface LongWatermark extends Watermark { long getTimestamp();}设计特点:
-
• 时间戳类型:使用 long存储毫秒级时间戳 -
• 语义明确:代表事件时间或处理时间 -
• 高效比较:long 类型天然支持大小比较
5.3 水印传播机制
虽然 flink-core-api 只定义接口,但从接口设计可以推断出水印的传播机制:
图 5-1:flink-core-api 水印传播机制
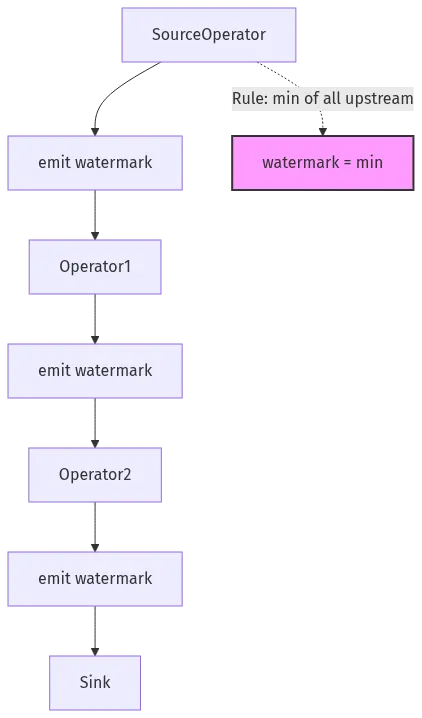
六、类型信息抽象
6.1 TypeDescriptor
TypeDescriptor 是 Flink 类型系统的核心抽象:
public interface TypeDescriptor extends Serializable { // 类型描述信息}设计目的:
-
• 统一描述数据类型 -
• 支持 SQL 类型到 Java 类型的映射 -
• 为类型推导提供基础
6.2 TypeUtils
提供类型操作的实用方法:
public class TypeUtils { // 类型转换、类型检查等}七、设计模式与架构亮点
7.1 使用的设计模式
1. 标记接口模式(Marker Interface)
体现:Function 接口
优势:
-
• 作为类型标签,标识”这是一个 Flink 函数” -
• 不增加实现负担 -
• 支持 Lambda 表达式
2. 函数式接口模式
体现:@FunctionalInterface 注解
优势:
-
• 支持 Lambda 表达式 -
• 支持方法引用 -
• 提升代码简洁度
3. 策略模式(Strategy Pattern)
体现:ReduceFunction 作为归约策略
优势:
-
• 用户自定义归约逻辑 -
• 框架统一调用 -
• 策略可互换
4. 模板方法模式(Template Method)
体现:AggregateFunction
优势:
-
• 定义算法骨架(createAccumulator → add → getResult) -
• 子类实现具体步骤 -
• 复用聚合逻辑
7.2 架构亮点
亮点1:渐进式复杂度
图 7-1:flink-core-api 渐进式复杂度
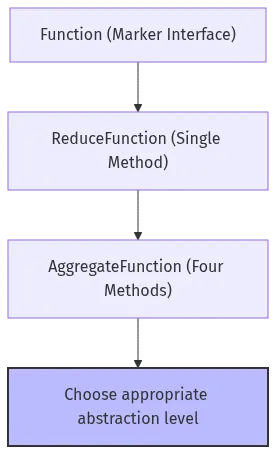
用户可以根据需求选择合适的抽象层次。
亮点2:状态接口分层
图 7-2:flink-core-api 状态接口分层
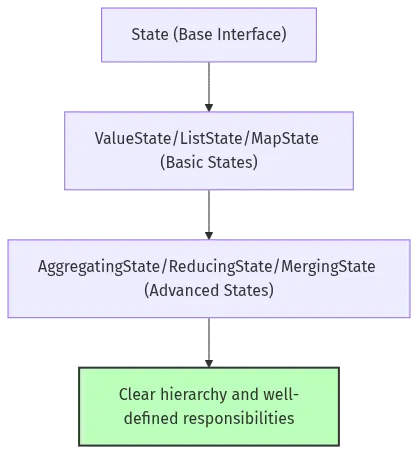
分层清晰,职责明确。
亮点3:v2 接口演进
在 state/v2/ 下保留 v2 版本接口,支持 API 演进:
// v1 接口ValueState<T> extends State// v2 接口StateFuture extends State // 支持异步状态操作向后兼容性:新旧接口并存。
7.3 可借鉴的设计
-
1. 空接口作为类型标记:配合 Lambda 使用 -
2. 单一方法接口:支持函数式编程 -
3. 接口继承层次:提供不同抽象层次 -
4. v2 包模式:API 演进不破坏向后兼容
八、性能与扩展性分析
8.1 性能考虑
接口设计的性能影响
虽然 flink-core-api 只是接口定义,但接口设计会影响运行时性能:
表 8-1:flink-core-api 性能影响表
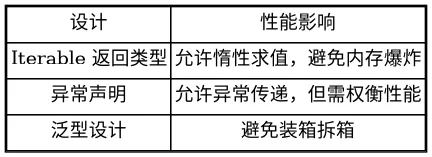
状态访问的性能考虑
从接口设计可以看出:
-
• ValueState.value()每次访问可能触发 IO -
• MapState.entries()返回 Iterable 而非 List,避免全量加载 -
• Iterator模式支持流式处理
8.2 扩展性设计
如何扩展新的状态类型?
// 1. 继承 State 接口public interface MyCustomState<T> extends State { T customOperation();}// 2. 在运行时实现public class MyCustomStateImpl<T> implements MyCustomState<T> { // 实现细节}// 3. 注册到 StateBackend如何扩展新的函数类型?
// 继承 Function 接口@FunctionalInterfacepublic interface MyFunction<T, R> extends Function { R apply(T input);}8.3 版本演进策略
flink-core-api 使用 @PublicEvolving 注解标记演进中的接口:
@PublicEvolvingpublic interface State { void clear();}含义:
-
• 接口仍在演进,可能添加新方法 -
• 实现类需要跟随更新 -
• 用户代码需要关注版本兼容性
九、总结与启示
9.1 flink-core-api 的核心价值
flink-core-api 虽然不包含任何实现代码,但它是 Flink 架构的基石:
-
1. 契约定义:定义了整个框架的行为契约 -
2. 类型安全:通过泛型确保类型安全 -
3. 扩展点:为用户提供明确的扩展接口 -
4. 向后兼容:精心设计支持版本演进
9.2 最佳实践
-
1. 面向接口编程:依赖 State 而非具体实现 -
2. 使用标记接口:配合 Lambda 表达式 -
3. 善用状态类型:选择合适的状态接口 -
4. 关注注解: @Public、@PublicEvolving、@Experimental有不同含义
9.3 架构师启示
从 flink-core-api 的设计中学到:
-
1. 接口即法律:接口定义要谨慎,一旦发布就要维护 -
2. 渐进式抽象:从简单到复杂,给用户选择空间 -
3. v2 包模式:支持 API 演进,保持向后兼容 -
4. 功能式接口:拥抱函数式编程,提升开发体验
附录
A. 核心接口清单
表 A-1:flink-core-api 核心接口清单
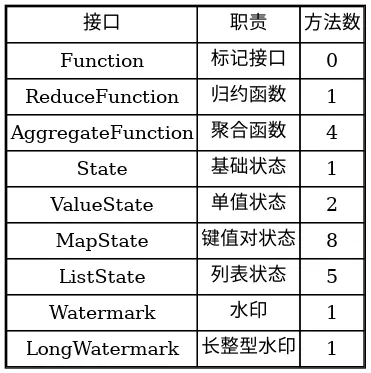
B. 包结构说明
图 B-1:flink-core-api 包结构图
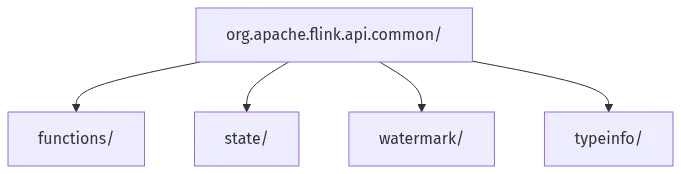
C. 参考资料
-
• Flink 官方文档: https://nightlies.apache.org/flink/flink-docs-release-2.2/ -
• State Backend 文档: https://nightlies.apache.org/flink/flink-docs-release-2.2/docs/deployment/advanced/state_backends/ -
• Functions 文档: https://nightlies.apache.org/flink/flink-docs-release-2.2/docs/dev/datastream/operators/udfs/
下一篇: 分析 flink-streaming-java 模块