 夜雨聆风
夜雨聆风





YOLO26原创源码优化:SPPF优化 | 新一代高效可形变卷积DCNv4如何做二次创新?高效结合SPPF
点击上方蓝字关注我们
微信号:AI_CV_0624
加关注

💡💡💡本文独家改进:DCNv4更快收敛、更高速度、更高性能,完美和YOLO11结合,助力涨点
DCNv4优势:(1) 去除空间聚合中的softmax归一化,以增强其动态性和表达能力;(2) 优化存储器访问以最小化冗余操作以加速。这些改进显著加快了收敛速度,并大幅提高了处理速度,DCNv 4实现了三倍以上的前向速度。

💡💡💡如何跟YOLO26结合:1) SPPF高效结合
《YOLO26魔术师专栏》将从以下各个方向进行创新:
链接:
https://blog.csdn.net/m0_63774211/category_13118090.html?spm=1001.2014.3001.5482【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【小目标性能提升】【前沿论文分享】【训练实战篇】
订阅者通过添加WX: AI_CV_0624,入群沟通,提供改进结构图等一系列定制化服务。
订阅者中稿消息:ICASSP2026、SCI二、三区为主;
定期向订阅者提供源码工程,配合博客使用。
订阅者可以申请发票,便于报销
💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、26年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥100+ ,冲刺200+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏涨价趋势199->259->299,越早订阅越划算⭐⭐⭐
💡💡💡 2026年计算机视觉顶会创新点适用于YOLO26、YOLOv13、YOLOv12、YOLO11、YOLOv8等各个YOLO系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️

论文:https://arxiv.org/pdf/2509.25164
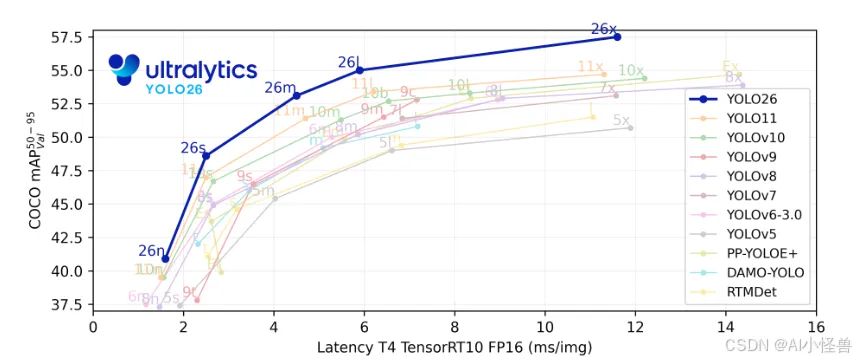
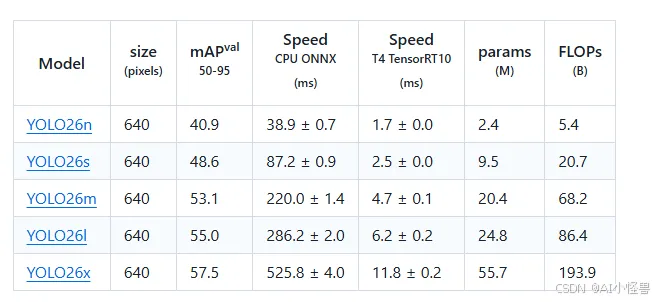
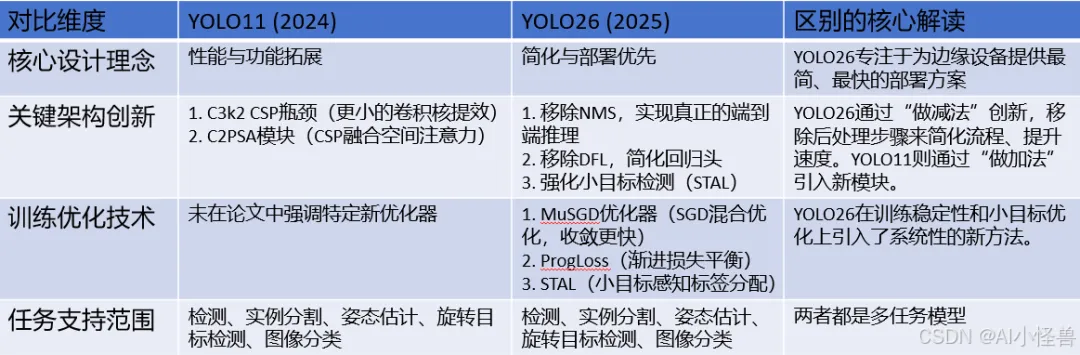
摘要:本研究对Ultralytics YOLO26进行了全面分析,重点阐述了其关键架构改进及其在实时边缘目标检测中的性能基准测试。YOLO26于2025年9月发布,是YOLO系列最新、最先进的成员,专为在边缘及低功耗设备上实现高效、精确且易于部署的目标而构建。本文依次详述了YOLO26的架构创新,包括:移除了分布焦点损失(DFL);采用端到端的无NMS推理;集成了渐进损失(ProgLoss)与小目标感知标签分配(STAL);以及引入了用于稳定收敛的MuSGD优化器。除架构外,本研究将YOLO26定位为多任务框架,支持目标检测、实例分割、姿态/关键点估计、定向检测及分类。我们在NVIDIA Jetson Nano与Orin等边缘设备上呈现了YOLO26的性能基准测试,并将其结果与YOLOv8、YOLOv11、YOLOv12、YOLOv13及基于Transformer的检测器进行比较。本文进一步探讨了其实时部署路径、灵活的导出选项(ONNX、TensorRT、CoreML、TFLite)以及INT8/FP16量化技术。文章重点展示了YOLO26在机器人、制造业及物联网等领域的实际应用案例,以证明其跨行业适应性。最后,讨论了关于部署效率及更广泛影响的见解,并展望了YOLO26及YOLO系列的未来发展方向。
关键词:YOLO26;边缘人工智能;多任务目标检测;无NMS推理;小目标识别;YOLO(You Only Look Once);目标检测;MuSGD优化器
Detection (COCO)
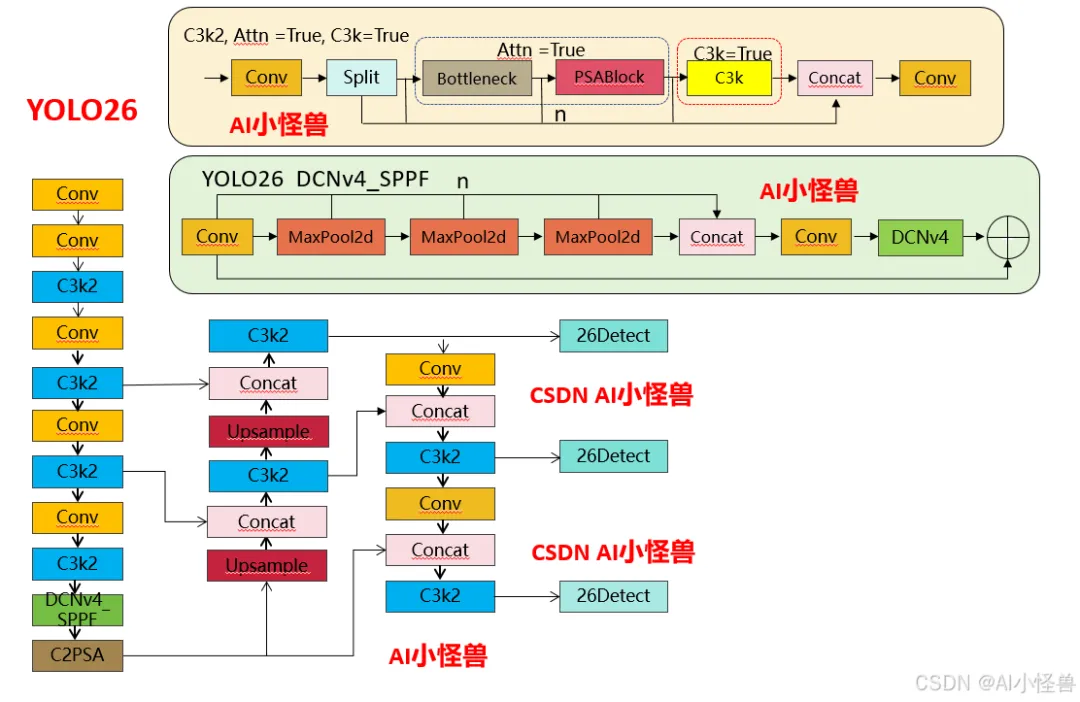
结构框图如下:
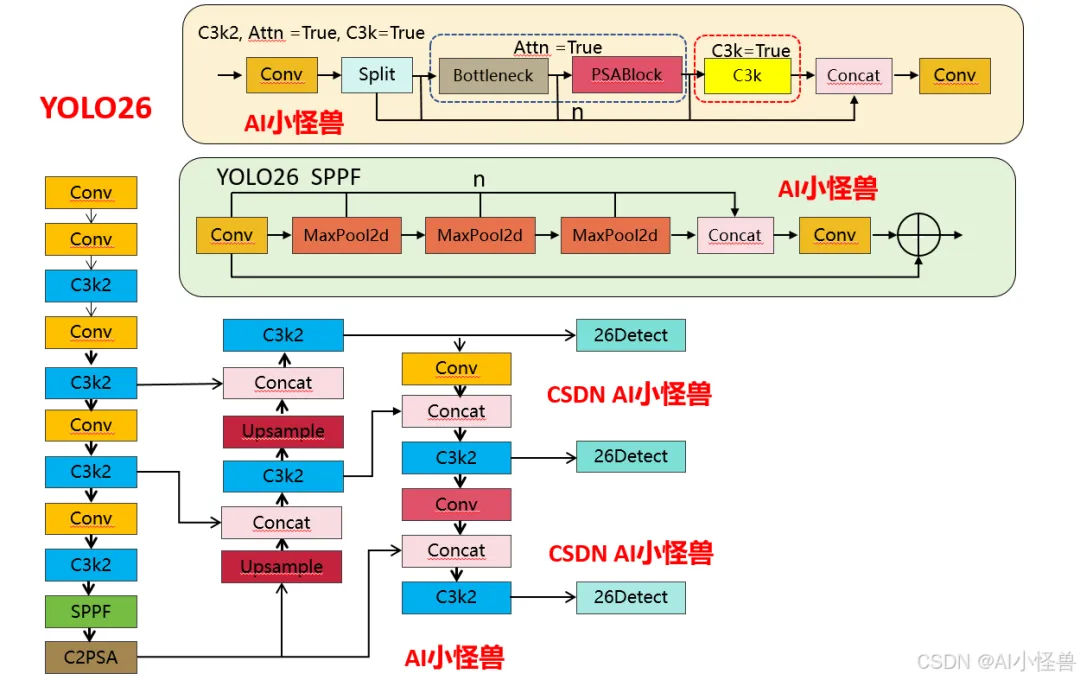
1.1 YOLO11 vs YOLO26结构差异性
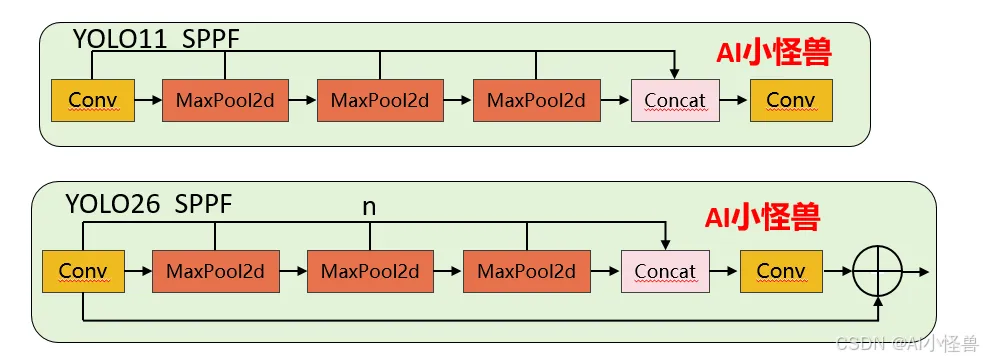
1.1.1 SPPF 核心差异对比
1)池化次数灵活性:YOLO11 的 3 次池化是硬编码的,要修改必须改源码;YOLO26 通过n参数可灵活调整(比如设为 2 次或 4 次),无需改核心逻辑。
2)Shortcut 设计:YOLO26 新增的残差连接能缓解深层网络的梯度消失问题,提升特征复用能力,而 YOLO11 无此设计。
3)激活函数控制:YOLO26 禁用 Conv1 的激活函数,让特征在池化前保持更 “原始” 的状态,是工程上对特征提取的优化。
源码位置:ultralytics/nn/modules/block.py
1.1.2 C3k2 核心差异对比
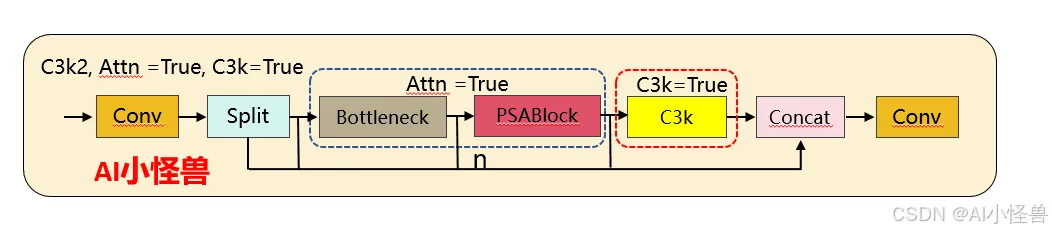
1)注意力机制的新增:YOLO26 的 C3k2 首次引入PSABlock(金字塔注意力模块),通过attn参数控制是否启用,这是两者最核心的功能差异 —— 启用后模块会先通过 Bottleneck 提取基础特征,再通过 PSABlock 增强关键区域的特征权重,提升小目标 / 复杂场景的检测效果。
2)分支逻辑的扩展:YOLO11 的分支仅受c3k控制,而 YOLO26 的分支逻辑优先级为attn > c3k,即只要attn=True,会优先启用注意力模块,忽略c3k的配置。
YOLO26 C3k2代码:
源码位置:ultralytics/nn/modules/block.py
1.2 YOLO26核心创新点
YOLO26引入了多项关键架构创新,使其区别于前几代YOLO模型。这些增强不仅提高了训练稳定性和推理效率,还从根本上重塑了实时边缘设备的部署流程。本节将详细描述YOLO26的四项主要贡献:(i)移除分布焦点损失(DFL),(ii)引入端到端无NMS推理,(iii)新颖的损失函数策略,包括渐进损失平衡(ProgLoss)和小目标感知标签分配(STAL),以及(iv)开发用于稳定高效收敛的MuSGD优化器。我们将详细讨论每一项架构增强,并通过对比分析突显其相对于YOLOv8、YOLOv11、YOLOv12和YOLOv13等早期YOLO版本的优势。
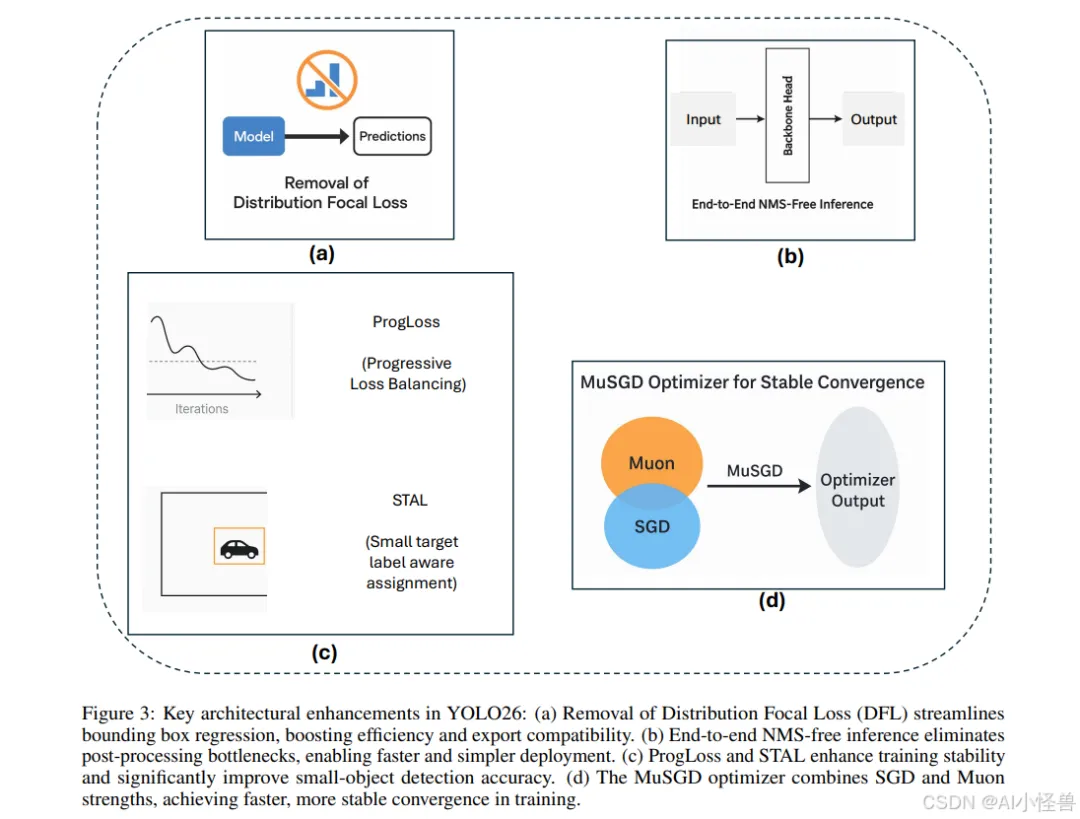
1.2.1 创新点1:移除分布焦点损失(DFL)
YOLO26最重要的架构简化之一是移除了分布焦点损失(DFL)模块(图3a),该模块曾存在于YOLOv8和YOLOv11等早期YOLO版本中。DFL最初旨在通过预测边界框坐标的概率分布来改进边界框回归,从而实现更精确的目标定位。虽然该策略在早期模型中展示了精度提升,但也带来了不小的计算开销和导出困难。在实践中,DFL在推理和模型导出期间需要专门处理,这使针对ONNX、CoreML、TensorRT或TFLite等硬件加速器的部署流程变得复杂。
源码位置:ultralytics/utils/loss.py
通过reg_max 设置为1,移除了分布焦点损失(DFL)
1.2.2 创新点2:端到端无NMS推理
YOLO26从根本上重新设计了预测头,以直接产生非冗余的边界框预测,无需NMS。这种端到端设计不仅降低了推理复杂度,还消除了对手动调优阈值的依赖,从而简化了集成到生产系统的过程。对比基准测试表明,YOLO26实现了比YOLOv11和YOLOv12更快的推理速度,其中nano模型在CPU上的推理时间减少了高达43%。这使得YOLO26对于移动设备、无人机和嵌入式机器人平台特别有利,在这些平台上,毫秒级的延迟可能产生重大的操作影响。
源码位置:ultralytics/utils/nms.py
1.2.3 创新点3:ProgLoss和STAL:增强训练稳定性和小目标检测
训练稳定性和小目标识别仍然是目标检测中持续存在的挑战。YOLO26通过整合两种新颖策略来解决这些问题:渐进损失平衡(ProgLoss)和小目标感知标签分配(STAL),如图(图3c)所示。
ProgLoss在训练期间动态调整不同损失分量的权重,确保模型不会过拟合于主导物体类别,同时防止在稀有或小类别上表现不佳。这种渐进式再平衡改善了泛化能力,并防止了训练后期的不稳定。另一方面,STAL明确优先为小目标分配标签,由于像素表示有限且易被遮挡,小目标尤其难以检测。ProgLoss和STAL共同为YOLO26在包含小目标或被遮挡目标的数据集(如COCO和无人机图像基准)上带来了显著的精度提升。
1.2.4 创新点4:用于稳定收敛的MuSGD优化器
YOLO26的最后一项创新是引入了MuSGD优化器(图3d),它结合了随机梯度下降(SGD)的优势与最近提出的Muon优化器(一种受大型语言模型训练中使用的优化策略启发而发展的技术)。MuSGD利用SGD的鲁棒性和泛化能力,同时融入了来自Muon的自适应特性,能够在不同数据集上实现更快的收敛和更稳定的优化。
源码位置:ultralytics/optim/muon.py

论文: https://arxiv.org/pdf/2401.06197.pdf
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
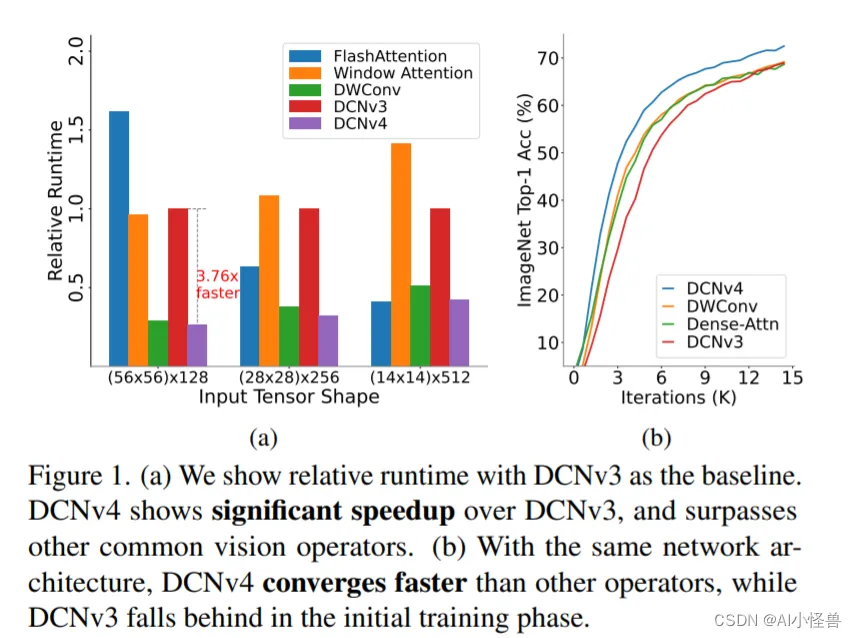
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。
为了克服这些挑战,我们提出了可变形卷积v4 (DCNv4),这是一种创新的进步,用于优化稀疏DCN算子的实际效率。DCNv4具有更快的实现速度和改进的操作符设计,以增强其性能,我们将详细说明如下: 首先,我们对现有实现进行指令级内核分析,发现DCNv3已经是轻量级的。计算成本不到1%,而内存访问成本为99%。这促使我们重新审视运算符实现,并发现DCN转发过程中的许多内存访问是冗余的,因此可以进行优化,从而实现更快的DCNv4实现。 其次,从卷积的无界权值范围中得到启发,我们发现在DCNv3中,密集关注下的标准操作——空间聚合中的softmax归一化是不必要的,因为它不要求算子对每个位置都有专用的聚合窗口。直观地说,softmax将有界的0 ~ 1值范围放在权重上,并将限制聚合权重的表达能力。这一见解使我们消除了DCNv4中的softmax,增强了其动态特性并提高了其性能。因此,DCNv4不仅收敛速度明显快于DCNv3,而且正向速度提高了3倍以上。这一改进使DCNv4能够充分利用其稀疏特性,成为最快的通用核心视觉算子之一。
我们进一步将InternImage中的DCNv3替换为DCNv4,创建FlashInternImage。值得注意的是,与InternImage相比,FlashInternImage在没有任何额外修改的情况下实现了50 ~ 80%的速度提升。这一增强定位FlashInternImage作为最快的现代视觉骨干网络之一,同时保持卓越的性能。在DCNv4的帮助下,FlashInternImage显著提高了ImageNet分类[10]和迁移学习设置的收敛速度,并进一步提高了下游任务的性能。
图2。(a)注意力(Attention)和(b) DCNv3使用有限的(范围从0 ~ 1)动态权值来聚合空间特征,而注意力的窗口(采样点集)是相同的,DCNv3为每个位置使用专用的窗口。(c)卷积对于聚合权值具有更灵活的无界值范围,并为每个位置使用专用滑动窗口,但窗口形状和聚合权值是与输入无关的。(d) DCNv4结合两者的优点,采用自适应聚合窗口和无界值范围的动态聚合权值。
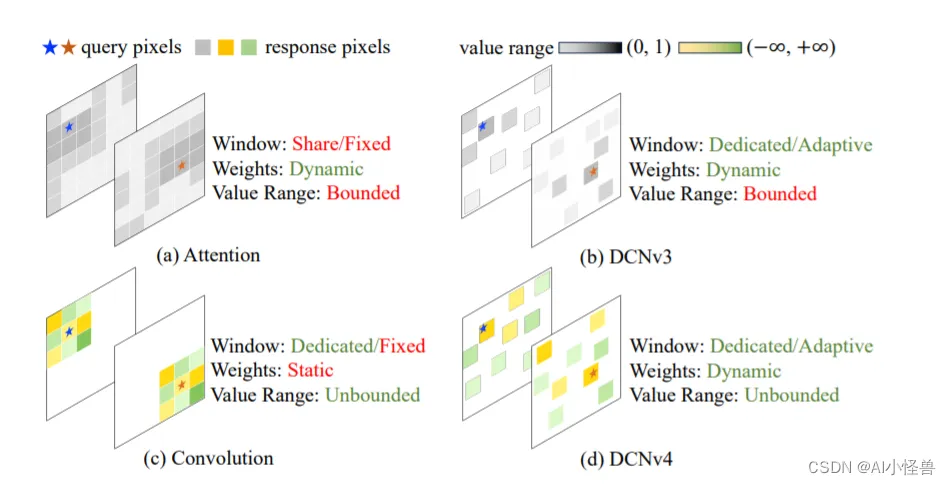
图3。说明我们的优化。在DCNv4中,我们使用一个线程来处理同一组中的多个通道,这些通道共享采样偏移量和聚合权重。可以减少内存读取和双线性插值系数计算等工作负载,并且可以合并多个内存访问指令。
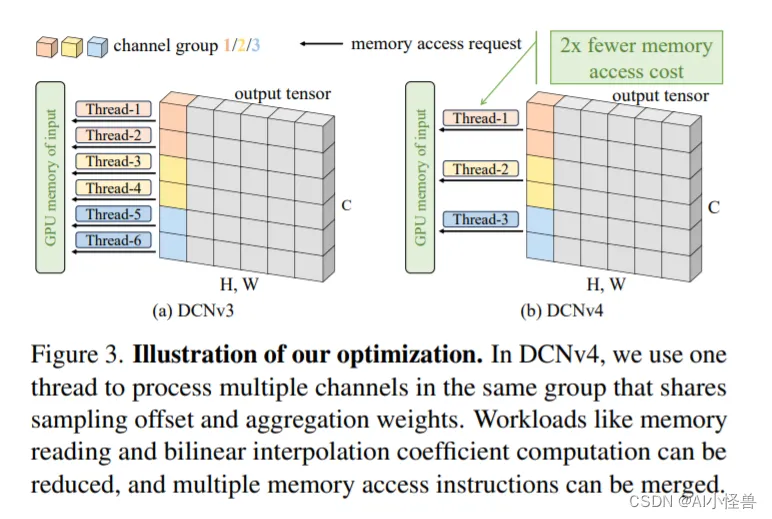 表2。具有各种下采样率的标准输入形状的运算级基准。当实现可用时报告FP32/FP16结果。在不同的输入分辨率下,我们的DCNv4可以超越所有其他常用运算符。
表2。具有各种下采样率的标准输入形状的运算级基准。当实现可用时报告FP32/FP16结果。在不同的输入分辨率下,我们的DCNv4可以超越所有其他常用运算符。
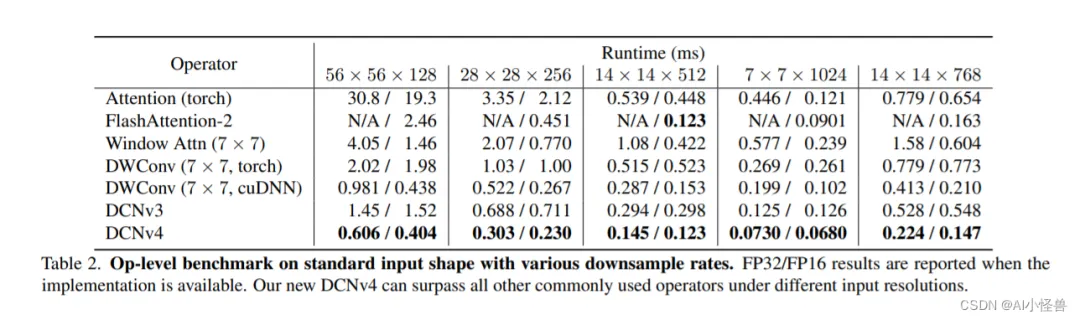 表3。具有各种下采样率的高分辨率输入形状的运算级基准。DCNv4作为稀疏算子表现良好,优于所有其他基线,而密集的全局关注在这种情况下速度较慢。
表3。具有各种下采样率的高分辨率输入形状的运算级基准。DCNv4作为稀疏算子表现良好,优于所有其他基线,而密集的全局关注在这种情况下速度较慢。
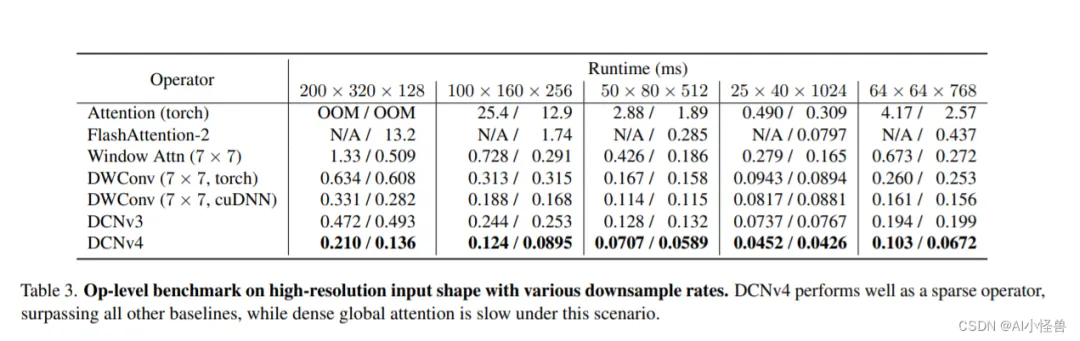
表4。ImageNet-1K上的图像分类性能。我们展示了FlashInternImage w/ DCNv4和它的InternImage对应版本之间的相对加速。DCNv4显着提高了速度,同时显示了最先进的性能。
3.1 源码下载
下载链接:GitHub – OpenGVLab/DCNv4: [CVPR 2024] Deformable Convolution v4
将 DCNv4_op文件夹放入ultralytics\nn目录下
3.2 编译DCNv4
在DCNv4_op文件夹下执行以下命令:
python setup.py build install编译通过

3.3 DCNv4结合SPPF
3.4 新建ultralytics/nn/sppf/DCNv4_SPPF.py
核心源码:
https://blog.csdn.net/m0_63774211/article/details/157433666?spm=1001.2014.3001.5501import torchimport torch.nn as nnimport torch.nn.functional as Ffrom ultralytics.nn.modules import (Conv, C3, Bottleneck, C2f)try:from DCNv4.modules.dcnv4 import DCNv4except ImportError as e:passdef autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass DCNV4_YOLO(nn.Module):def __init__(self, inc, ouc, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()if inc != ouc:self.stem_conv = Conv(inc, ouc, k=1)self.dcnv4 = DCNv4(ouc, kernel_size=k, stride=s, pad=autopad(k, p, d), group=g, dilation=d)self.bn = nn.BatchNorm2d(ouc)self.act = Conv.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):if hasattr(self, 'stem_conv'):x = self.stem_conv(x)x = self.dcnv4(x, (x.size(2), x.size(3)))x = self.act(self.bn(x))return x
3.5 yolo26-DCNv4_SPPF.yaml
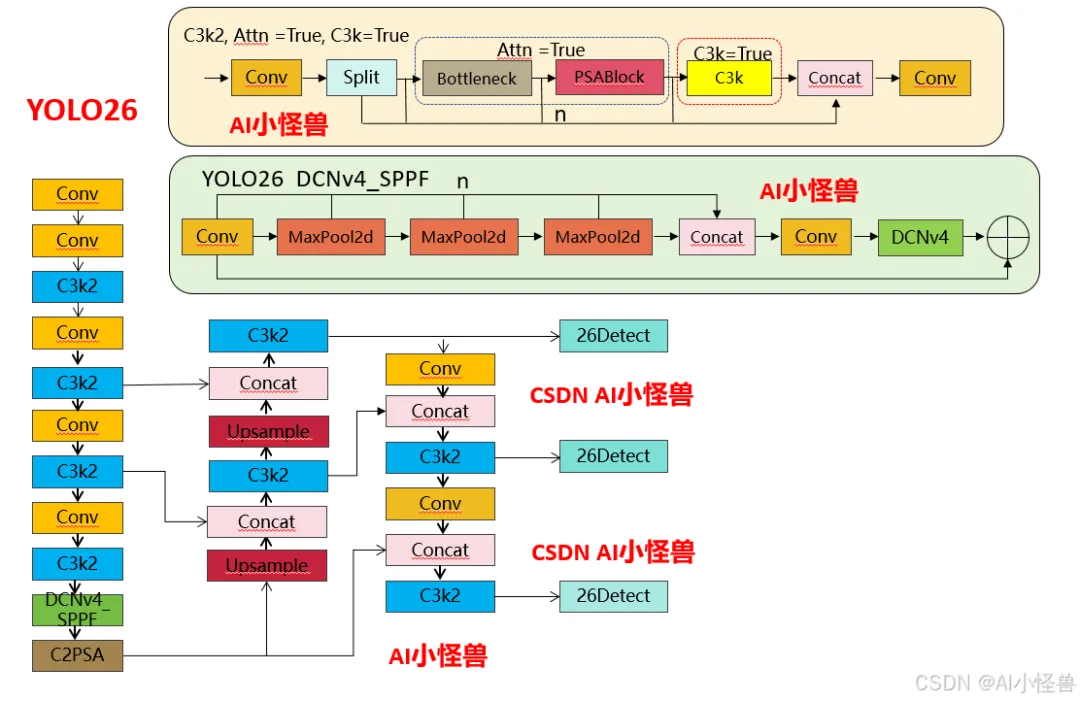
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs# Model docs: https://docs.ultralytics.com/models/yolo26# Task docs: https://docs.ultralytics.com/tasks/detect# Parametersnc: 80 # number of classesend2end: True # whether to use end-to-end modereg_max: 1 # DFL binsscales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPss: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPsm: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPsl: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPsx: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs# YOLO26n backbonebackbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, DCNv4_SPPF, [1024, 5, 3, True]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO26n headhead:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, True]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, True]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, True]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 1, C3k2, [1024, True, 0.5, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
可以添加我的微信进群
微信号:AI_CV_0624
加关注
