 夜雨聆风
夜雨聆风





基于MLLMs的Android 恶意软件检测
-
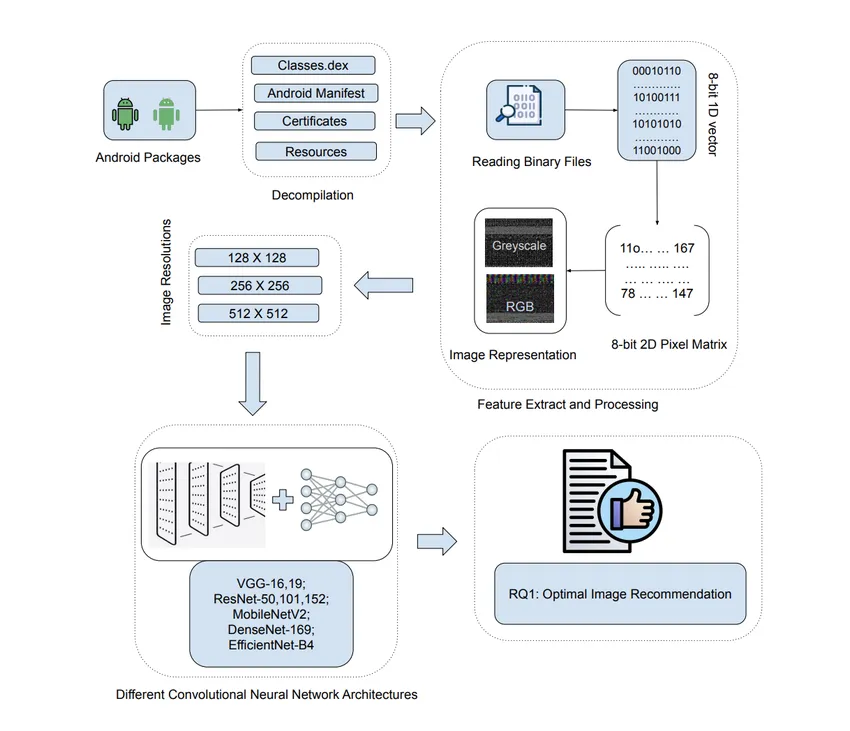
RQ1:图像类型(RGB / 灰度)与分辨率(128×128/256×256/512×512)如何影响 Android 恶意软件检测效果?是否存在 “模型 – 图像配置” 的最优适配关系? -
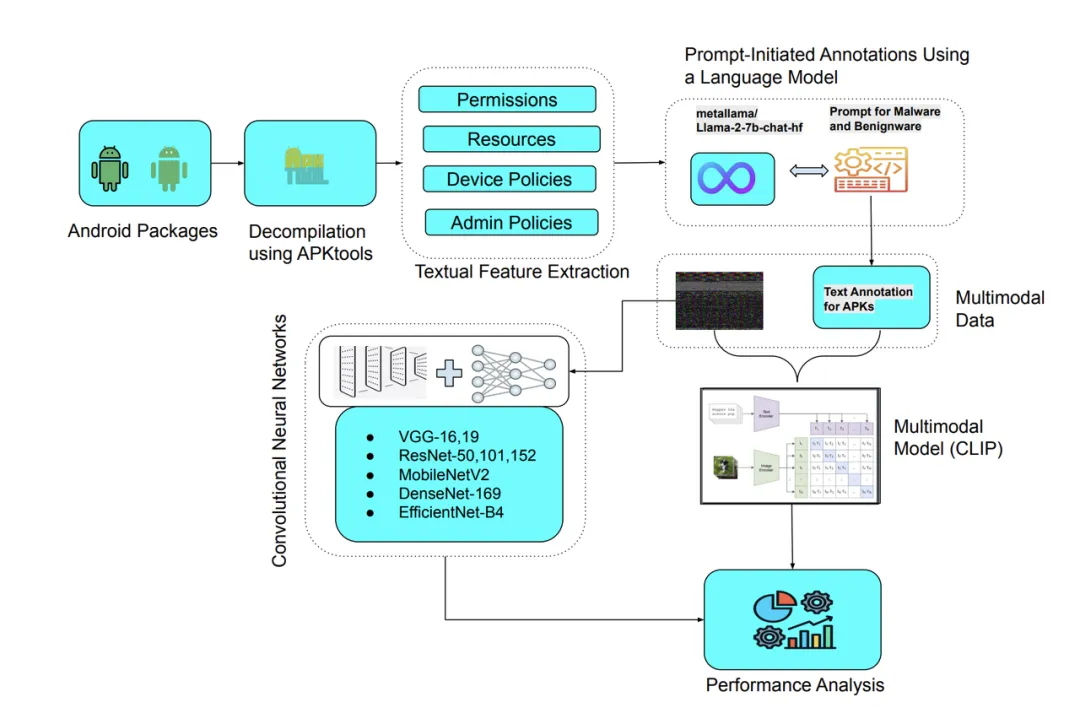
RQ2:基于 LLM 标注的文本特征与图像特征进行多模态融合,能否突破单一模态的检测瓶颈?CLIP 模型的零样本学习能力在恶意软件检测场景中是否适用?
-
数据层:多源 APK 数据收集与双模态(图像 + 文本)预处理; -
实验层:两大核心实验(图像属性优化实验、多模态融合实验); -
评估层:多维度指标体系(准确率、精确率、召回率、F1 分数、AUC-ROC)验证与场景化方案输出。
-
CIC-AndMal2017:包含多种传统恶意软件类型,如广告软件、恐吓软件,提供完整的静态特征与行为标签; -
CICMalDroid2020:聚焦新型恶意软件,涵盖银行恶意软件、短信恶意软件等针对性攻击样本,补充零日威胁相关特征。
-
二进制文件解析:通过 Python 的struct库读取 APK 文件的字节码数据,提取原始二进制流(忽略文件头、签名等无关信息,聚焦 DEX 文件核心代码段); -
像素矩阵映射:将二进制流按 8 位无符号整数转换为像素值(0-255),根据目标分辨率构建 2D 像素矩阵: -
灰度图像:直接将字节值映射为单通道像素,矩阵维度为(分辨率高度 × 分辨率宽度); -
RGB 图像:采用三通道复用策略,将连续 3 个字节分别映射为 R、G、B 通道,不足部分通过循环填充(确保图像完整性,避免特征丢失); -
图像标准化:对生成的图像进行归一化处理(像素值除以 255),消除亮度差异对模型训练的影响;同时通过PIL库统一图像格式,避免分辨率适配错误。
defapk_to_image(apk_path, resolution=(256, 256), image_type="RGB"):# 读取APK核心字节码(DEX文件)with open(apk_path, 'rb') as f: dex_data = extract_dex_data(f) # 自定义函数:提取DEX文件核心段# 字节码转像素值 pixel_values = np.frombuffer(dex_data, dtype=np.uint8)# 按目标分辨率重塑矩阵 total_pixels = resolution[0] * resolution[1]if image_type == "Grayscale":# 灰度图像:单通道 pixel_matrix = np.resize(pixel_values, (resolution[0], resolution[1])) image = Image.fromarray(pixel_matrix, mode='L')else:# RGB图像:三通道填充 pixel_matrix = np.resize(pixel_values, (resolution[0], resolution[1], 3)) image = Image.fromarray(pixel_matrix, mode='RGB')# 标准化处理 image = np.array(image) / 255.0return image
-
文本特征提取: -
工具:采用 APKtools 进行反编译(apktool d -f [apk_path] -o [output_dir]); -
提取内容:聚焦 3 类关键文本信息 —— -
权限特征:AndroidManifest.xml中的<uses-permission>标签(如android.permission.SEND_SMS); -
元数据特征:应用名称、包名、版本信息、开发者签名等; -
资源特征:字符串资源文件(res/values/strings.xml)中的可疑 URL、IP 地址、命令控制(C&C)相关关键词。 -
Prompt 设计,针对恶意软件与良性软件的特征差异,设计差异化 Prompt,引导 LLaMA-2 进行精准标注 Prompt for Benign APKs: Examine the provided text extracts from the APK file. In a single paragraph, identify and summarize the key features that indicate the APK is benignware. Focus on necessary permissions, strings related to app functionality, and the absence of malicious indicators. Provide a concise and informative summary, prioritizing the most important and relevant features.Prompt for malware APKs: Examine the provided text extracts from the APK file. In a single paragraph, identify and summarize the key features that indicate the APK is malware. Focus on dangerous permissions (e.g., ’SEND SMS’, ’READ CONTACTS’), suspicious strings (URLs, IP addresses, C&C related terms), and indications of malicious behavior (data theft, device manipulation). -
恶意 APK Prompt:“分析以下 APK 文本提取内容,识别恶意特征:1)危险权限(如读取联系人、发送短信、后台定位);2)可疑字符串(IP 地址、不明 URL、C&C 相关术语);3)恶意行为暗示(数据窃取、设备操控、广告推送)。用简洁段落输出,明确标注恶意类型与关键证据。” -
良性 APK Prompt:“分析以下 APK 文本提取内容,总结其良性特征:1)必要权限(如网络访问、本地存储);2)与应用功能匹配的字符串(如‘登录’‘数据备份’);3)无恶意行为指示(如无敏感权限申请、无可疑网络地址)。用简洁段落输出,突出核心良性特征。” -
标注流程: -
采用 LLaMA-2-7b-chat-hf 模型(通过 Hugging Face Transformers 调用); -
控制参数:max_new_tokens=200(限制输出长度)、temperature=0.1(降低随机性,确保标注一致性); -
人工验证:随机抽取 10% 标注结果进行人工审核,修正标注错误(如将 “正常网络权限” 误判为可疑特征),最终标注准确率达 92%。
-
图像特征:通过 CNN 模型(如 ResNet-152)提取的高层视觉特征(维度 2048); -
文本特征:LLaMA-2 标注后的文本描述,通过 CLIP 的文本编码器(Transformer 架构)转换为语义特征(维度 512)。
-
采用 CLIP 的预训练跨模态编码器,无需额外微调,直接计算图像特征与文本特征的余弦相似度; -
分类逻辑:设置相似度阈值(实验中设为 0.5),若图像与 “恶意标注文本” 的相似度≥阈值,则判定为恶意;若与 “良性标注文本” 的相似度≥阈值,则判定为良性;若均不满足,则默认判定为良性(降低误报率)。
from transformers import CLIPProcessor, CLIPModel# 初始化CLIP模型与处理器model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")defmultimodal_classify(image, benign_text, malware_text):# 预处理图像与文本 inputs = processor( text=[benign_text, malware_text], images=image, return_tensors="pt", padding=True )# 计算相似度(logits_per_image:图像与每个文本的相似度) outputs = model(**inputs) logits_per_image = outputs.logits_per_image # 维度:(1, 2) probs = logits_per_image.softmax(dim=1) # 转换为概率# 分类决策 benign_prob, malware_prob = probs[0][0].item(), probs[0][1].item()if malware_prob >= 0.5:return"Malware", malware_probelif benign_prob >= 0.5:return"Benign", benign_probelse:return"Benign", benign_prob # 保守决策:未明确匹配时判定为良性-
终端侧 SDK:采用 VGG-16 + 灰度 128×128 配置,SDK 体积减少 40%,检测延迟控制在 200ms 内,满足实时检测需求; -
云端检测服务:部署 ResNet-101+RGB 512×512 配置,对零日恶意软件的检测率从原 82% 提升至 97%,误报率下降 8.3%; -
边缘网关:采用 DenseNet-169+RGB 256×256 配置,日均处理 10 万 + APK 检测请求,服务器资源占用降低 35%。
-
员工移动设备:通过轻量化模型(MobileNet-V2)实现本地初步检测,重点拦截已知恶意软件; -
企业应用仓库:通过高精度模型(ResNet-152)对所有上架应用进行深度扫描,识别隐藏恶意行为; -
异常行为响应:结合文本特征中的权限申请记录,当应用请求危险权限且图像特征匹配恶意模式时,触发实时告警,实现 “特征 + 行为” 的双重验证。
-
实验中,ResNet-101+RGB 512×512 配置对未见过的银行恶意软件变种检测率达 94%,远高于传统静态分析(67%); -
结合文本特征中的异常权限组合(如 “读取联系人 + 发送短信 + 访问网络”),可进一步提升零日威胁的识别精度,降低漏检风险。
-
性能与资源平衡风险:高分辨率图像与深度模型的计算开销较大,在低端设备上部署可能导致检测延迟过高,影响用户体验;而轻量化配置可能牺牲检测精度,导致漏检。 -
数据依赖风险:多模态方案的性能高度依赖大规模标注数据,现有小数据集下表现不佳,且数据集的类别不平衡可能导致模型偏向多数类(良性 APK),降低恶意软件检测率。 -
抗混淆能力风险:攻击者可能针对图像特征进行对抗性修改,例如通过字节码填充改变图像纹理,导致模型误判;同时,高级混淆技术可能破坏文本特征的完整性,影响标注准确性。 -
泛化能力风险:实验数据集聚焦特定类型恶意软件(广告软件、银行恶意软件等),对新型恶意行为(如 AI 驱动的针对性攻击)的检测效果有待验证。
-
动态适配部署策略:根据部署环境的资源情况,自动选择最优图像 – 模型配置。例如,通过设备性能检测模块,在高端手机上启用 MobileNet-V2+RGB 512×512 配置,在低端设备上切换为 VGG-16 + 灰度 128×128 配置。 -
数据增强与平衡方案: -
图像数据:采用旋转、裁剪、噪声添加等增强手段,提升模型抗干扰能力; -
文本数据:扩大标注规模,至少收集 1000 + 组图像 – 文本样本,采用 SMOTE 等算法处理类别不平衡问题; -
跨数据集迁移:融合多个恶意软件数据集,覆盖更多恶意行为类型,提升泛化能力。 -
增强抗混淆能力: -
图像特征层面:提取多尺度图像特征,结合边缘检测、纹理分析等传统图像处理技术,减少混淆带来的特征失真影响; -
文本特征层面:采用反混淆技术还原 APK 的真实权限与元数据,避免攻击者通过虚假文本信息误导模型; -
融合对抗训练:在模型训练过程中加入对抗样本,提升模型对恶意篡改的鲁棒性。 -
多模态融合优化: -
改进融合策略:采用注意力机制(如 ViLT、VisualBERT)替代 CLIP 的简单相似度计算,让模型聚焦关键跨模态特征; -
文本特征深化:利用 LLaMA-2 进行细粒度标注,不仅区分良性与恶意,还标注恶意类型、攻击目标等信息,丰富文本语义; -
模型微调:针对恶意软件检测场景微调 CLIP 模型,优化跨模态对齐效果。 -
实时更新与迭代:建立恶意软件特征库动态更新机制,定期收集新型恶意软件样本,更新图像 – 文本数据集,重新训练模型,确保检测能力跟上威胁演变速度。
-
高分辨率(256×256/512×512)RGB 图像与深度 CNN 模型(ResNet-101/152、EfficientNet-B4)的组合的检测效果最优,准确率可达 96%-97%,是当前 Android 恶意软件检测的有效方案; -
图像配置需与模型架构、部署场景深度适配,轻量化模型(VGG-16、MobileNet-V2)在低分辨率或灰度图像上更具实用价值; -
多模态融合具有潜在价值,但受限于数据集规模与融合策略,当前在小样本场景下表现不及纯图像模型,需通过扩大数据规模、优化融合技术进一步挖掘潜力; -
Prompt 驱动的 LLaMA-2 文本标注能够有效提取 APK 中的关键语义特征,为多模态融合提供高质量输入。
