 夜雨聆风
夜雨聆风





(文档)PG第117讲:融合计算插件–duckdb_fdw使用技巧


Objectives
• duckdb_fdw概述
• duckdb_fdw安装
• 本地表与duckdb表性能对比
• duckdb_fdw应用场景
关系型数据库的痛点
• 性能瓶颈:行存储读取需加载整行数据,而OLAP查询(如sum、group by)通常仅需部分列,导致IO冗余严重,海量数据场景下查询耗时呈指数级增长;
• 生态割裂:无法直接对接数据湖中的列存储文件,需通过ETL工具批量加载,存在显著数据延迟,无法支撑实时分析决策需求;
• 资源浪费:若将列存储数据全量导入PostgreSQL行存表,会导致存储成本翻倍,同时占用数据库计算资源,影响核心OLTP业务稳定性。
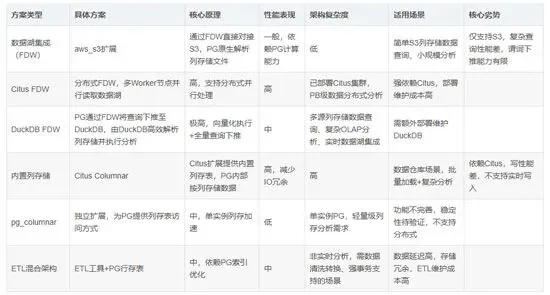
列存储数据处理主流方案对比
DuckDB FDW方案在性能、灵活性与复杂度之间实现了最优平衡:既具备接近分布式方案的分析性能,又无需依赖复杂的Citus集群;既支持多源列存储数据对接,又能通过全量查询下推大幅减轻PostgreSQL负担,是大多数企业实现“PostgreSQL+OLAP+列存储”一体化架构的首选方案。
Duckdb_fdw概述
duckdb是一款性能非常好的in-process OLAP数据库, 同时支持数据湖架构, 支持访问s3/oss/http等远端数据, 支持列存储/parquet等常见的存储结构。通过duckdb_fdw让postgresql也可以具备以上能力。
DuckDB FDW作为PostgreSQL与DuckDB的桥梁,核心实现“查询下推+结果回传”的轻量化协作流程:
1、用户在PG中通过DuckDB FDW创建外部表,关联DuckDB中的列存储数据(本地或S3/GCS);
2、用户执行SQL查询时,PG将查询解析后通过FDW下推至DuckDB;
3、DuckDB利用自身OLAP优势,高效解析列存储文件、执行过滤/聚合等计算,仅将最终结果集回传至PG;
4、用户在PG中直接获取查询结果,无需感知DuckDB的存在。
该方案的核心优势在于“计算下沉”:将耗时的列存储解析、过滤、聚合等OLAP计算任务交由专业的DuckDB执行,PostgreSQL仅负责接收最终结果并支撑事务处理,实现“各司其职、性能最大化”的架构目标。
DuckDB_fdw技术特点
DuckDB_fdw有如下几个技术特点:
• 性能突破:借助DuckDB的向量化执行引擎与高效查询优化器,将PostgreSQL的OLAP分析性能提升一个量级,尤其适配海量列存储数据的复杂查询场景;
• 生态兼容:无缝支持S3/GCS/本地文件等多存储源,原生适配Parquet/ORC/CSV等多种数据格式,打破PostgreSQL与数据湖的生态割裂壁垒;
• 架构轻量:无需部署复杂的分布式集群,仅需新增DuckDB组件,部署维护成本远低于Citus等分布式方案,中小企业可快速落地;
• 无缝体验:用户在PostgreSQL中可直接查询外部列存储数据,无需学习新的查询语法,原有业务代码无需改造,降低技术落地门槛。
duckdb_fdw应用场景
Duckdb_fdw应用场景选择:
• 适合场景:实时OLAP分析、数据湖列存储数据查询、跨源数据联合分析、无需强事务支持的报表统计与决策分析需求;
• 不适合场景:高并发实时写入的列存储场景(DuckDB侧重读取优化)、需要分布式存储与计算的PB级以上超大规模数据场景(可升级为Trino+FDW方案)。
Duckdb_fdw安装
1、下载
https://github.com/alitrack/duckdb_fdw
2、初始化子项目
cd duckdb_fdw
mkdir libduckdb
cd libduckdb
wget https://github.com/duckdb/duckdb/releases/download/v0.9.2/libduckdb-src.zip
unzip libduckdb-src.zip
cp -f duckdb.h ../
cp -f duckdb.hpp ../
clang++ -c -fPIC -std=c++11 -D_GLIBCXX_USE_CXX11_ABI=0 duckdb.cpp -o duckdb.o
clang++ -shared -o libduckdb.so *.o
cp -f libduckdb.so $PG_HOME/lib
cp -f libduckdb.so ../
安装时注意pg_config命令,系统有自带改命令,需要通过设置PATH变量,让系统使用pg自带的pg_config命令
3、编译与安装
USE_PGXS=1 make uninstall
USE_PGXS=1 make clean
USE_PGXS=1 make distclean
USE_PGXS=1 make
USE_PGXS=1 make install
4、安装插件
create extension duckdb_fdw;
配置远程客户端访问方式
Duckdb_cli部署
DuckDB CLI是允许用户直接从命令行与DuckDB交互的工具。想直接使用数据库—例如在创建新表、从不同数据源导入数据以及执行与数据库相关的任务时。在这种情况下,直接使用DuckDB CLI要有效得多。该命令行工具可以加载数据、清洗数据。
1、下载软件并解压
wget https://github.com/duckdb/duckdb/releases/download/v0.9.2/duckdb_cli-linux-amd64.zip
unzip duckdb_cli-linux-amd64.zip
2、生成parquet数据文件
./duckdb /home/postgres/db
3、生成数据
COPY (select generate_series as id, md5(random()::text) as info,
now()::timestamp+(generate_series||’ second’)::interval as crt_time
from generate_series(1,100)) TO ‘/home/postgres/t1.parquet’ (FORMAT ‘PARQUET’);
COPY (select generate_series as cid, md5(random()::text) as info,
now()::timestamp+(generate_series||’ second’)::interval as crt_time
from generate_series(1,100)) TO ‘/home/postgres/t2.parquet’ (FORMAT ‘PARQUET’);
COPY (select (floor(random()*100)+1)::int as gid, (floor(random()*100)+1)::int as cid,
(random()*10)::int as c1, (random()*100)::int as c2, (random()*1000)::int as c3,
(random()*10000)::int as c4, (random()*100000)::int as c5 from generate_series(1,1000000))
TO ‘/home/postgres/t3.parquet’ (FORMAT ‘PARQUET’);
一种大数据时代有名的列式存储文件格式:Parquet,被广泛用于 Spark、Hadoop 数据存储。Parquet 的中文是镶木地板,意思是结构紧凑,空间占用率高。注意,Parquet 是一种文件格式!
3、创建视图
create view t1 as select * from read_parquet(‘/home/postgres/t1.parquet’);
create view t2 as select * from read_parquet(‘/home/postgres/t2.parquet’);
create view t3 as select * from read_parquet(‘/home/postgres/t3.parquet’);
4、查看表结构、数据
describe t1 ;
select count(*) from t1;
可以在duckdb命令行执行select命令
Duckdb使用技巧
• 使用duckdb_fdw
1、 创建foreign server
CREATE SERVER DuckDB_server FOREIGN DATA WRAPPER duckdb_fdw OPTIONS
(database ‘/home/postgres/db’);
2、从外部文件导入foreign table
–一次性导入方式
IMPORT FOREIGN SCHEMA public FROM SERVER DuckDB_server INTO public;
–单表导入方式
create foreign table t1 (id int8, info text, crt_time timestamp)
server duckdb_server OPTIONS (table ‘t1’);
3、为duckdb_fdw安装parquet插件并加载数据
SELECT duckdb_execute(‘duckdb_server’, ‘install parquet’);
SELECT duckdb_execute(‘duckdb_server’, ‘load parquet’);
4、访问arquet数据
explain verbose select count(distinct gid) from t3;

性能大比拼
1、基于外部表创建本地表:
postgres=# create table lt1 as select * from t1;
postgres=# create table lt2 as select * from t2;
postgres=# create table lt3 as select * from t3;
2、打开计时器:
postgres=# \timing on
3、单张表访问速度对比
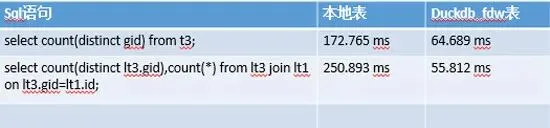
实战案例一
电商用户行为分析(S3 Parquet数据查询)
背景介绍:
某电商平台将用户行为数据(点击、下单、支付)以Parquet格式存储于S3桶(bucket:电商-data,路径:user_behavior/2025/),数据字段包括:user_id(用户ID)、action(行为类型)、action_time(行为时间)、product_id(商品ID)、amount(支付金额,仅下单/支付行为有值)。业务需求为通过PostgreSQL查询“2025年10月用户支付金额TOP10”,支撑实时运营决策(如高价值用户精准营销)。
操作步骤
1、在DuckDB中创建外部表关联S3 Parquet数据
• — 连接DuckDB(本地文件模式)
• duckdb /data/duckdb/olap_analysis.db
• — 启用S3访问扩展(DuckDB原生支持,需先安装)
• INSTALL httpfs;
• LOAD httpfs;
• — 配置S3访问凭证(优先使用IAM角色,此处展示Access Key方式,适合非AWS环境)
• SET s3_access_key_id=’你的AWS_ACCESS_KEY’;
• SET s3_secret_access_key=’你的AWS_SECRET_KEY’;
• SET s3_region=’us-east-1′;
2、创建DuckDB外部表,关联S3 Parquet数据(通配符匹配2025年全量数据)
• CREATE OR REPLACE EXTERNAL TABLE s3_user_behavior (
• user_id BIGINT, action VARCHAR, action_time TIMESTAMP,
• product_id BIGINT, amount DECIMAL(10,2)
• )
• STORED AS PARQUET LOCATION ‘s3://电商-data/user_behavior/2025/*.parquet’;
• — 验证数据可用性(查询支付行为总数,快速校验连接与数据格式)
• SELECT COUNT(*) FROM s3_user_behavior WHERE action=’pay’;
3、通过DuckDB FDW创建外部表
• — 连接PostgreSQL,创建外部表映射DuckDB中的s3_user_behavior
• CREATE FOREIGN TABLE pg_user_behavior (
• user_id BIGINT, action VARCHAR, action_time TIMESTAMP, product_id BIGINT,
• amount DECIMAL(10,2)
• )
• SERVER duckdb_server OPTIONS (table_name ‘s3_user_behavior’);
• — 与DuckDB中的表名严格一致
• — 验证映射有效性(查询前10条数据,确认字段匹配)
• SELECT * FROM pg_user_behavior LIMIT 10;
4、精准筛选2025年10月支付数据,聚合计算用户支付总额并排序
• SELECT user_id, SUM(amount) AS total_pay_amount
• FROM pg_user_behavior
• WHERE action = ‘pay’ AND action_time BETWEEN ‘2025-10-01 00:00:00’ AND ‘2025-10-31 23:59:59’ GROUP BY user_id
• ORDER BY total_pay_amount DESC
• LIMIT 10;
5、方案优势
无需将S3中的海量用户行为数据导入PostgreSQL,通过查询下推机制,DuckDB仅加载“action=pay”且“10月数据”的amount列,计算完成后仅回传10条结果集,IO与计算成本大幅降低。实测数据显示,该方案查询耗时较aws_s3扩展提升80%以上,可支撑秒级实时运营决策
实战案例二
操作步骤
1、在DuckDB中创建外部表关联S3 Parquet数据
• — 连接DuckDB,创建补贴数据外部表(复用已配置的S3凭证)
• CREATE OR REPLACE EXTERNAL TABLE s3_subsidy (
• idcard VARCHAR(18),
• subsidy_type VARCHAR,
• subsidy_amount DECIMAL(10,2),
• issue_time TIMESTAMP )
• STORED AS PARQUET LOCATION ‘s3://gov-data/subsidy/2025/*.parquet’;
• — 验证数据(按补贴类型统计数量,快速校验数据完整性)
• SELECT subsidy_type, COUNT(*) FROM s3_subsidy GROUP BY subsidy_type;
2、创建DuckDB FDW外部表(映射补贴数据)
• — 创建外部表pg_subsidy,映射DuckDB中的s3_subsidy
• CREATE FOREIGN TABLE pg_subsidy (
• idcard VARCHAR(18),
• subsidy_type VARCHAR,
• subsidy_amount DECIMAL(10,2),
• issue_time TIMESTAMP
• )
• SERVER duckdb_server OPTIONS (table_name ‘s3_subsidy’);
3、联合PostgreSQL本地表与FDW外部表执行查询
• — 关联本地人口表与FDW补贴表,精准筛选目标数据并聚合
• SELECT p.address, SUM(s.subsidy_amount) AS total_subsidy_amount
• FROM pg_population p
• JOIN pg_subsidy s ON p.idcard = s.idcard
• — 以身份证号为关联键
• WHERE p.gender = ‘女’ AND p.address LIKE ‘北京市海淀区%’
• — 精准筛选目标区域 “
• AND s.issue_time BETWEEN ‘2025-01-01’ AND ‘2025-12-31’
• — 限定2025年度
• GROUP BY p.address “ORDER BY total_subsidy_amount DESC;
4、方案优势
• 实现“本地事务数据+数据湖列存储数据”的无缝联合分析,无需通过ETL同步补贴数据至PostgreSQL,既保证数据实时性(数据湖数据变更后秒级可见),又避免存储冗余。该方案中,DuckDB负责补贴数据的高效过滤(仅筛选2025年数据),PostgreSQL负责本地人口数据的快速查询,两者协同提升分析效率,较传统ETL方案节省70%以上的架构维护成本。

PostgreSQL从入门到精通,
系列课程始于23年初,
在周六19:30与大家分享PG技术,
从基础的PG介绍与安装,
到后续的调优、流复制等企业应用,
涉及90多个知识点的介绍与演示,
截至25年8月9日,
系列课程已讲100期,
欢迎继续关注PostgreSQL技术大讲堂,
如果你也有意学习PostgreSQL,
可以联系客服,领取相关资料。

·2025年11月份工信部人才交流中心PostgreSQL能力认证证书
·工信部人才交流中心PostgreSQL能力认证证书【10月25日】
· 6月6日证书 – 工信部人才交流中心PostgreSQL中级高级认证
· 关于举办PostgreSQL数据库管理人才研修与评测班(二期)的通知
· 榜上有名!2024年工业和信息化重点领域人才能力评价支撑机构
·关于举办PostgreSQL数据库管理人才研修与评测班的通知
