 夜雨聆风
夜雨聆风





Soul APP 开源实时数字人模型,0.87秒低延时、32fps支持超长视频稳定生成
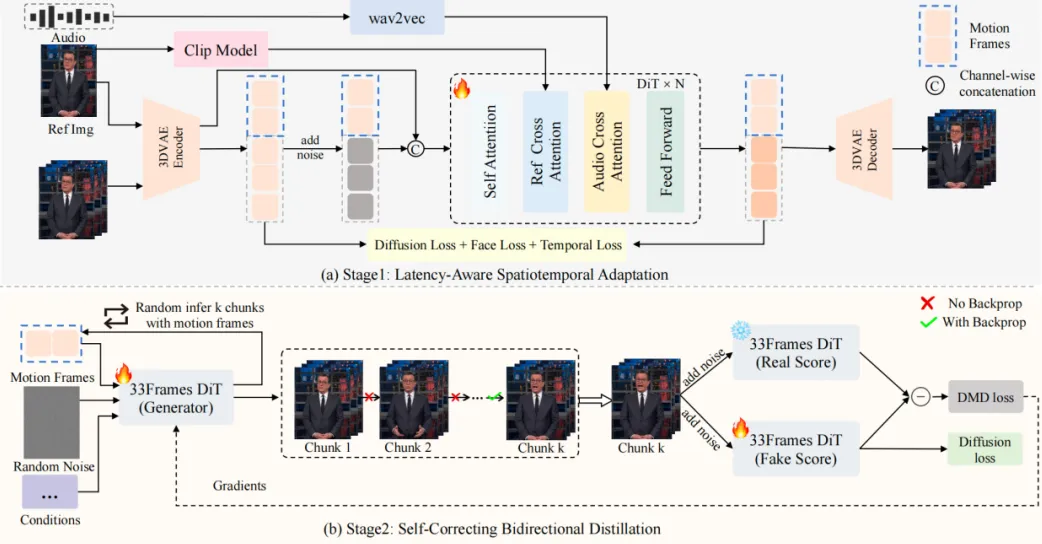
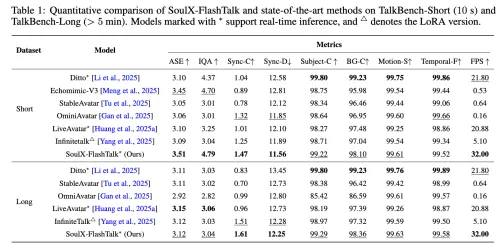
SoulX-FlashTalk 是由 SoulApp 旗下 AI 实验室(Soul-AILab)研发的全球首个实现亚秒级启动延迟的 14B 规模音频驱动数字人生成模型。该框架在 8×H800 GPU 节点上实现了 0.87 秒启动延迟 与 32 FPS 实时吞吐量 的突破性性能,同时支持无限时长的高质量视频流式生成,为实时数字人交互应用树立了新的技术标杆。
亮点
0.87秒延迟:大模型也能“秒回”
传统认知里,参数量越大,推理越慢。但 SoulX-FlashTalk 通过全栈加速(混合序列并行 + FlashAttention-3 定制 + VAE 并行解码),硬是把14B模型的端到端延迟压到亚秒级。实际体验很直观:你说完“大家好”,不到1秒,数字人已经微笑挥手回应——彻底告别“慢半拍”的尴尬,真正满足直播、视频通话等实时场景需求。
丝滑到像真人在动——32帧每秒稳稳输出
很多人以为大模型肯定很卡,但SoulX-FlashTalk偏偏反其道而行。它用140亿参数的“大块头”,却跑出了32帧每秒的流畅度——比普通直播要求的25帧还高。这意味着数字人的表情过渡、手势变化都特别自然,不会有那种一卡一卡的“PPT式”动作,看久了真的会忘记这是AI生成的。
自带“纠错能力”:播8小时也不崩
数字人最怕长时生成“翻车”:脸型漂移、嘴巴对不上、手变“面条”。SoulX-FlashTalk 的解法很巧妙——给模型装了个“自校准器”。它在推理时实时监测画面质量,一旦发现异常(比如唇形同步偏差过大),立即回溯到最近的稳定帧重新生成。这套“多步回溯自纠正机制”让模型在5分钟连续生成中保持99.22%的面部一致性,手部畸形率仅3.2%。电商直播间终于可以7×24小时无人值守,不用担心半夜画面崩坏。

应用场景
实时直播与虚拟主播
-
• 支持主播通过语音实时驱动虚拟形象 -
• 0.87 秒端到端延迟满足互动直播需求
视频播客与内容创作
-
• 输入音频脚本自动生成高质量人物视频 -
• 支持多语言语音(内置中文 wav2vec2 特征提取器) -
• 降低视频制作门槛与成本
快速上手指南
环境配置
# 创建 Conda 环境
conda create -n flashtalk python=3.10
conda activate flashtalk
# 安装 PyTorch (CUDA 12.8)
pip install torch==2.7.1 torchvision==0.22.1 --index-url https://download.pytorch.org/whl/cu128
# 安装依赖
pip install -r requirements.txt
pip install flash_attn==2.8.0.post2 --no-build-isolation
conda install -c conda-forge ffmpeg==7模型下载
# 下载主模型 (14B)
huggingface-cli download Soul-AILab/SoulX-FlashTalk-14B --local-dir ./models/SoulX-FlashTalk-14B
# 下载中文语音特征提取器
huggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./models/chinese-wav2vec2-base推理执行
# 单卡推理(需 >64GB VRAM,启用 --cpu_offload 可降至 40GB)
bash inference_script_single_gpu.sh
# 多卡推理(8×H800,实现实时 32 FPS)
bash inference_script_multi_gpu.sh开源地址
项目地址:https://github.com/Soul-AILab/SoulX-FlashTalk
Hugging Face 模型:https://huggingface.co/Soul-AILab/SoulX-FlashTalk-14B
