 夜雨聆风
夜雨聆风





PDF翻译工具重磅更新!Markdown输出功能解锁,翻译更智能、格式丰富
大家好!近期PDF翻译工具迎来了一波密集更新,聚焦翻译智能性、文档格式兼容性、使用体验三大核心维度。2月4日至今的多项优化,解决了格式错乱、翻译不连贯、特殊内容被误改等痛点,让PDF翻译更贴合日常使用场景。快来一起看看这些实用的新功能吧~
一、翻译更智能✨ 精准度&连贯性双提升
1. 语义合并可开关,按需选择翻译模式
新增「启用语义块合并」复选框,支持语义合并/非合并两种翻译模式:
-
开启合并:文本按语义连贯翻译,阅读体验更佳; -
关闭合并:按原始文本块逐段翻译,精准匹配原文布局;
同时支持使用大语言模模型进行语义判断的功能,大幅提升翻译连贯性。

2. 页眉页脚识别更精准
针对页眉页脚误判问题,我们做了双重优化:
-
识别阈值从50%提升至70%,减少无效识别; -
仅分析PDF页面顶部/底部区域的文本,彻底避免正文被误判为页眉页脚。
3. 特殊内容保护,URL/代码段原样保留
新增核心规则:URL地址、代码段不翻译,完全保留原始格式! 无论是技术文档里的代码片段,还是论文中的链接,翻译后再也不会出现链接失效、代码错乱的问题。
二、格式更完美📄 Markdown/Word体验大升级
1. 全新支持Markdown输出
这是本次更新的重磅功能!
-
基于PDF原始布局生成规范Markdown文档,表格、图表位置1:1还原; -
支持Markdown文件+图片打包下载,生成的文本无冗余代码块标记,直接可用; 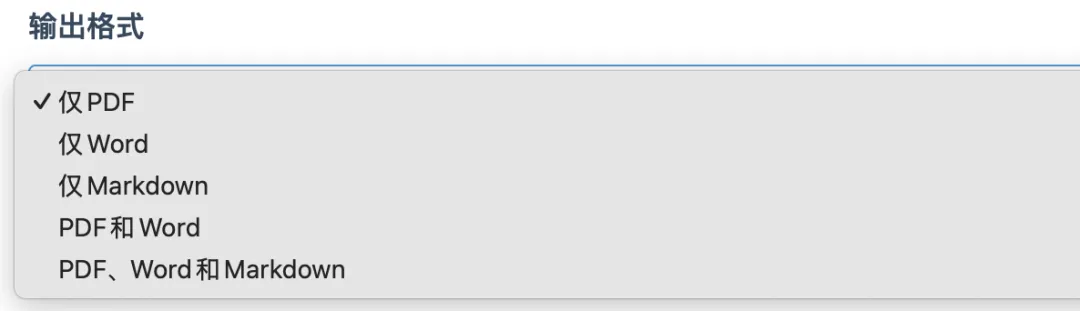
2. Word文档生成优化
之前Word生成后图表错位、样式混乱,这次进行了修复:
-
按垂直位置排序页面元素,图表/表格位置不会乱跑; -
100%保留原文字体、大小、颜色,解决样式继承、空白页问题; -
简化生成流程,仅用合并后的翻译结果生成,效率更高、质量更稳。
3. 标题识别更精准
优化语义分析提示词,明确标题的识别规则:
-
标题不与正文/其他标题错误合并; -
新增多组测试用例,覆盖各类标题场景。
三、💡 老朋友如何体验新版本?
-
拉取最新代码: git pull origin main(或develop分支); -
重新安装依赖: pip install -r requirements.txt; -
正常启动服务: python app.py,即可体验优化后的功能。
四、新朋友从头安装
1. 克隆仓库
git clone https://gitee.com/chunju/pdfTrans.gitcd pdfTrans2. 配置环境变量
-
复制 .env.example文件为.env -
在 .env文件中配置各翻译模型调用API的密钥
cp .env.example .env# 编辑.env文件,添加API密钥可以使用下面两个推荐链接注册 Aiping或者 硅基流动,你我应该都有赠费,注册完成后申请API Key:
https://www.aiping.cn/#?invitation_code=PUHXPA
https://cloud.siliconflow.cn/i/OFUfQfNj
3. 安装依赖
pip install -r requirements.txt五、使用方法
启动Web服务
python app.py访问Web界面
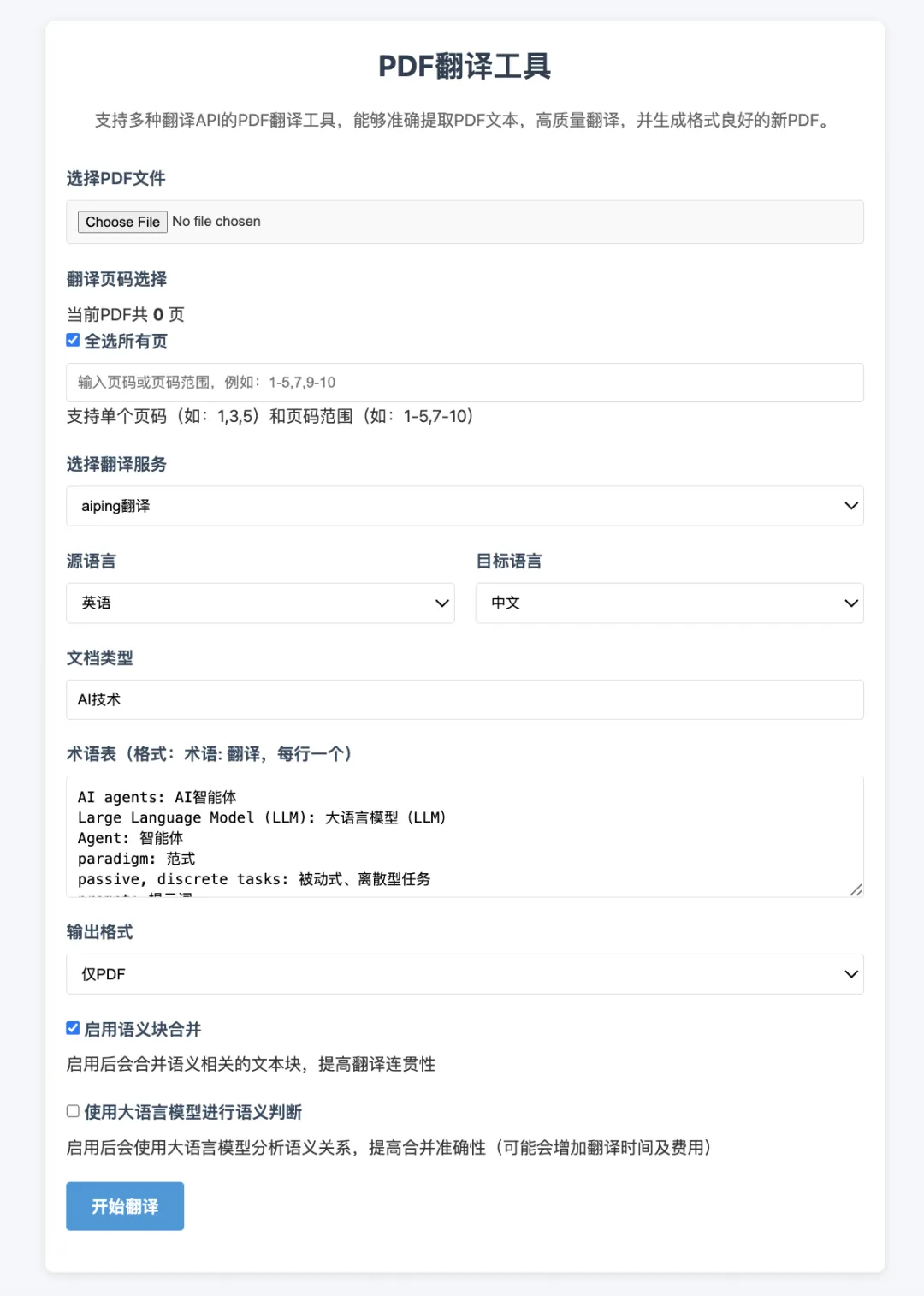
-
打开浏览器,访问 http://localhost:5000 -
上传PDF文件 -
系统自动检测并显示PDF总页数 -
选择翻译页码范围(可选,默认全选所有页) -
支持单个页码(如:1,3,5) -
支持页码范围(如:1-5,7-10) -
可以混合使用(如:1-3,5,7-9) -
选择翻译服务和目标语言 -
选择输出格式 -
点击”翻译”按钮 -
等待翻译完成,下载翻译后的文件
六、结语&反馈💬
本次更新聚焦「更智能、更精准、更易用」,解决了大家反馈的核心痛点。如果在使用过程中有任何问题、建议,欢迎在本文或后台留言。
我会持续打磨功能,让PDF翻译工具更贴合你的使用需求~
✨ 关注【智践行】,获取工具最新更新、使用技巧,还有更多实用内容分享~
