 夜雨聆风
夜雨聆风





AI工程化实践:抵制Word排版,从改进工作流做起
▶ 本文内容完全由作者撰写,无任何AI辅助创作
大家好,我是对“狗屁工作”本能感到厌烦和抵触,在AI的加持下,迫切想要找到方法解决的技术传播者睿齐。
前两天,一位研发同事,拧着眉毛、面露难色地找到我。显然,她已经竭尽所有尝试,到了实在走投无路的地步,才不得不开口求助于我这个“专业人士”:怎么把Word文档的页码改连续?
我的眼泪瞬间流了下来:人家好歹也算是技术传播领域的行业专家(自封的),你让我处理Word排版,这和让计算机科学与技术专业的学生组装电脑,有什么区别?
虽然很多时候我也会长舒一口气,稳定情绪,安慰自己说:Word排版不过是举手之劳。但如果是,很多很多人,日复一日地,付出着巨大努力,与页码连续进行着艰苦卓绝的斗争呢?……
于是我决定:抵制Word排版,从改进工作流做起。

基本思路
在与研发同事的调研中,我了解到,他们更倾向于采用MarkDown文件的轻量排版,更胜于Word。那我们就从MarkDown出发,大体的工程思路思路是:
1)设计LaTeX模板,包含必要的规范化排版,如封面、页脚等;
2)采用MarkDown开发方式,专注文档的【内容开发】;并且对内容架构进行轻量化排版;
3)使用Pandoc工具将MarkDown文件转换为PDF文档;转换过程中根据文档交付质量要求:
-
套用LaTeX模板;
-
自动生成TOC目录;
-
自动生成文档名称和版本号等变量信息等。
适用场景
理论上适用于一切需要简化Word文档开发,降低排版成本的场景;但是考虑到我们只是初步尝试,积累有限,所以优先选择对于交付质量要求较低的场景。
目前,我们已在软著材料场景输出Demo。经过【知识产权工程师】确认,输出PDF文档满足发布要求:
1)内容要求:
-
包含【封面】【目录】【内容】;
-
内容:符合软著要求。
2)排版要求:
-
封面:【文档名】+【版本号】;
-
目录:正确显示内容架构;标题和页数与实际页面相符;
-
页面:包含页脚。
工作流
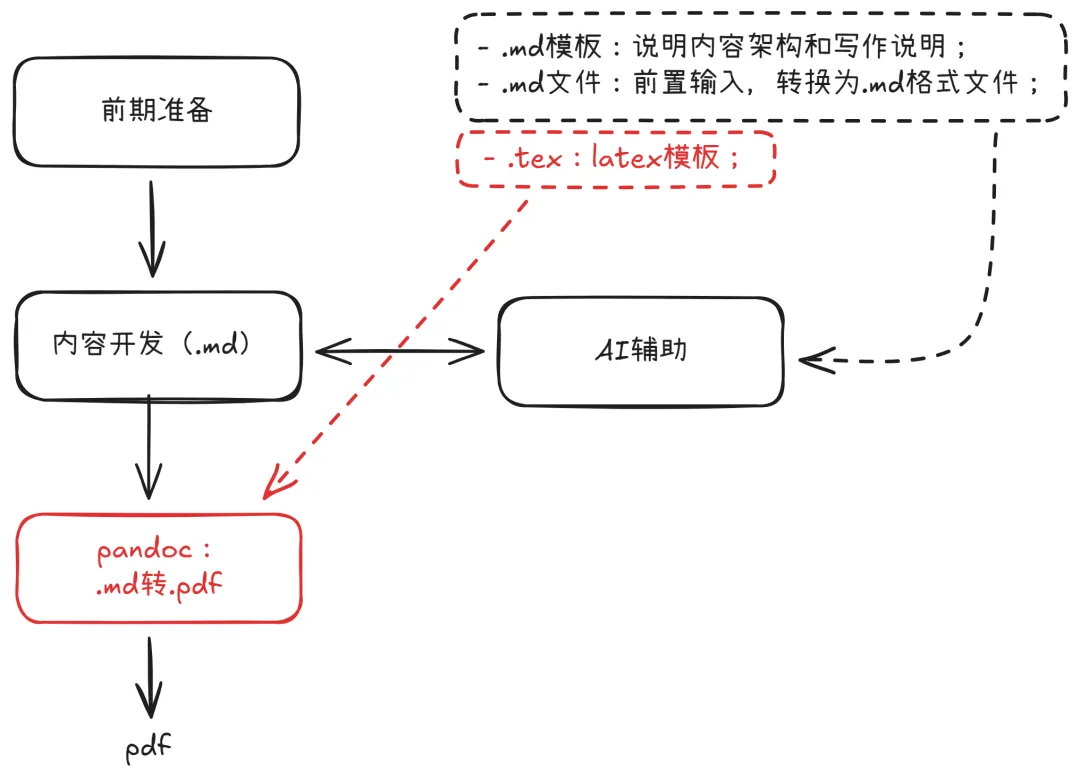
前期准备
1)输出LaTeX模板,定义满足交付目标的PDF样式规格;
2)输出Markdown模板,用于说明内容架构和写作说明,指导AI辅助进行文档内容开发;
3)整理参考文档,并转换为Markdown文件,便于AI处理。
内容开发
1)参考【Markdown模板】定义的【内容架构】和【写作说明】;
2)基于已有【Markdown文件】内容;
3)借助AI辅助进行文档开发;
4)以Markdown格式,输出目标文件。
文档转换
1)使用Pandoc工具;
2)按照LaTeX模板指定的样式规格;
3)将Markdown格式的文件,转换为PDF文件。
本文主要聚焦【文档转换】部分的实践分享;【内容开发】部分的实践或许会放到后面的文章中分享。
个人实践
接下来,我将以演示指令的方式,说明如何利用AI辅助开发,实现工作流核心步骤(md2pdf)的开发,并且以Python脚本的形式,对功能进行封装,形成相对固定的用户接口,以简化Pandoc操作。
开发工具
-
cursor:用于LaTeX模板、Pandoc命令行代码和Python脚本开发;
-
Pandoc:用于将Markdown文件转换为PDF文件。
系统环境
-
已安装Pandoc工具。官网链接:https://www.pandoc.org/
-
已部署tex环境,同Sphinx的latexpdf场景,可选安装TeX Live、MiKTeX或texmaker。
创建template.tex模板
cursor指令:
请帮我输出一个template.tex文件,要求:
1)这个文件将被用于,在使用Pandoc工具将md文件转换为pdf文件时,作为模板使用;
2)这个文件模板应至少包含【封面】【目录】【正文】以及【页码】;
3)封面应包含2个变量:【文件名】和【版本号】
4)请尽量考虑到,在进行md文件转pdf过程中,可能遇到的报错情况,在模板中包含相应解决方案。
输出并保存:template.tex
生成Pandoc命令
cursor指令:
指定文件:
@Sphinx文档系统工程实践目录.md
@template.tex
我想要使用Pandoc工具,将源文件Sphinx文档系统工程实践目录MarkDown文件转化为PDF文件,并且要求:
1)转换PDF需要套用template.tex模板,确保发布样式正确;
2)转换后的PDF中应自动生成目录;
3)转换后的PDF中应自动生成页码;
4)文档封面的名称与源文件的文件名一致;
5)文档封面的版本号为V1.0
请在1行内输出可以执行的Pandoc的命令行代码。
输出:
pandoc “Sphinx文档系统工程实践目录.md” -f markdown -o “Sphinx文档系统工程实践目录.pdf” –pdf-engine=xelatex –template=”template.tex” –toc filename=”Sphinx文档系统工程实践目录” -V version=”V1.0″
生成Python脚本和使用指南
cursor指令:
请帮我编写一个Python脚本。
输入:
-f 指定1个MarkDown格式文件;必选
-t 输入文档名称;可选;默认值:文档名称与当前文件名保持一致;
-v 输入文档版本;可选;默认值:1.0
功能:
1)执行Pandoc工具,将输入的MarkDown文件,转换为同名.pdf文件。
2)转换后的PDF应套用当前工程目录下的template.tex模板,确保发布样式正确;
3)转换后的PDF中应自动生成目录;
4)转换后的PDF中应自动生成页码;
5)文档封面的名称与-t参数输入一致;
6)文档封面的版本号与-v参数输入一致。
编码要求:
1)请在代码中添加必要的错误处理,确保代码健壮;
2)请在出现异常时,输出必要错误说明,帮助排查问题;
3)由于脚本涉及编译操作,执行时间较长,请给出必要进度说明,避免出现假死状态。
参考示例:
pandoc “Sphinx文档系统工程实践目录.md” -f markdown -o “Sphinx文档系统工程实践目录.pdf” –pdf-engine=xelatex –template=”template.tex” –toc filename=”Sphinx文档系统工程实践目录” -V version=”V1.0″
输出:
1)md2pdf.py:Python脚本,保存到当前工程目录;
2)md2pdf.md:使用指南,保存到当前工程目录。
工程目录
md2pdf/
├── template.tex
├── md2pdf.py # 转换脚本
├── md2pdf.md # 转换脚本使用说明
└── 测试文件.md # 待转换的.md文件
执行以下命令,即可按照template.tex模板定义的样式规格,将MarkDown格式的【测试文件】,转换为PDF文件,文件名默认为【测试文件】,版本号为【V1.0】:
python md2pdf.py -f Sphinx文档系统工程时间目录.md -v V1.0
转换后效果:

不过后来听公司的博士说,市面上已有类似的工具,可以实现相同的功能。不过虽然如此呢,我依然觉得自己借助AI辅助编程手搓实现很酷,是因为通过这个实践:
1)我们向团队展示了,文档工程不是“耍笔杆”,也不是专业做排版,而是通过工程化化的方式,解决文档问题;
2)在AI辅助编程的buff加持下,工程实施的门槛和成本大大降低,即便在资源有限的情况下,依然可以快速实践落地,至少达到Demo可展示的水平;
3)虽然深陷Word开发的泥沼之困,但我们依然相信,通过更多的实践展示,可以一寸一寸地推动工作流改进,因为工程化和智能化,必然是未来技术文档的发展方向。
今天的分享,就是这些内容。如果你喜欢这篇文章,觉得有所启发和帮助,记得点赞和分享;如果对这个话题感兴趣,或者有不同意见想要表达和交流,就留言告诉我吧。

其他推荐:
这次他们说好要“讲真的”| 传播
在座都别吵了,你们还有我 | 技术传播

睿齐
技术传播者
自由摄影师
知识管理实践教练
品牌内容策划
汪力迪
公众号:techcomm / htstory
微信号:bgrichi
邮箱:hash_0813@163.com

