 夜雨聆风
夜雨聆风





大模型知识库构建使用minerU解析pdf使用VLM模式和pipeline模式比对分析
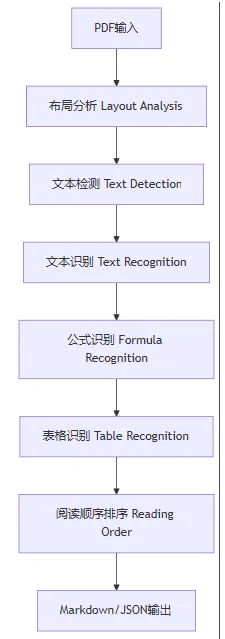
Pipeline模式采用传统的多模型串联架构,将复杂的文档解析任务分解为多个专业子任务,每个子任务由专门的模型负责。
|
任务类型 |
描述 |
模型 |
|
|
布局检测(Layout Detection) |
定位文档中的不同元素:包括图像、表格、文本、标题、公式 |
DocLayout-YOLO_ft, YOLO-v10_ft, LayoutLMv3_ft |
|
|
公式检测(Formula Detection) |
定位文档中的公式:包括行内公式和块公式 |
YOLOv8_ft |
|
|
公式识别(Formula Recognition) |
将公式图像识别为 LaTeX 源代码 |
UniMERNet OCR |
https://github.com/opendatalab/UniMERNet/blob/main/README-zh_CN.md |
|
OCR |
从图像中提取文本内容,包括位置和识别 |
PaddleOCR |
|
|
表格识别(Table Recognition) |
将表格图像识别为相应的源代码(LaTeX/HTML/Markdown) |
PaddleOCR识别+TableMaster识别重建, StructEqTable:InternVL2-1B |
|
|
阅读顺序(Reading Order) |
对离散的文本段落进行排序和拼接 |
暂时还未上线 |
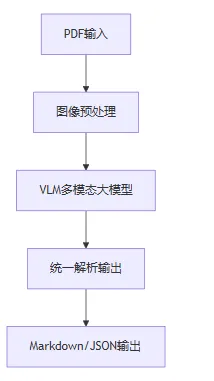
2.VLM 端到端
采用单一的多模态大模型,实现端到端的文档理解。
-
单一模型参数<1B,轻量高效 -
支持sglang加速,峰值吞吐>10,000 tokens/s -
端到端统一处理,避免误差累积
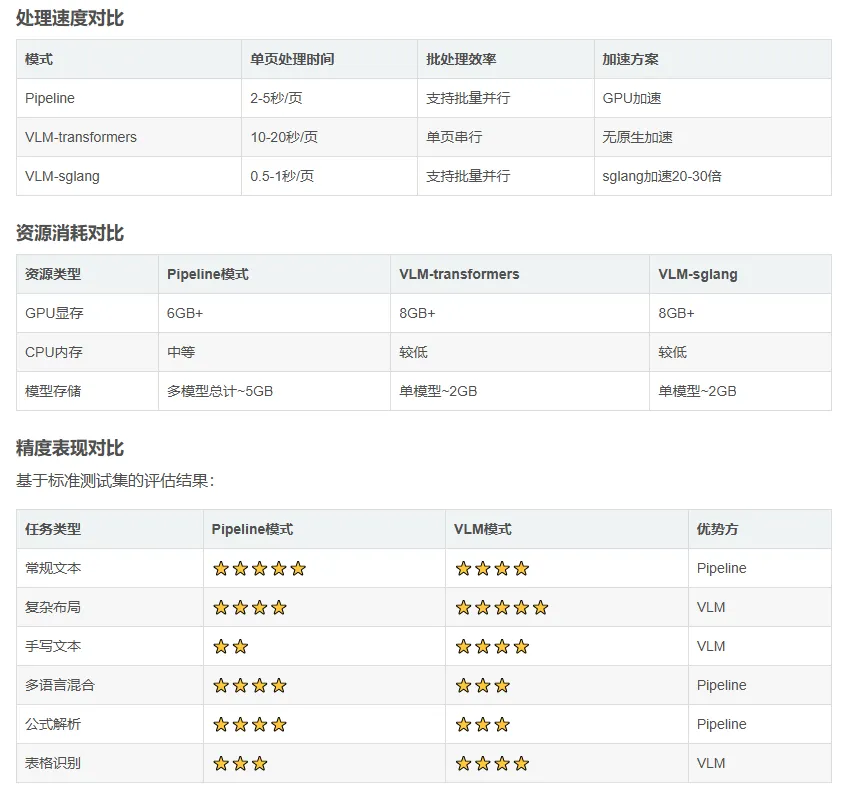
- 追求稳定性和批量处理
→ 选择Pipeline模式 - 需要处理复杂版面或手写内容
→ 选择VLM模式 - 有高性能GPU和实时性要求
→ 选择VLM-sglang模式 - 资源受限环境
→ 选择Pipeline模式CPU版本 - 混合场景
→ 可根据文档类型动态选择模式
