 夜雨聆风
夜雨聆风





新一代矢量切片格式 MLT 源码级深度解析
解构数据之“列”,方能重构空间之“维”
摘要
随着移动互联网和智能设备的普及,地图应用已经渗透到我们生活的方方面面。从导航软件到外卖平台,从出行服务到社交网络,地图数据的需求量呈现爆发式增长。然而,传统的矢量切片格式在处理海量地理数据时逐渐显露出性能瓶颈。MapLibre Tile (MLT) 作为一种新一代矢量切片格式,通过创新的技术架构,实现了高达6倍的压缩比和2-3倍的解码速度提升。本文将从源码层面深入解析 MLT 的技术原理,帮助初学者全面理解这一革命性的技术。

一、背景知识:什么是矢量切片?
1.1 矢量数据与栅格数据
在开始介绍 MLT 之前,我们需要先了解两个基本概念:矢量数据和栅格数据。
想象一下,你要在纸上画一幅地图:
-
栅格数据就像是用无数个小色块(像素)拼成的马赛克画。每个色块都有固定的颜色,放大后会变得模糊。常见的图片格式(如 JPEG、PNG)就是栅格数据。
-
矢量数据就像是用笔在纸上画出的线条和形状。无论你放大多少倍,线条依然清晰锐利。它记录的是形状的数学描述(如”从点 A 到点 B 画一条线”),而不是像素点。
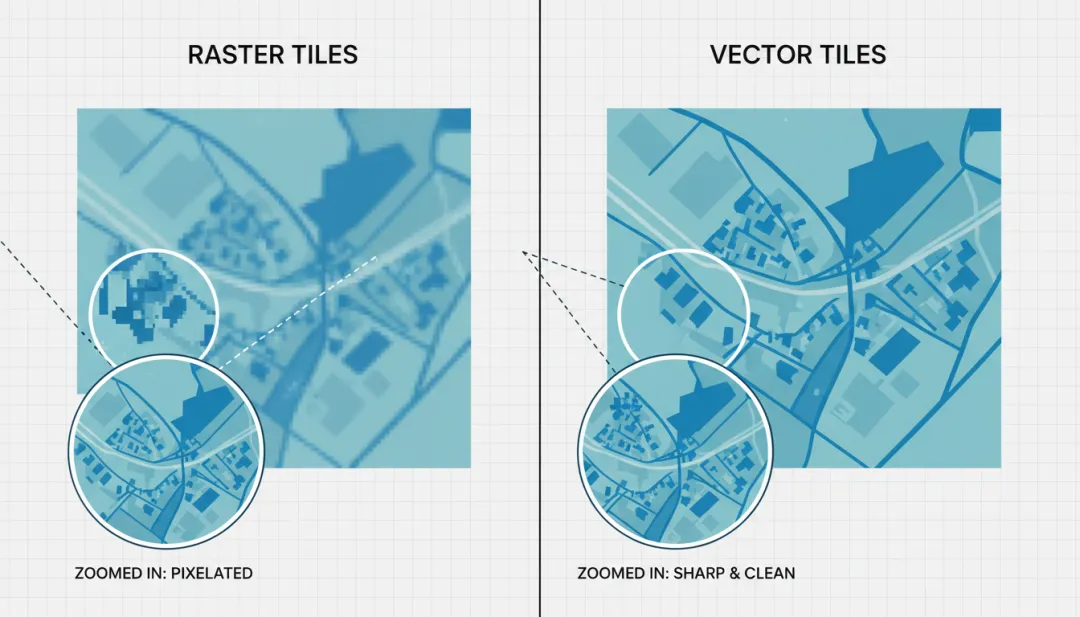
为什么地图要用矢量数据?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.2 什么是矢量切片?
矢量切片是将地球表面划分成规则的网格(就像国际象棋的棋盘),每个格子称为一个“切片”(Tile)。每个切片包含该区域内的矢量地理数据。
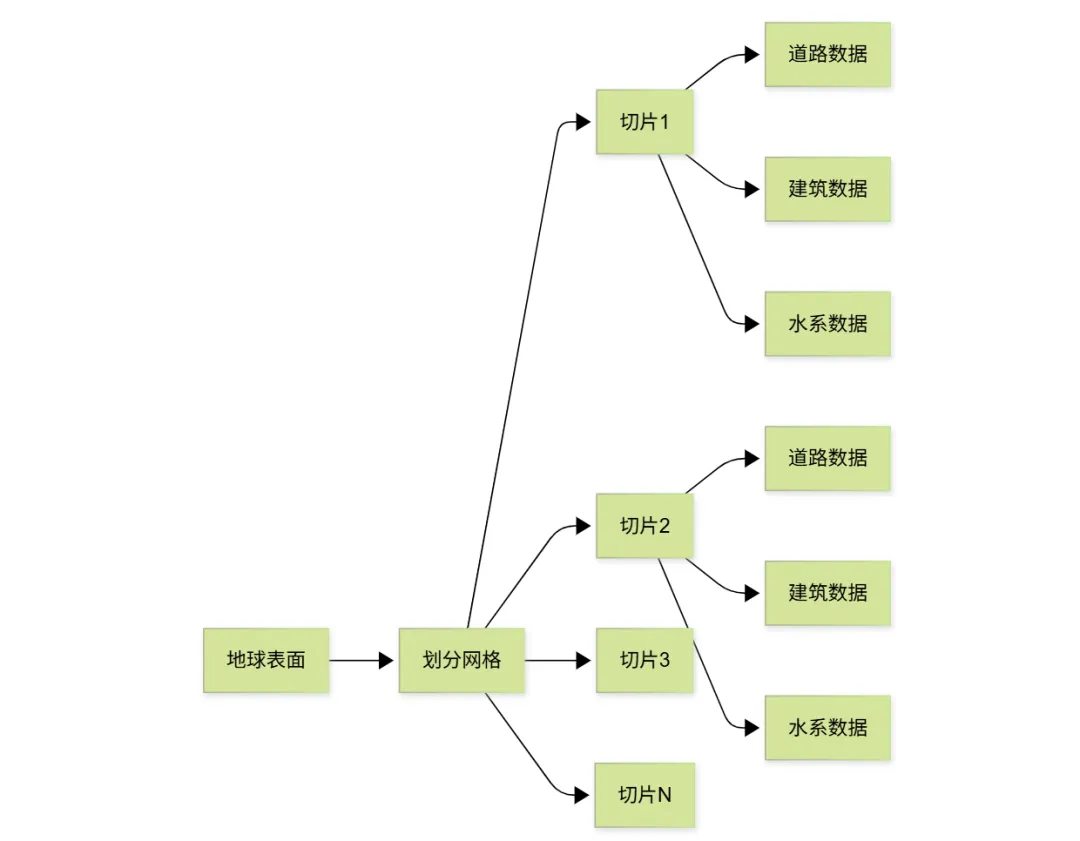
为什么需要切片?
想象一下,你要绘制整个世界的地图。如果一次性加载所有数据,文件会非常庞大,浏览器会崩溃。通过切片技术,我们只需要加载当前视野范围内的切片,这样既节省流量,又提高加载速度。
1.3 矢量切片的坐标系统
在矢量切片中,我们使用特殊的坐标系统:
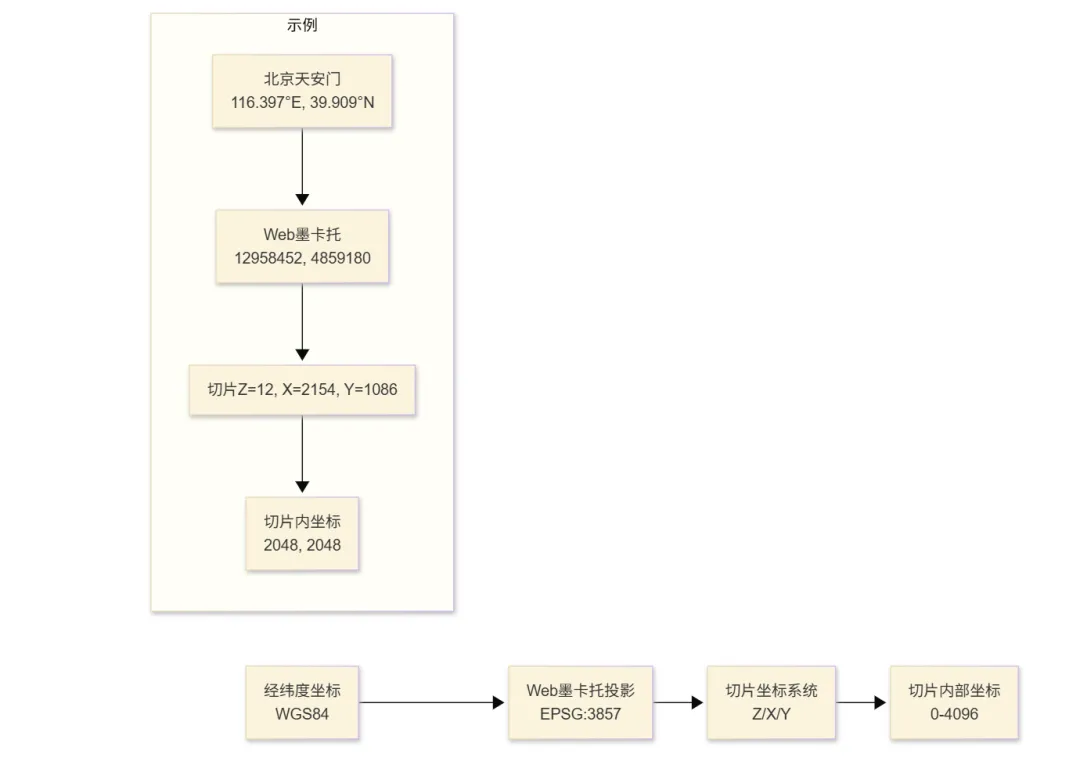
-
Z(Zoom):缩放级别,范围通常是 0-22
-
X:切片在水平方向的位置
-
Y:切片在垂直方向的位置
-
切片内部坐标:通常使用 0-4096 的整数坐标系统
二、传统矢量切片格式的局限性
2.1 Mapbox Vector Tile (MVT) 简介
MVT 是目前最广泛使用的矢量切片格式,由 Mapbox 公司开发。它基于 Protocol Buffers(Protobuf)序列化格式,具有以下特点:
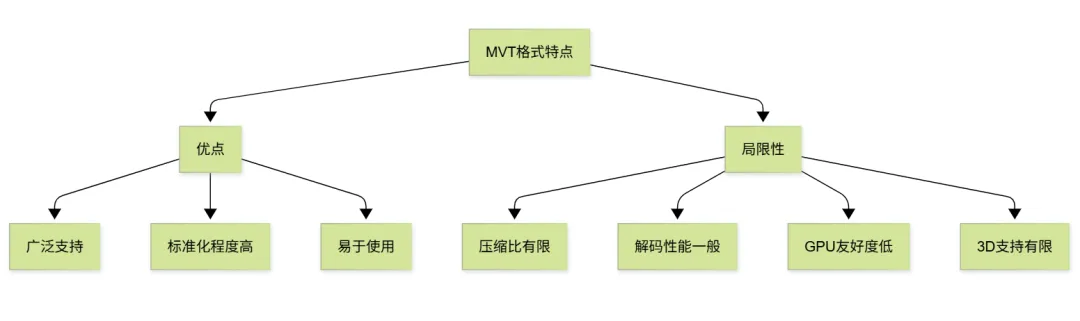
2.2 MVT的技术架构
MVT采用行式存储(Row-Oriented Storage)架构:
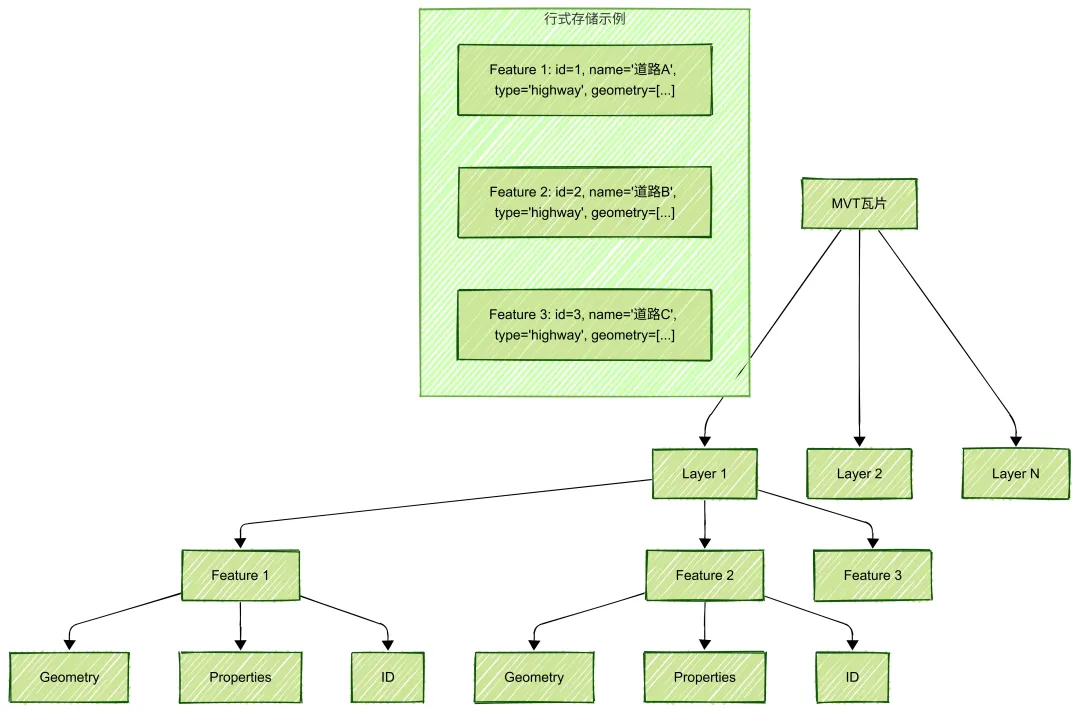
行式存储的问题:
1. 压缩效率低:不同属性的数据交错存储,难以利用重复模式进行压缩
2. 缓存利用率低:访问同一属性时需要跳过其他属性的数据
3. GPU 不友好:数据布局不适合直接加载到 GPU 缓冲区
2.3 实际案例:OpenStreetMap 数据压缩
以 OpenStreetMap 的某个切片为例,包含1000条道路数据:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可以看到,MLT 在压缩比、解码速度和内存占用方面都有显著优势。
三、MLT 的核心设计理念
3.1 MLT 的三大设计目标
MLT 的设计围绕三个核心目标展开:

3.2 列式存储 vs 行式存储
列式存储(Column-Oriented Storage)是MLT的核心创新之一。让我们通过一个简单的例子来理解两者的区别:
假设我们有3个地理对象,每个对象有ID、名称和类型三个属性:
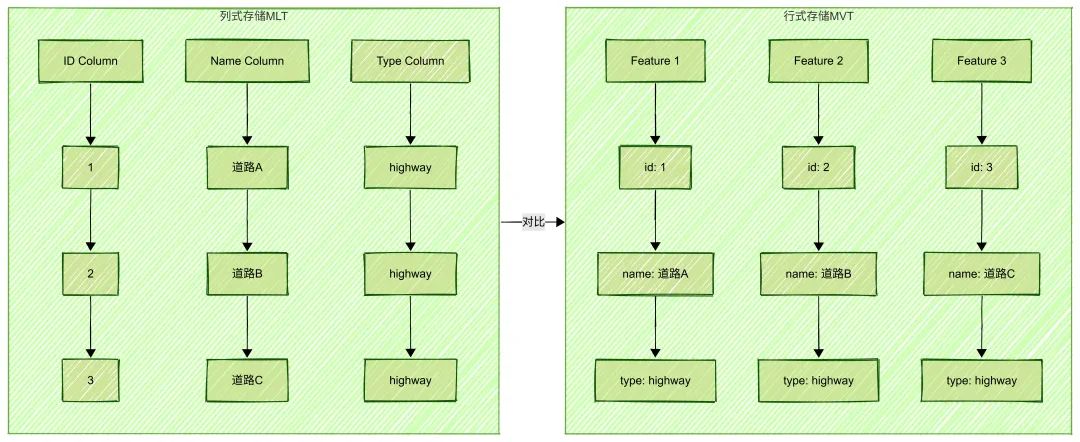
列式存储的优势:
1. 压缩效率高:相同类型的数据连续存储,更容易发现重复模式
-
例如:所有type都是”highway”,可以用RLE压缩为”3个highway”
2. 缓存利用率高:访问同一属性时,数据在内存中是连续的
-
例如:只需要读取type列,不需要跳过id和name数据
3. GPU友好:数据布局适合直接加载到GPU缓冲区
-
例如:顶点坐标可以连续存储,直接传递给GPU
3.3 MLT的整体架构
MLT 瓦片采用模块化的块结构:
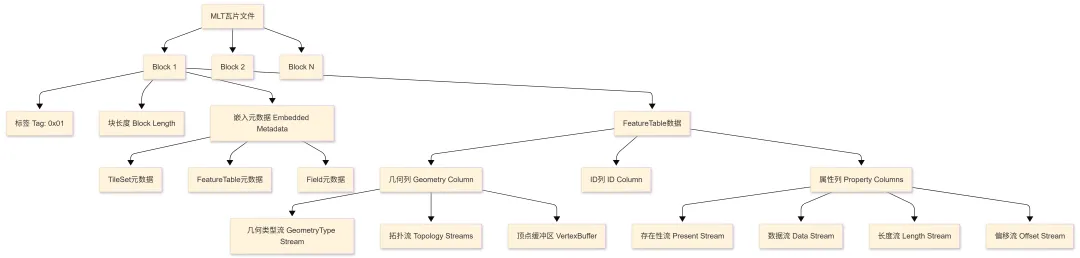
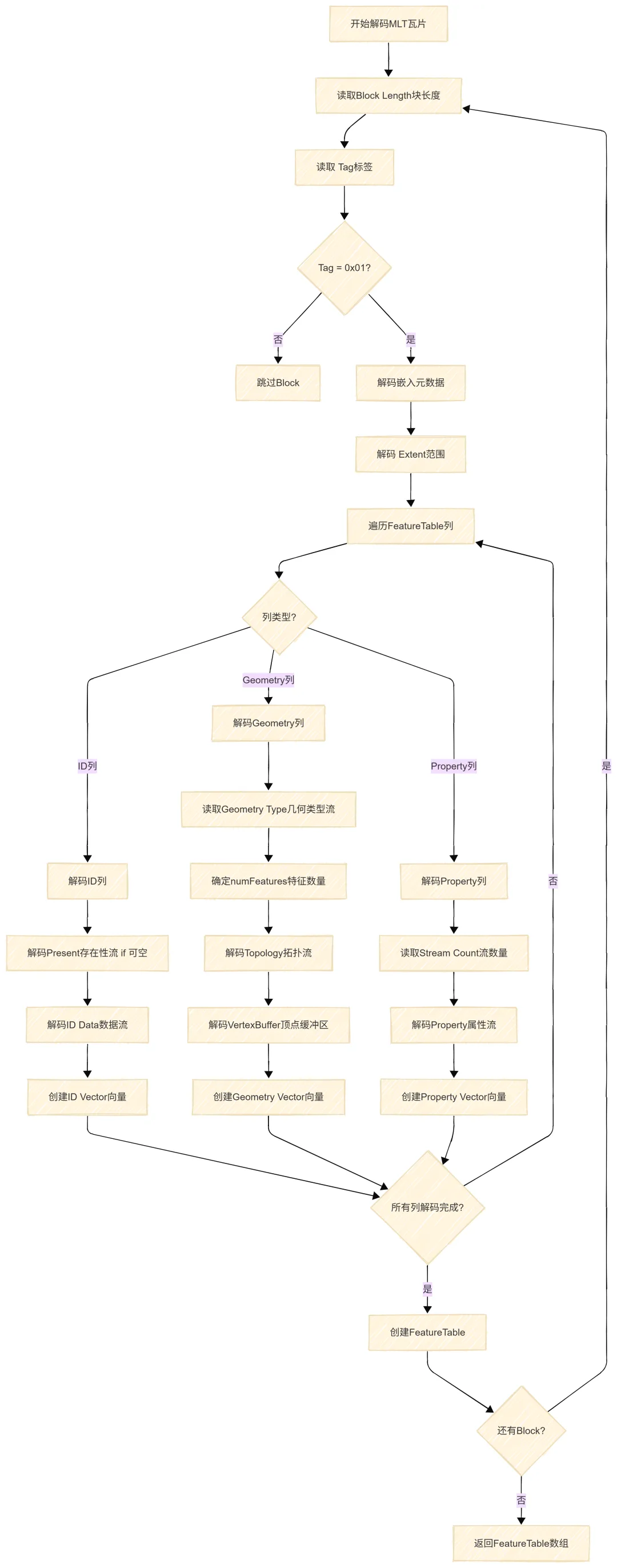
架构说明:
1. Block:每个Block包含一个 FeatureTable,可以独立解码
2. Tag:标识Block类型,0x01表示嵌入元数据格式
3. Embedded Metadata:描述 FeatureTable 的结构
4. Streams:每个列被分解为多个流,每个流独立编码
四、MLT 的编码技术详解
4.1 编码技术层次结构
MLT 采用多级编码架构,逻辑层和物理层编码可以灵活组合:
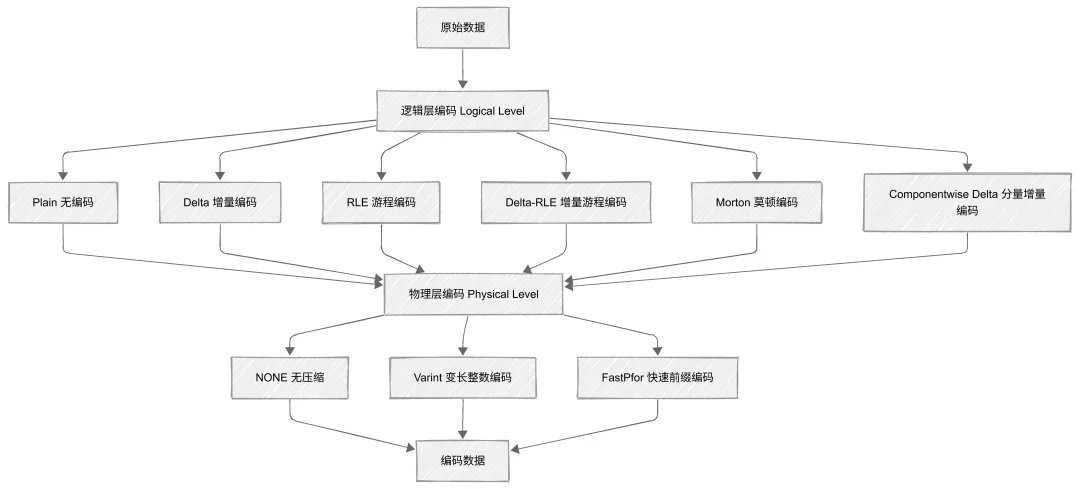
编码层次说明:
-
逻辑层编码:对数据进行语义层面的转换,如计算差值、识别重复模式
-
物理层编码:对转换后的数据进行位级压缩,如变长编码、位打包
4.2 Varint 变长整数编码
什么是 Varint?
Varint(Variable-length Integer)是一种变长整数编码,核心思想是:小整数用更少的字节存储,大整数用更多的字节存储。
Varint 编码原理
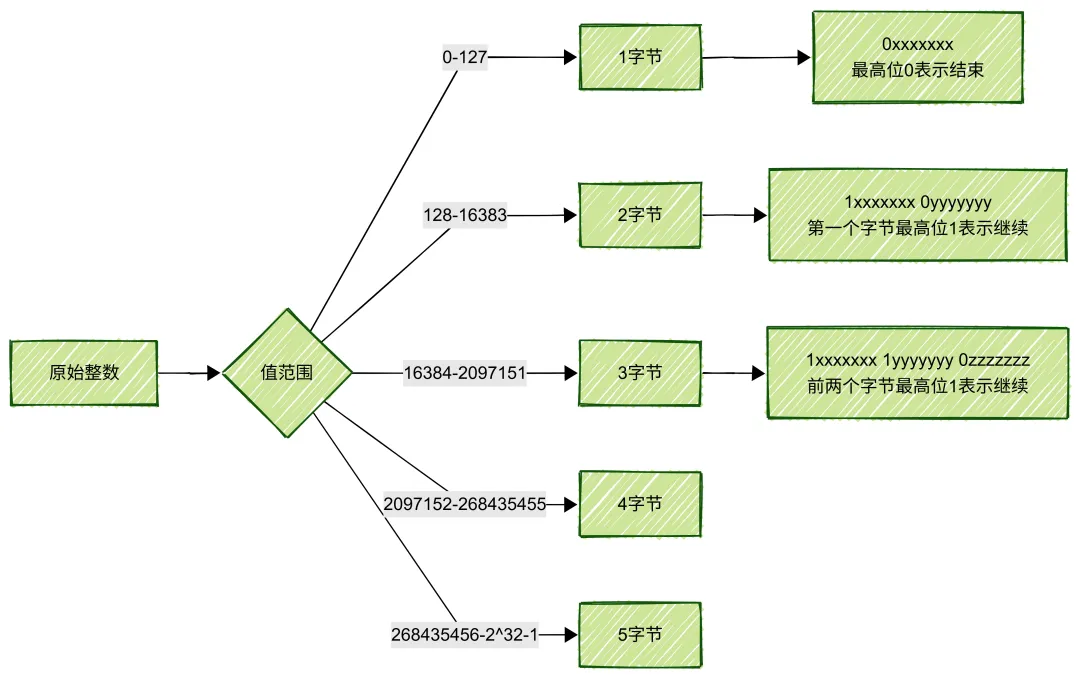
Varint 编码示例
让我们看一个具体的例子:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
为什么 Varint 有效?
在地理数据中,很多数值都比较小:
-
切片内的坐标偏移量通常在 0-4096 范围内
-
属性值(如道路类型、建筑层数)通常只有几十种可能
-
ID 在局部范围内也是连续的小整数
使用 Varint 可以将这些小整数压缩到 1-2 字节,相比固定 4 字节节省了大量空间。
4.3 ZigZag 有符号整数编码
为什么需要 ZigZag?
Varint 只对无符号整数有效,但地理数据中经常出现负数:
-
坐标增量可能是负数(向左或向下移动)
-
高程值可能是负数(低于海平面)
如果直接用 Varint 编码负数,效率会很低。ZigZag 编码解决了这个问题。
ZigZag 编码原理
ZigZag 通过一个简单的公式将有符号整数映射为无符号整数:
编码公式:ZigZag(n) = (n << 1) ^ (n >> 31)解码公式:n = (ZigZag(n) >> 1) ^ -(ZigZag(n) & 1)
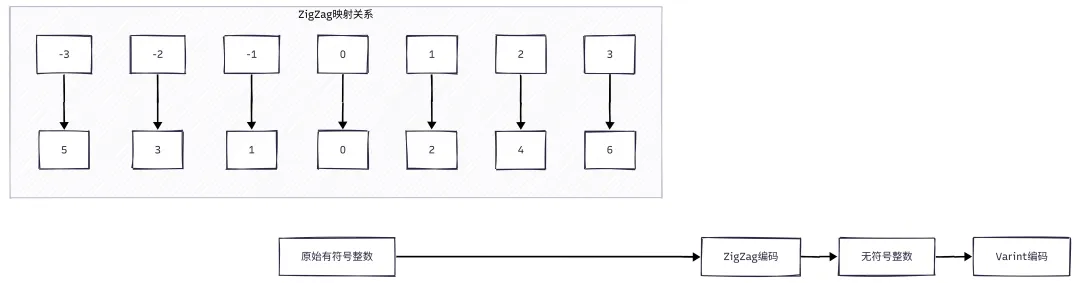
ZigZag 编码示例
| 原始值 | ZigZag 编码 | Varint 编码 | 字节数 |
|---|---|---|---|
| -3 | 5 | 05 | 1 |
| -2 | 3 | 03 | 1 |
| -1 | 1 | 01 | 1 |
| 0 | 0 | 00 | 1 |
| 1 | 2 | 02 | 1 |
| 2 | 4 | 04 | 1 |
| 3 | 6 | 06 | 1 |
ZigZag 的优势:
可以看到,经过 ZigZag 编码后,小的负数也被映射为小的正整数,可以用 Varint 高效编码。
4.4 Delta 增量编码
什么是 Delta 编码?
Delta 编码计算相邻元素的差值,存储第一个元素的完整值和后续元素的差值。
Delta 编码原理
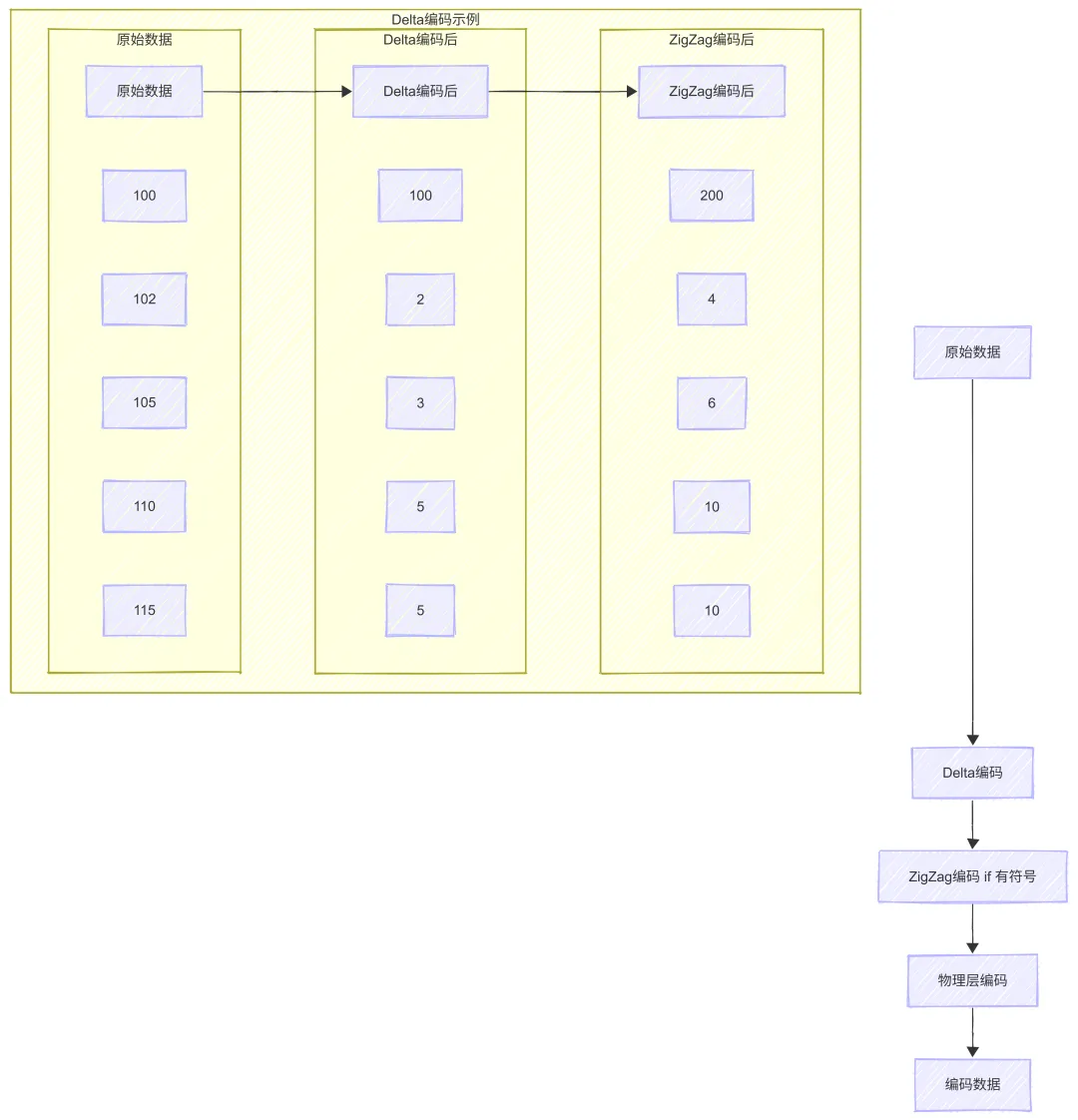
Delta 编码示例
假设有一组 ID 值:100, 102, 105, 110, 115
| 步骤 | 数据 | 说明 |
|---|---|---|
| 原始数据 | 100, 102, 105, 110, 115 | 5个值 |
| Delta 编码 | 100, 2, 3, 5, 5 | 第一个值保持,后续为差值 |
| ZigZag 编码 | 200, 4, 6, 10, 10 | 有符号整数转无符号 |
| Varint 编码 | 0x81 0x64, 0x04, 0x06, 0x0A, 0x0A | 变长编码 |
Delta 编码的优势:
1. 差值更小:相邻 ID 的差值通常很小(如2, 3, 5)
2. 压缩效果更好:小差值可以用更少的字节编码
3. 适合有序数据:ID、坐标等通常是有序的
4.5 RLE 游程编码
什么是 RLE?
RLE(Run-Length Encoding)游程编码,用于压缩重复值。它将连续重复的值替换为”运行长度-运行值“对。
RLE 编码原理
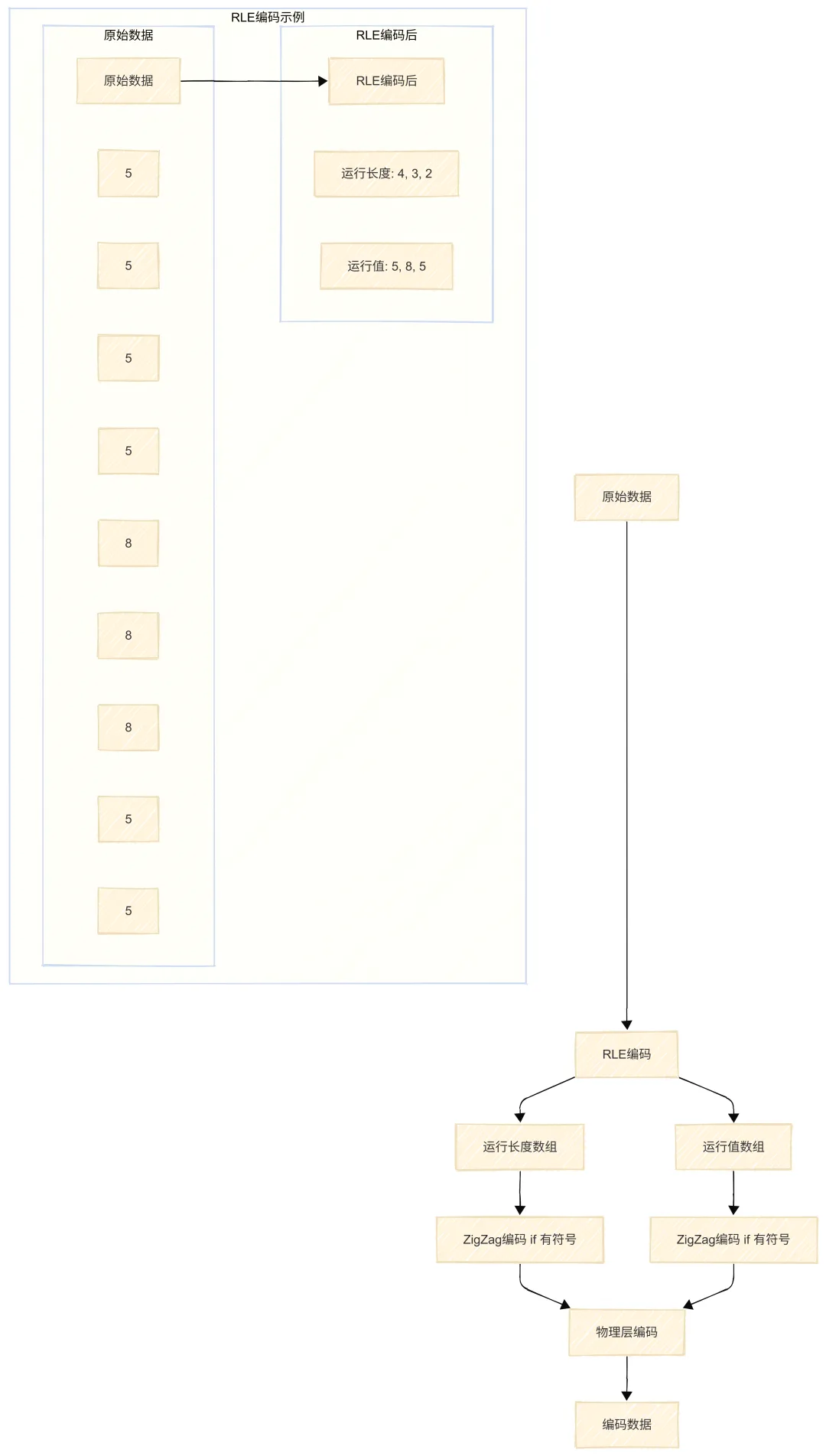
Delta-RLE 编码示例
假设有一组ID值:10, 12, 14, 16, 20, 22, 24
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
elta-RLE 的优势:
1. 双重压缩:Delta 减小数值,RLE 压缩重复
2. 适合有序且重复的数据:如 ID、坐标增量
3. 压缩比极高:对于等差数列效果显著
4.7 字符串编码技术
Dictionary 字典编码
什么是 Dictionary 编码?
Dictionary 编码将唯一字符串存储在字典中,然后使用字典索引引用这些字符串。
Dictionary 编码原理
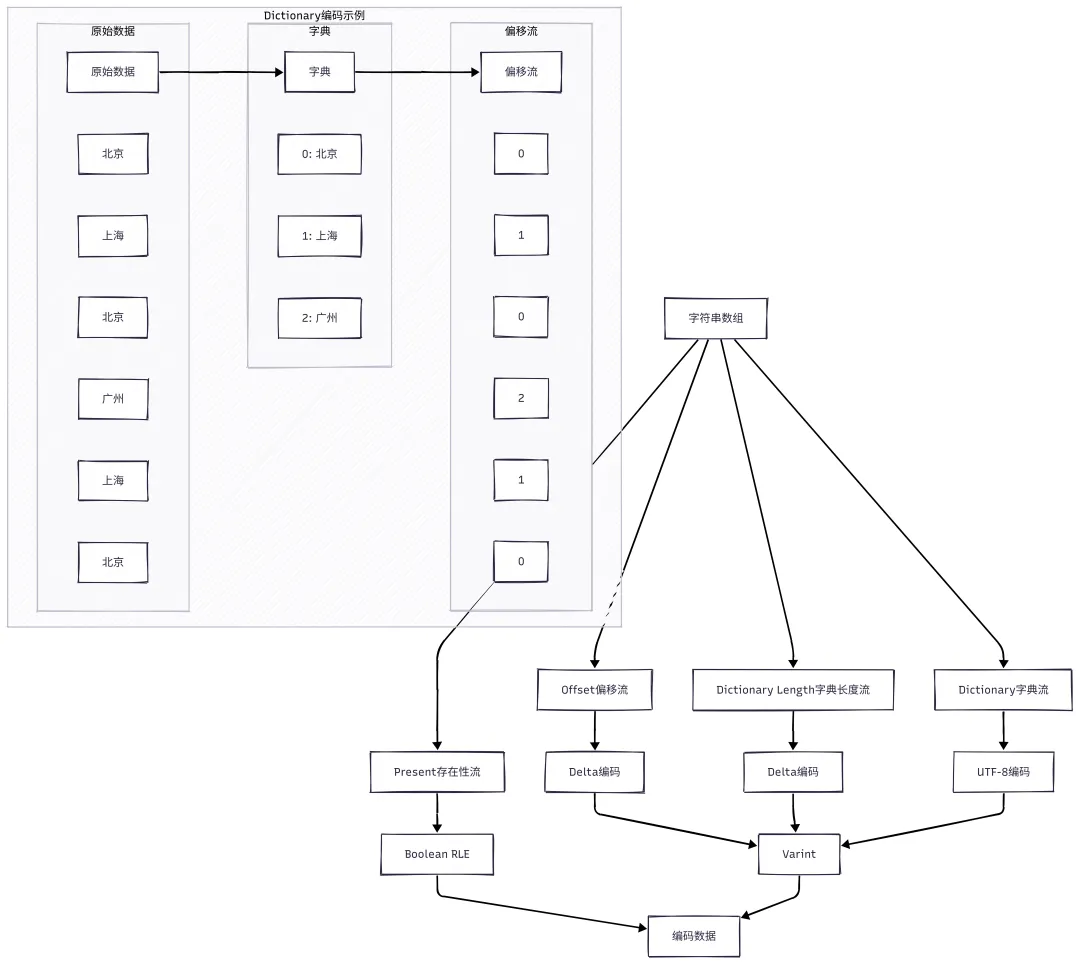
Dictionary 编码示例
假设有一组城市名称:北京, 上海, 北京, 广州, 上海, 北京
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Dictionary 编码的优势:
1. 重复字符串压缩效果好:相同的字符串只存储一次
2. 适合分类数据:城市名、道路类型等经常重复
3. 索引占用小:索引通常比字符串本身小得多
共享字典编码
什么是共享字典?
共享字典允许多个列共享同一个字典,适用于本地化数据。
共享字典编码原理
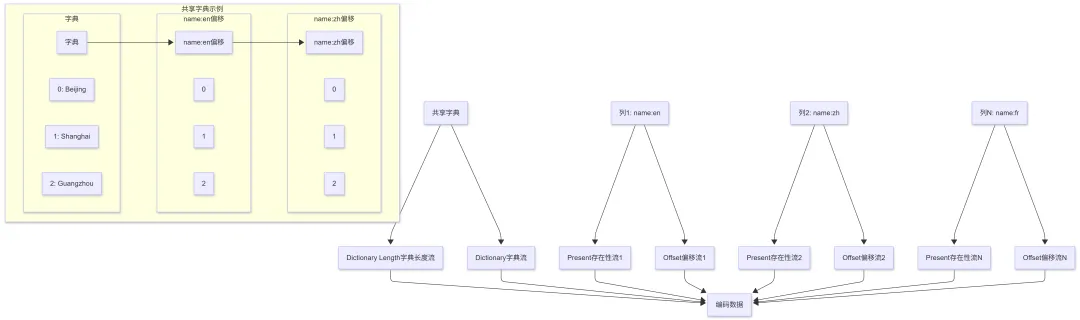
共享字典编码示例
假设有本地化城市名称:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
字典:0:Beijing/北京/Pékin,1:Shanghai/上海,2:Guangzhou/广州/Canton
共享字典的优势:
1. 避免重复字典:多个列共享同一个字典
2. 适合本地化数据:同一地点的多语言名称
3. 节省存储空间:字典只存储一次
五、MLT的解码流程详解
5.1 主解码流程
MLT的主解码流程如下:
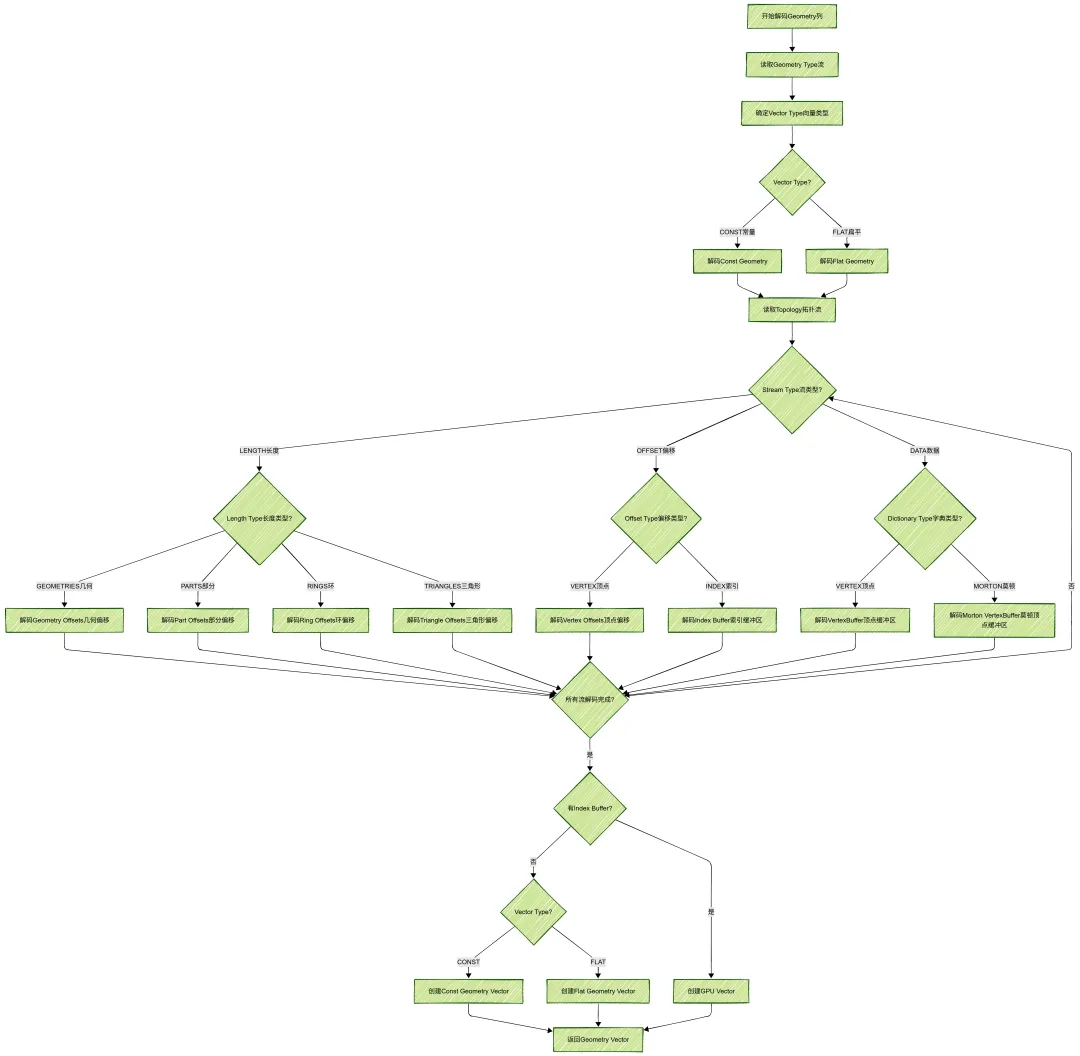
5.2 几何列解码流程
几何列的解码流程较为复杂,涉及多个拓扑流:
5.3 几何拓扑结构
MLT 使用三级拓扑结构来描述复杂几何:
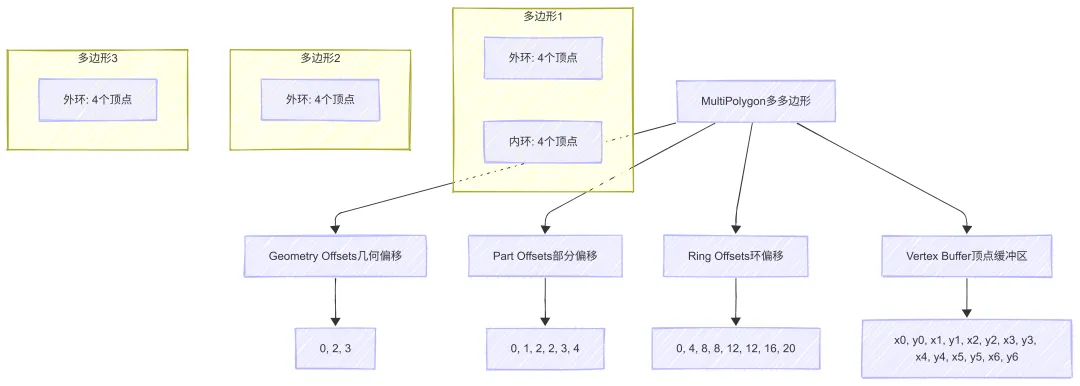
拓扑结构说明:
1. Geometry Offsets:存储每个几何对象的起始位置
-
例如:[0, 2, 3]表示第1个几何对象从索引0开始,第2个从索引2开始,第3个从索引3开始
2. Part Offsets:存储每个几何对象的各个部分的起始位置
-
例如:对于MultiPolygon,每个Polygon可能有多个Ring(外环+内环)
3. Ring Offsets:存储每个多边形的环的起始位置
-
例如:对于Polygon,可能有1个外环和多个内环
4. Vertex Buffer:存储所有顶点的坐标
-
例如:[x0, y0, x1, y1, x2, y2, …]
六、MLT 的智能向量类型系统
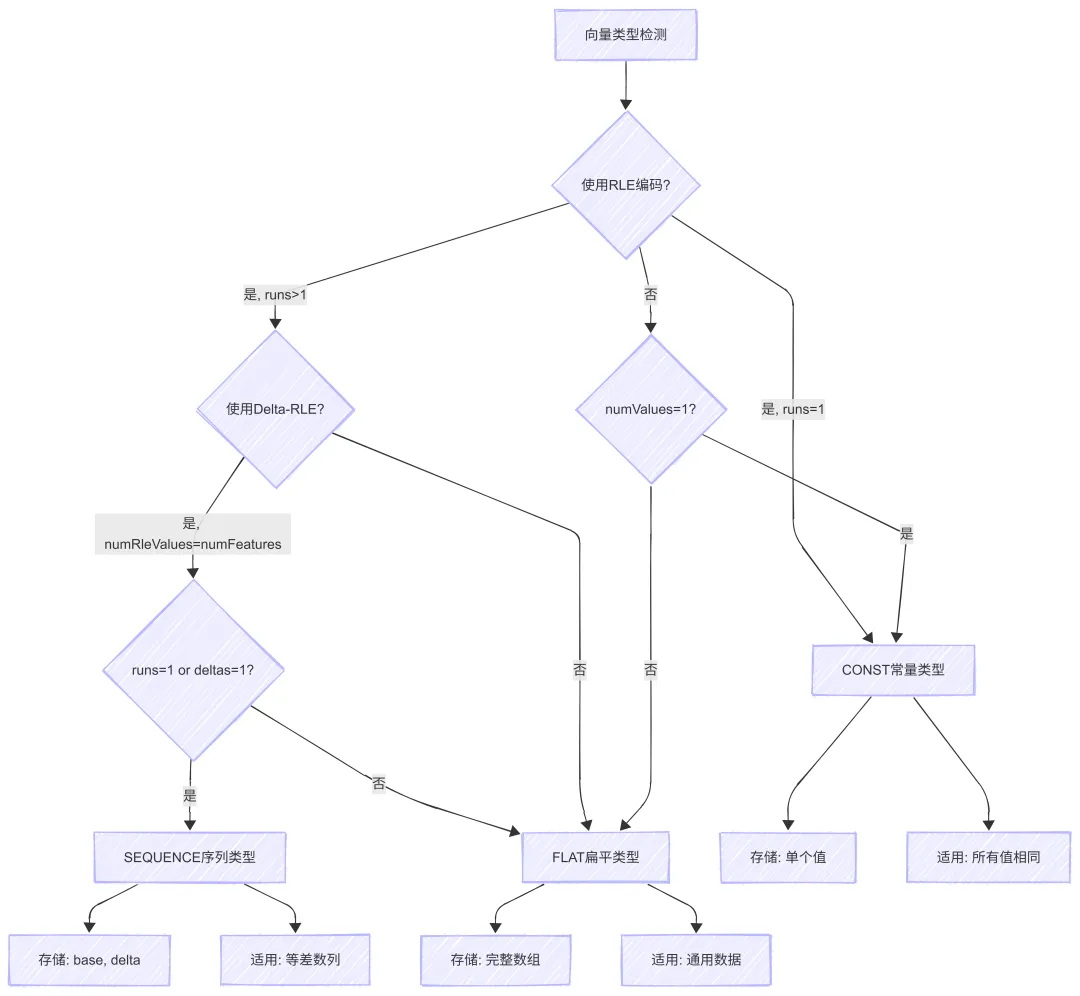
6.1 向量类型检测
MLT 定义了三种向量类型,根据数据特征自动选择最优存储方式:
6.2 向量类型对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6.3 向量类型示例
FLAT 类型示例
数据:[1, 3, 5, 7, 9]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SEQUENCE 类型示例
数据:[100, 101, 102, 103, 104]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CONST 类型示例
数据:[5, 5, 5, 5, 5]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
七、MLT 的性能优化策略
7.1 SIMD 单指令多数据优化
什么是 SIMD?
SIMD(SingleInstructionMultipleData)是一种并行计算技术,一条指令可以同时处理多个数据。
SIMD优化原理
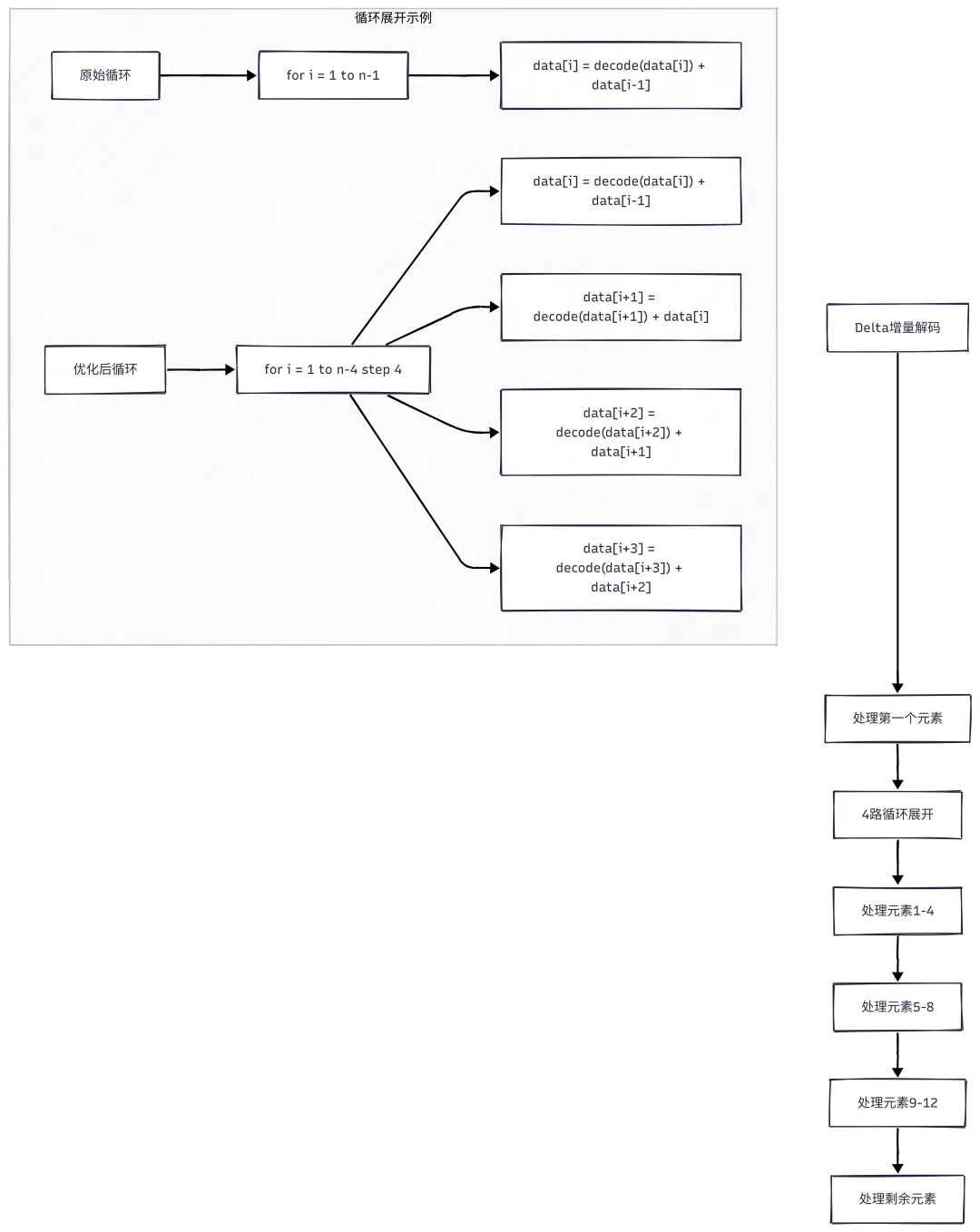
SIMD 优化示例
假设有8个 Delta 值需要解码:
|
|
|
|
|
|
|
|
|
|
|
|
SIMD 优化的优势:
1. 减少分支预测失败:循环次数减少,分支预测更准确
2. 提高指令级并行:CPU 可以同时执行多条指令
3. 提高缓存利用率:连续访问内存,提高缓存命中率
7.2 原地解码
什么是原地解码?
原地解码(In-placeDecoding)直接在原始数据缓冲区上进行修改,避免创建新缓冲区。
原地解码原理
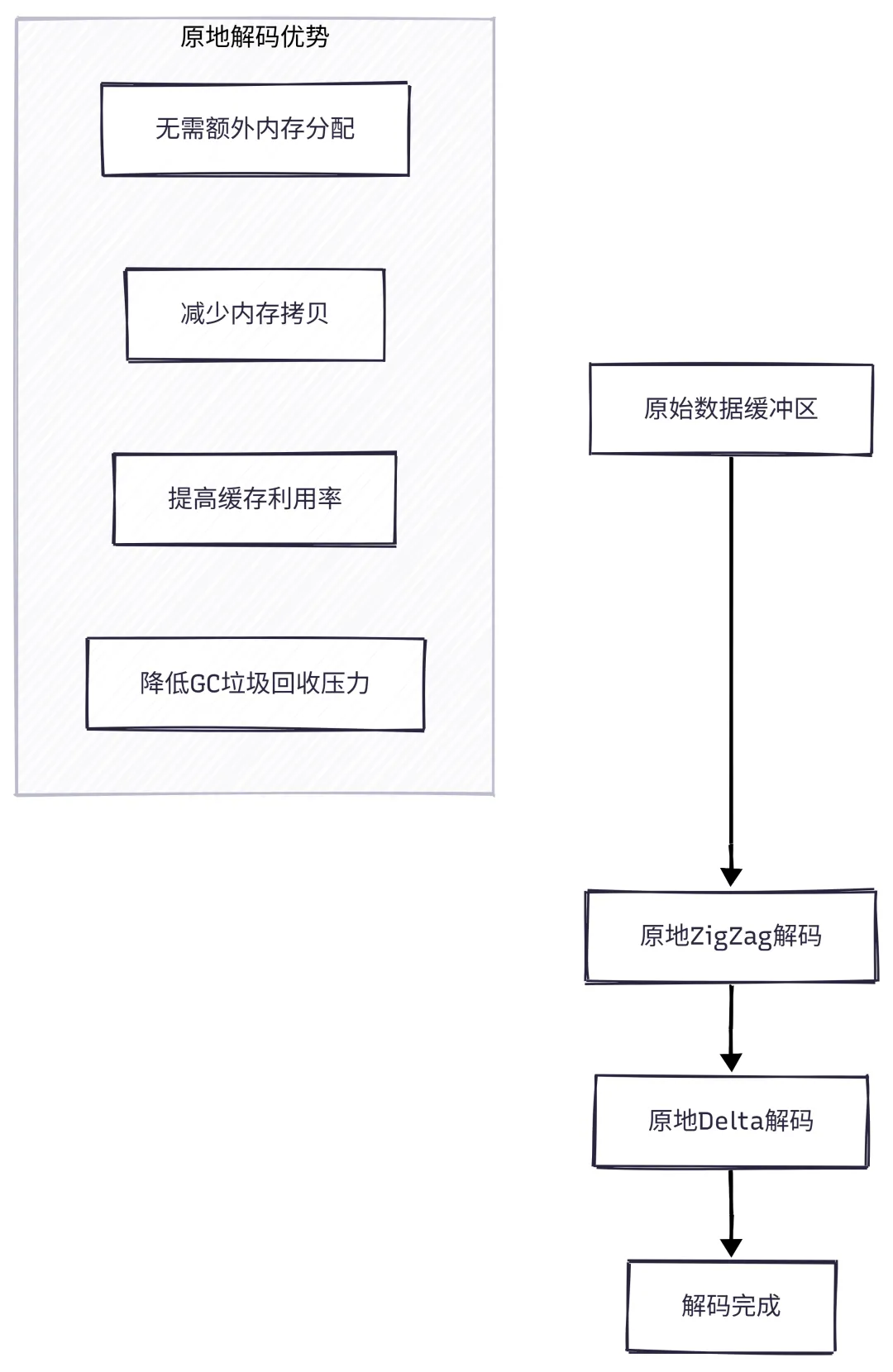
缓存友好示例
假设要访问所有 ID 值:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
缓存友好的优势:
1. 提高缓存命中率:连续访问同一列的数据
2. 减少内存访问:缓存命中时不需要访问主存
3. 提高性能:内存访问是性能瓶颈之一
八、MLT 与 MVT 的对比分析
8.1 架构对比

8.2 性能对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8.3 实际测试数据
以 OpenStreetMap 的某个切片为例:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
九、MLT 的应用场景

十、MLT 的未来发展与挑战
10.1 未来发展方向

10.2 面临的挑战

十一、总结
MLT 矢量切片格式通过以下创新技术实现了高性能和高压缩比:
11.1 核心创新
1. 列式存储:提高压缩比和缓存利用率
2. 多级编码:逻辑层 + 物理层编码组合
3. 智能向量类型:自动选择 FLAT/SEQUENCE/CONST
4. GPU 友好布局:SoA 布局便于直接加载
5. 原地解码:减少内存分配和拷贝
6. SIMD 优化:循环展开和向量化
11.2 技术优势
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11.3 适用场景
MLT 特别适合以下场景:
1. 大规模地图服务:存储和传输成本高
2. 实时地图渲染:需要低延迟解码
3. 移动端地图:网络条件和设备性能有限
4. 3D 地形渲染:需要高性能渲染
5. 线性引用应用:需要 RangeMap 和 M 值支持
6. Overture Maps:需要复杂类型支持
7. WebGPU 渲染:需要 GPU 友好布局
11.4 未来展望
作为一种面向未来的矢量切片格式,MLT 不仅解决了当前 GIS 数据处理的性能瓶颈,也为下一代地空间数据格式如 Overture Maps 等提供了有力支持。随着生态系统的不断完善和技术的持续演进,MLT 有望成为 GIS 行业的主流矢量切片格式,推动地理信息服务进入一个新的时代。

