 夜雨聆风
夜雨聆风





【AI】Skill:给 AI 写一份入职文档
【AI】Skill:给 AI 写一份入职文档
Sam Altman 说过一句话,大意是:目前很多团队构建 Agent 的方式,就像在带一群”初级员工”——你给他布置任务,他给你交活,但产出达不到上线标准,你得反复质检、打回、拼接。表面上 AI 在干活,实际上管理、审核、修补的成本全转移到了人类身上。
这不是自动化,这是“返工自动化”。
Anthropic 把这个问题讲得更直白:AI 应用行业过去一年的默认做法——为每个业务需求”造”一个独立 Agent——本质上是用”复制粘贴”来扩展能力。这不是在沉淀资产,而是在堆积工程负债。
那怎么办?Anthropic 给出的答案是一次范式转换:别造人了,写本入职手册吧。
❝
旧模式(造人):财务缺人就造”财务 Agent”,法务缺人就造”法务 Agent”。
新模式(教书):保持一个高智商的通用 Agent,给它发不同的”入职手册”(Skills)。
这本”入职手册”,就是 Skill。
Skill 到底是什么?
一句话:Skill 是给 AI 写的”入职文档”。
新人入职第一天,你不会指望他什么都会。你会给他一本手册,里面写着:公司的业务规则是什么、SOP 流程怎么走、遇到什么问题该怎么处理。
Skill 干的就是这个事。
但这里要特别强调:**Skill 绝不是”更长的提示词”**,而是一种工程化的封装。它包含三个维度:
-
流程性(Process):强调”怎么做”而不是”是什么”,将复杂的业务 SOP 拆解为 Agent 可执行的步骤 -
可组合(Composable):像乐高积木,同一个”数据分析 Skill”可以被财务流程调用,也可以被销售预测流程调用 -
可执行(Executable):内部可以包含代码脚本,涉及排序、精确计算时,Agent 不再靠自然语言猜,而是直接跑脚本
换句话说:这是为 Agent 打包的一组可组合、可版本化、可执行的流程性知识。
Skill 和你熟悉的那些概念有什么区别?
|
|
|
|
|---|---|---|
| Prompt |
|
|
| Rules |
|
|
| RAG |
|
|
| MCP |
|
|
| Skill |
|
|
理清 MCP 和 Skill 的关系——**MCP 解决”能连什么”,Skill 解决”怎么做对”**。两者配合的公式:
❝
新业务能力 = MCP(工具链)+ Skill(流程链)
举个例子:做一份客户流失报告。MCP 负责从数据库拉数据,Skill 负责定义分析口径、套用报告模板、执行合规检查。
没有 Skill,你会踩什么坑?
当前企业应用 AI 有三大痛点,我结合自己的实践体会展开聊聊:
1. 口口相传:一条规则改五遍
想象一下:公司没有员工手册,所有规矩都靠老员工口头传达。现在退款政策改了,你得挨个找到 5 个部门的 5 个人,分别叮嘱一遍。有人记住了新版,有人还在用旧版,最后客户收到的答复自相矛盾。
这就是”一个需求造一个 Agent”模式的现状。每个 Agent 都有独立的 Prompt、工具链和权限,同一条业务规则要在多个地方重复编写。Agent 达到几十个时,知识碎片化严重。你不是在管理 AI,你是在玩一个大型传话游戏。
2. 名校毕业生:聪明但不懂行
你招了个名校毕业生,智商极高,逻辑推理一流。但让他做一份财务审计,他连公司的记账口径都不知道;让他处理退款,他不清楚哪些情况可以破例。他不是不聪明,而是没人教他”这里的规矩”。
大模型就是这样——通用推理能力极强,但在具体业务场景中,它缺少特定的口径、规则和业务”暗坑”,经常犯低级错误。在商业世界,最值钱的不是”灵感”,而是**”一致性执行”**。一个天才如果每次做审计的标准都不一样,那对企业来说就是灾难。
3. 越叮嘱越糊涂
既然新人不懂行,那就多交代几句?于是你开始往 System Prompt 里不断堆规则。结果就像一个焦虑的领导,每天给新人发一堆语音消息:第一条说”退款一律不超过 30 天”,第八十条又说”VIP 客户可以放宽到 90 天”。新人翻到第八十条的时候,早忘了第一条说的啥。
后果有三:Token 成本飙升、模型响应变慢、规则太多导致互相干扰,根本不知道哪句话导致了 AI 的误操作。Prompt 不是知识管理工具,它承担不了这个重量。这种”想到什么叮嘱什么”的模式,是一条必然的死胡同。
Skill 的技术架构
了解了 Skill 是什么,再来看看它在技术上是怎么跑的。
文件结构:从”一段话”变成”一套文件夹”
Skill 不再是对话框里的一段 Prompt,而是存储在硬盘上的标准化目录:
skill-name/
├── SKILL.md # 入口文件:技能名、描述、执行指南(SOP)
├── reference.md # 参考资料:业务手册、政策文档
├── examples.md # 使用示例
└── scripts/ # 可执行脚本
├── validate.py
└── helper.sh
核心是 SKILL.md,它用结构化的 Markdown 格式,定义了:
-
元数据:技能名称、描述、版本号 -
执行指南:Agent 调用此技能时必须遵循的步骤、边界条件、输入输出规范
这种文件化结构的意义在于:它让 AI 技能可以像代码库一样,进入 Git 工作流,实现版本控制、Code Review 和一键回滚。Skill 从此不再是对话框里的一段易失文本,而是可以被工程化管理的资产。
渐进式披露:怎么塞进去上万个 Skill?
这是 Skills 架构最精妙的工程设计——Progressive Disclosure(渐进式披露)。它解决了”规则越多,模型越傻”的 Token 膨胀问题。核心思路:不是一次性全部加载,而是分层按需加载。
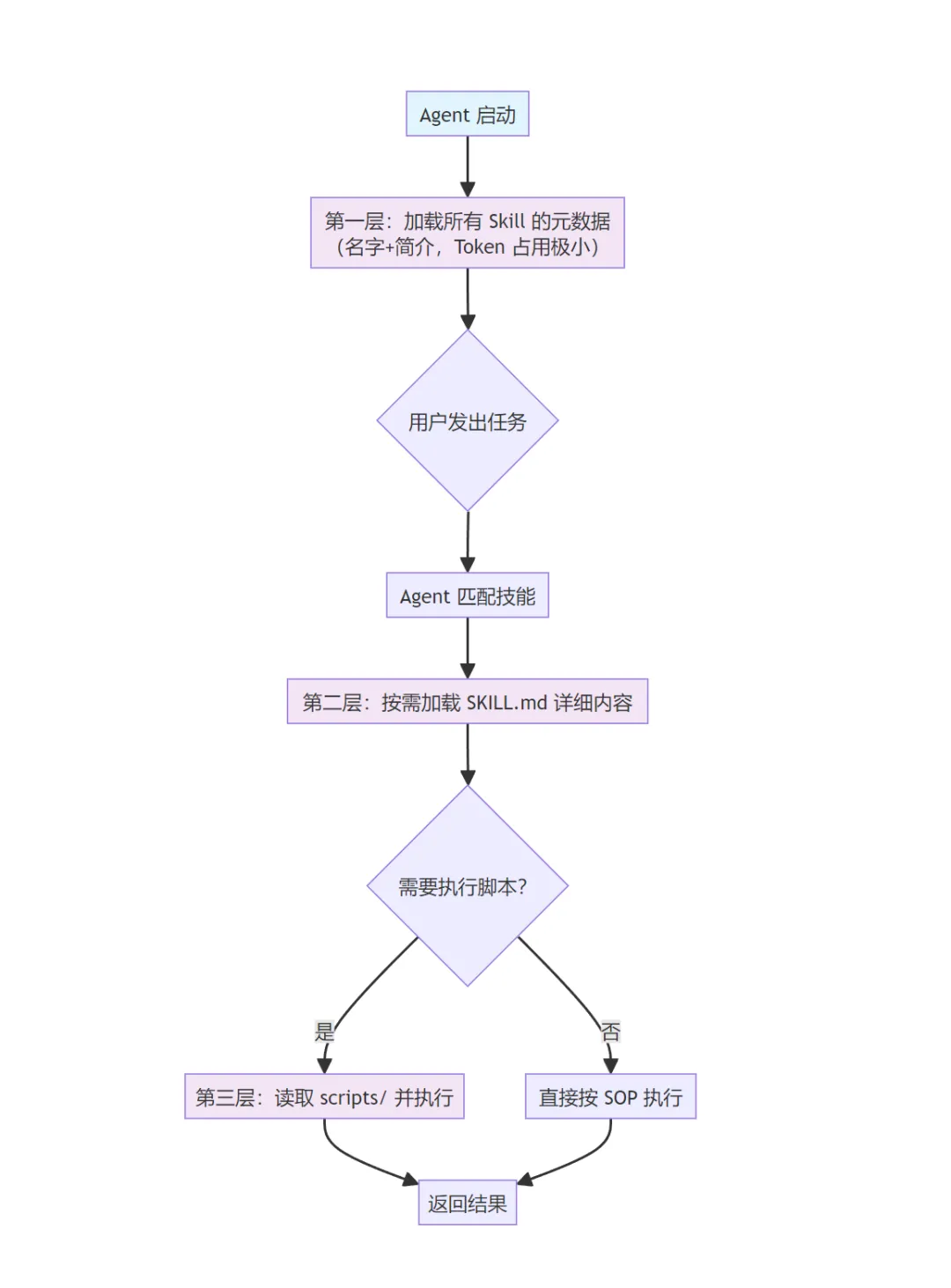
-
第一层:Agent 启动时,只加载所有技能的名字和简介。Token 占用极小,但 Agent 知道”我有这些技能”。 -
第二层:用户需求匹配到某个技能时,才加载该技能的 SKILL.md详细内容。 -
第三层:执行具体步骤时,才读取脚本和参考文档。
这套分层加载机制由 Agent 框架(如 Cursor)自动完成,你只需要按规范写好 SKILL.md 的元数据和内容,框架会负责在合适的时机加载合适的层级。结果就是:你的技能库可以从 10 个扩展到 10000 个,Agent 的上下文窗口永远不会被撑爆。
大脑与手的分工
这里有一个关键的架构公式:Agent(大脑)+ Runtime(手)= 确定性输出。这是将不稳定的自然语言推理与稳定的代码执行结合的关键。
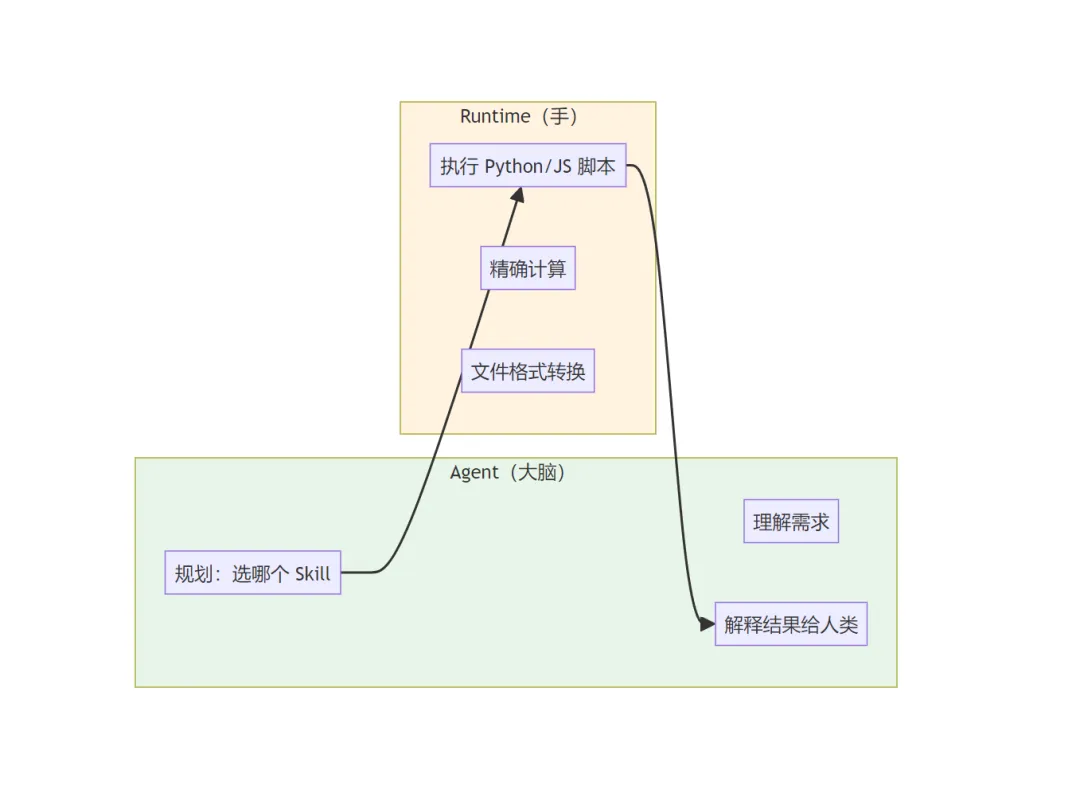
-
Agent(模型)负责:理解需求、选择 Skill、向人类解释结果 -
Runtime(执行环境)负责:跑脚本、做精确计算、处理文件
也就是说:涉及到计算、数据抓取等”重活”时,模型不再进行自然语言推理,而是直接调用 Runtime 执行脚本。这根治了 AI “算错数”和”幻觉”的老毛病——既降本又增效。
这套架构还带来三个工程优势:
-
可观测性:你能清晰看到 Agent 为什么选了 A 技能而没选 B,脚本在哪个环节报错 -
可调优性:出错不需要重写整个 Agent,只改那个特定 Skill 的 SKILL.md或脚本 -
权限治理:可以针对不同部门开放不同的 Skill 文件夹——财务部能加载”审计 Skill”,市场部不行
说白了:AI 的落地不再是”炼丹”和”调 Prompt”,而是回归到严谨的软件工程——模块化、解耦、按需加载、确定性执行。
实战:用 skill-creator 创建一个代码审查 Skill
说了这么多理论,来动手。
在 Cursor 中,有一个内置的 create-skill 技能,专门用来引导你创建 Skill。整个过程就像和一个资深同事讨论怎么写操作手册。
下面是一个完整的交互演示:创建一个”代码审查”Skill。
阶段一:需求收集(Discovery)
你只需要告诉 AI 你想干什么:
❝
你:帮我创建一个代码审查的 Skill,用于团队内部的 MR/PR 审查。
AI 会反过来问你几个关键问题(也可能通过结构化选择框):
❝
AI:
这个 Skill 是你个人使用( ~/.claude/skills/),还是团队共享(.claude/skills/)?你们代码审查时最关注哪些方面?(安全性、性能、可维护性……) 有没有现成的团队编码规范可以参考? 审查结果的输出格式有什么偏好?
你回答完,需求就明确了。
阶段二:设计(Design)
AI 根据你的回答,起草 Skill 的骨架:
❝
AI:我规划的目录结构如下:
code-review/
├── SKILL.md # 审查流程和规范
├── STANDARDS.md # 团队编码标准(详细版)
└── examples.md # 好/坏代码示例Skill 名称:
code-review
触发场景:当用户提交代码审查请求、打开 MR/PR、或明确说”帮我 review”时触发。你觉得这个结构可以吗?
阶段三:生成(Implementation)
确认后,AI 直接生成文件。核心的 SKILL.md 长这样:
---
name: code-review
description: Review code for quality, security, and maintainability
following team standards. Use when reviewing pull requests, examining
code changes, or when the user asks for a code review.
---
# 代码审查
## 审查流程
1. 阅读变更概览,理解改动意图
2. 按以下清单逐项检查
3. 输出审查报告
## 审查清单
- [ ] 逻辑正确性:边界条件、异常路径是否覆盖
- [ ] 安全性:SQL 注入、XSS、敏感信息泄露
- [ ] 可维护性:函数职责单一、命名清晰、注释充分
- [ ] 性能:是否有明显的 N+1 查询、内存泄漏风险
- [ ] 测试覆盖:改动是否有对应的单元测试
## 输出格式
- 🔴 **必须修改**:不改不能合并
- 🟡 **建议改进**:非阻塞性建议
- 🟢 **做得好**:值得肯定的地方
## 详细资料
- 团队编码标准详见 [STANDARDS.md](STANDARDS.md)
- 审查示例详见 [examples.md](examples.md)
阶段四:验证(Verification)
AI 会自动检查:
-
SKILL.md是否控制在 500 行以内 -
描述是否包含触发关键词 -
术语是否一致 -
文件引用是否只有一层深度
全部通过后,Skill 就可以用了。
几条编写原则
在使用 skill-creator 的过程中,有几条核心原则值得记住:
1. 简洁是王道
AI 本身就很聪明,不需要教它什么是”代码审查”。你只需要告诉它:你的团队的标准是什么、你的流程是什么。别写教科书,写手册。
2. 渐进式披露
核心指令放 SKILL.md,详细资料放在独立文件里。Agent 只有需要时才去读。
3. 自由度要匹配任务的脆弱程度
|
|
|
|
|---|---|---|
| 高
|
|
|
| 中
|
|
|
| 低
|
|
|
怎么用起来?
个人使用
把 Skill 放到 ~/.claude/skills/ 目录下,所有项目都能自动识别:
~/.claude/skills/
├── code-review/
│ └── SKILL.md
├── daily-summary/
│ └── SKILL.md
└── commit-message/
└── SKILL.md
当你在 Cursor 里说”帮我 review 这段代码”,Agent 会自动匹配到 code-review 这个 Skill,按照你定义的流程执行。比如你提交了一段数据库查询代码,AI 的输出会严格遵循你定义的清单和格式:
❝
审查报告
🔴 必须修改
getUserOrders()存在 N+1 查询问题:在循环内逐条查询订单详情,建议改为 JOIN 一次性查出缺少 SQL 参数化, userId直接拼接字符串,存在 SQL 注入风险🟡 建议改进
函数体超过 80 行,建议拆分为 fetchOrders()和formatResponse()两个函数缺少对 pageSize参数的上限校验,恶意请求可能导致内存溢出🟢 做得好
错误处理覆盖了数据库连接超时的场景 返回值类型定义清晰
没有 Skill 时,AI 的 review 是”自由发挥”,每次风格和关注点都不同;有了 Skill,每次审查都按同一套标准走,输出格式统一,团队可预期。
团队共享
把 Skill 放到项目的 .claude/skills/ 目录下,跟代码一起进 Git:
your-project/
├── .claude/
│ └── skills/
│ └── code-review/
│ ├── SKILL.md
│ └── STANDARDS.md
├── src/
└── ...
这样,团队中每个人 clone 项目后,都能用到同一套 Skill。退款规则改了?改一个文件,git push,全员同步。
不用再挨个去改 30 个 Agent 的 Prompt 了。
别找 Skill,要造 Skill
最后提一个容易踩的心态陷阱。
不像 MCP——有大量现成的社区插件可以直接安装,Skill 天然是”私有的”。它封装的是你的业务流程、你的团队标准、你的领域经验,这些东西不可能有通用版。
所以,不要把时间浪费在”去哪找一个现成的 Skill”上。正确的姿势是:当你发现自己在反复给 AI 解释同一套流程时,停下来想一想——这个事能不能流程化?能的话,就创建一个 Skill。
Skill 不是”下载来用”的,而是”沉淀出来”的。每一次你把口头经验写成 SKILL.md,就是在把一次性的对话变成可复用的资产。
再往前看一步
Skill 的意义不仅仅是”更好的 Prompt 管理”。
真正的差距不在模型,在手册
模型会越来越通用、越来越强。当所有人用的都是同一个大模型时,差距在哪里?
在于你沉淀了多少本高质量的”数字入职手册”。
那些藏在老员工脑子里的”口头经验”、分散在各个文档里的 SOP、每次都要重新解释一遍的业务规则——过去这些”隐性知识”散落在口头交流和混乱的 Prompt 副本里。一旦被封装成 Skill,它们就变成了可复用、可版本化、可分发的资产。
回到”入职手册”的比喻:一家公司新人上手快不快,不取决于招的人有多聪明,而取决于公司有没有一套好用的培训体系。AI 也一样——模型的智商是别人给的,但手册的质量是你自己攒的。
但也别神化它
Skill 不是万能的,有两个边界需要心里有数:
第一,手册再好,也得脑子够用。 Skill 只是”操作指南”,理解需求、处理异常、临场判断,依然靠模型本身的推理能力。如果底层模型 IQ 不够,给它再详细的手册也白搭。
第二,Skill 能”做事”,也就能”做错事”。 普通的 Prompt 说错了,最多是回答不准确;但 Skill 里如果包含可执行脚本,出错就可能是真金白银的损失——算错财务数据、误发一封邮件、删错一张表。所以 Skill 上线前要像代码一样做 Review,谁能用哪些 Skill 要有权限控制,执行记录要可追溯。一句话:把 Skill 当”插件”管,别当”文稿”管。
总结
回到开头 Sam Altman 说的那个困境——你以为在搞自动化,其实在带一群”初级员工”。
Anthropic 的 Skills 架构给出了一条出路:别再给每个活儿造一个人了,把业务逻辑从 Agent 身体里抽出来,变成可复用的资产。
Skill 的本质就是三件事:
-
把碎片化的经验,封装成标准化的知识包 -
把不稳定的自然语言推理,和稳定的代码执行结合 -
把”对人的管理”,降维成”对手册的管理”
现在的行动指南也很简单:
-
停止制造碎片化的 Agent -
梳理内部 SOP,写成标准的 SKILL.md -
用 Git 管理,建立团队级的技能底座
最后,三句话收尾:
❝
不要追求 Agent 的数量,要追求技能资产的密度。
Skills 很可能是 AI 的 App Store 时刻,因为它打开了供给侧。
当模型越来越通用,知识组织方式就是新的核心竞争力。
参考
-
https://www.youtube.com/watch?v=xeoWgfkxADI&t=19s
