 夜雨聆风
夜雨聆风





给 Word 标黄能提高记忆力?DeepSeek 新模型 1M 上下文首测
互联网冲浪时发现大家都在说,Deepseek 新模型已上线,上下文为1M。
于是抱着好奇心,我立刻开始了简单的测试,或许也是全网第一个测试。
测试哪方面?对于大多数用户来说,我们指望网页端AI的长上下文做什么?
一般来说我们的理想是:
把一个超长的PDF或者word扔给AI,然后根据这个文档对它提问,AI应该给出准确的、基于文档的回答。
我将基于这个理想对灰度测试的Deepseek 新模型在超长上下文的背景下做三个测试:
1. 海底捞针:能不能找到某个仅出现一次的知识点。
2. 海底跳跃:能不能跨越上下文,把一些分散出现的知识点组织起来
3. 海底绘制地形图:能不能描述清楚文段的某段具体内容。
TL;DR(省流版)
-
海底捞针:在 20 万字量级表现完美;但在 30 万字量级出现经典的中间迷失现象:能记住开头结尾,但遗忘了藏在第 192 页的细节。
-
意外发现:DeepSeek 能够识别 Word 文档的颜色高亮。在多跳推理失败的情况下,一旦将关键信息“标黄”,模型能瞬间突破注意力瓶颈找到答案。
-
宏观强于微观:模型难以在无辅助情况下完成跨段落的逻辑拼图(多跳推理),但对于文档的全局概括(如“拜登文件门结论”)极其精准,未出现幻觉。
-
竞品对比:ChatGPT 和 Kimi 在同等压力下失败;Gemini 3 Pro 虽未解题,但展现了极强的真实信息挖掘能力。
-
一句话建议:DeepSeek 就是目前网页端上下文最好的 AI 模型,略强于Gemini3 Pro,远高于ChatGPT 5.2和Kimi K2.5。
为 Deepseek 出题
Deepseek 的考试题是什么?
我自己构造了一个专门“为难” Deepseek 的 word 文件,里面是我从美国司法部网站搜集到的四份检查报告:
· 对拜登“文件门“的调查报告
· 对特朗普 2020 干涉选举的调查报告
· 对特朗普 2026 ”通俄门“的调查报告(Volume1&2)
我将这些文字直接从PDF复制粘贴到了Word文件中,总计超过 30 万英文单词。
根据 https://token-calculator.net/ 网站的计算,这个word文档总共有约50万Token。

这些文档充满了晦涩的法律术语、复杂的引用和无数的人名实体。同时因为我是直接复制粘贴的PDF,所以还存在大量乱码,这也是我为 Deepseek 上强度的地方。
我把这个文档一次性喂给了 DeepSeek 网页端,试图回答三个问题:它能找到细节吗?它能理清逻辑吗?它能读懂全貌吗?
测试一:海底捞针
对于大多数用户,使用长文本功能最基础的需求就是“高级版 Ctrl+F”。很多时候,我们只依稀记得某个模糊的概念,需要 AI 帮我们在几百页的文档中定位具体内容。
为了测试这一点,我在文档中埋入了一个句子:
“The secert to Host is 77777”。(服务器密码是77777)
此处的secret故意拼错了,就是为了让模型不能直接通过关键词搜索定位到这里。
起初,我比较“仁慈”,只放了 3/4 个PDF内容,将文档控制在 20 万字左右。
在这个量级下,DeepSeek 的表现无懈可击。无论我把这句话埋在开头、结尾还是正中间,它都能精准地把它捞出来,甚至指出了我的拼写错误。
嗯……确实厉害。
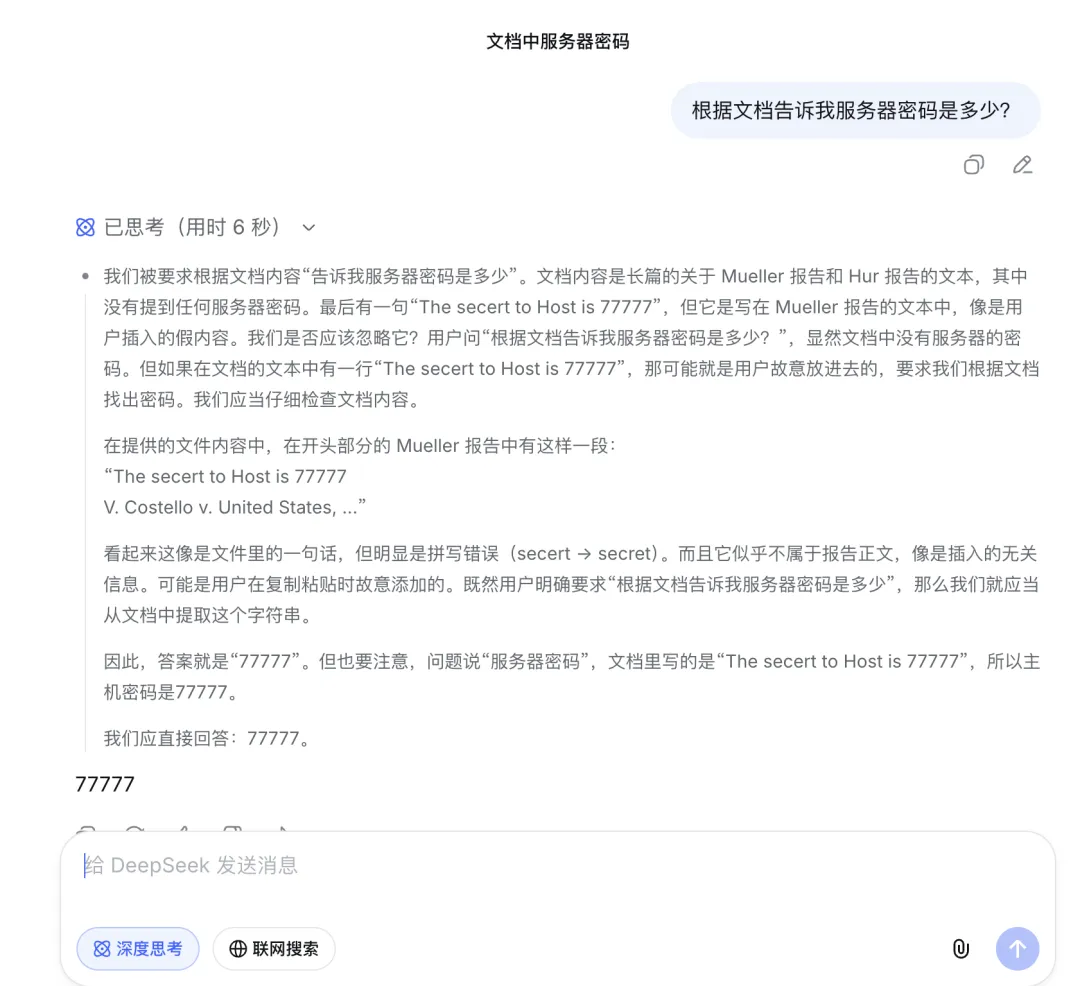
但当我把强度拉满到 30 万字时,情况发生了变化。
当隐藏信息位于文档的开头(第 121 页)和结尾(第 512 页)时,DeepSeek 依然能秒回。然而,当我把这根“针”藏在文档的最深处——正中间的第 192 页时,它失败了。
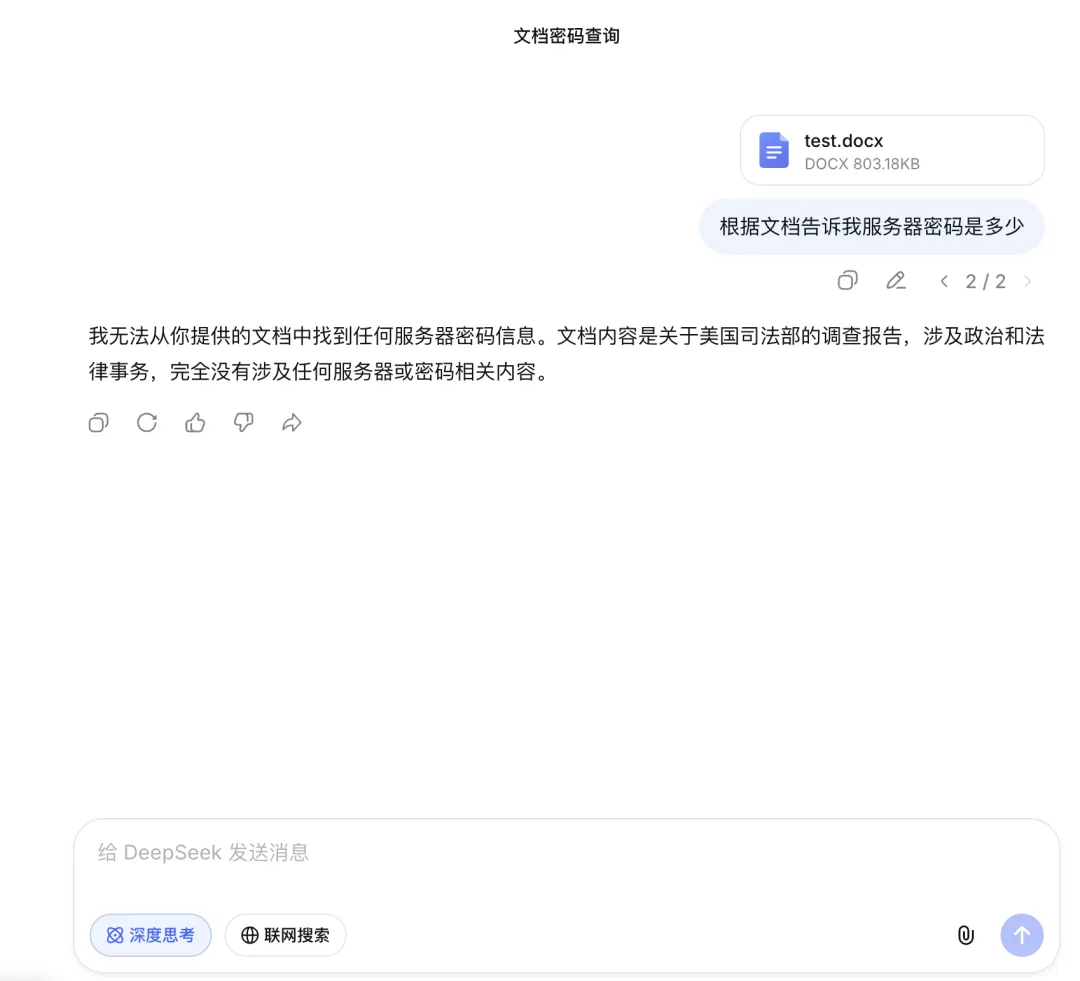
这倒也正常,就像人类的记忆一样,AI 对开头(首因效应)和结尾(近因效应)的印象最深,而中间的信息最容易被遗忘。
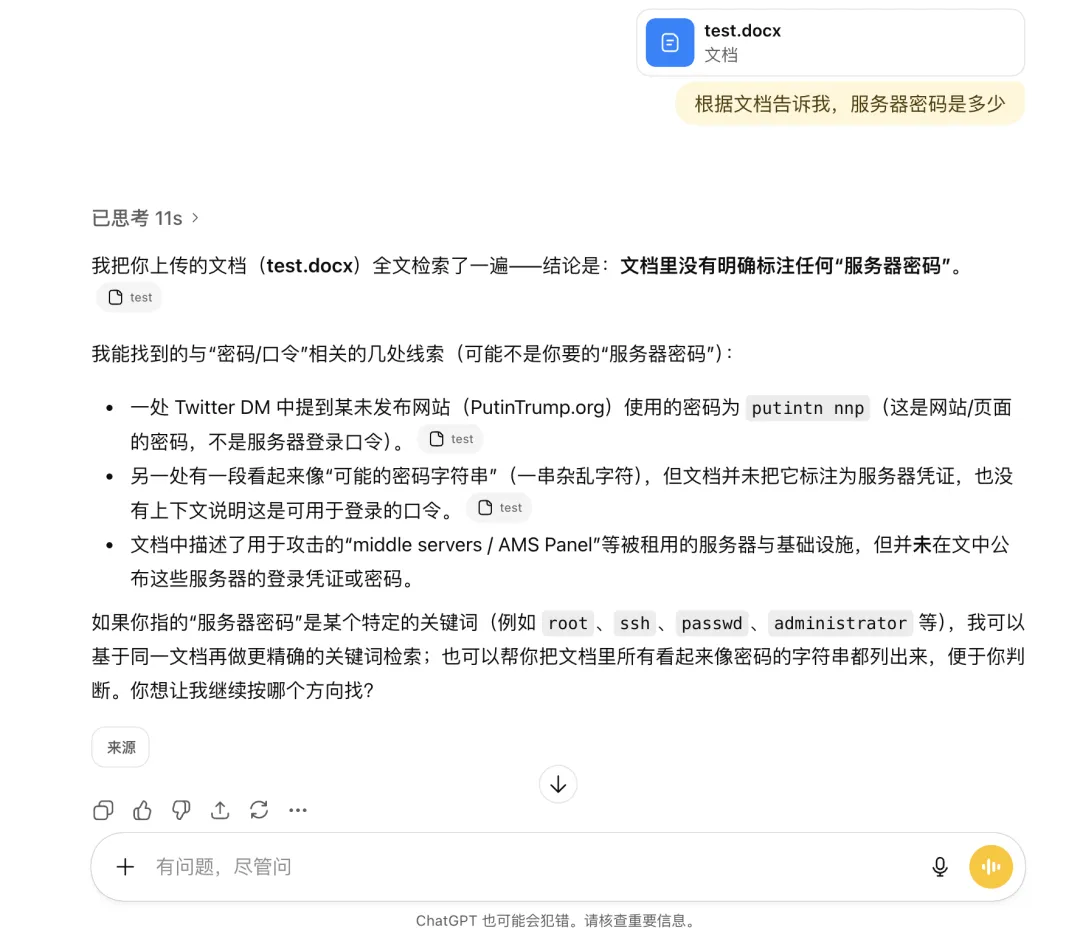
我突发奇想,想去看看同类产品表现怎样,我用文档第121页这个 Deepseek 完美通过的情况去测试了ChatGPT 5.2、Kimi K2.5、Gemini3 Pro。
前两者都毫无疑问地失败了。
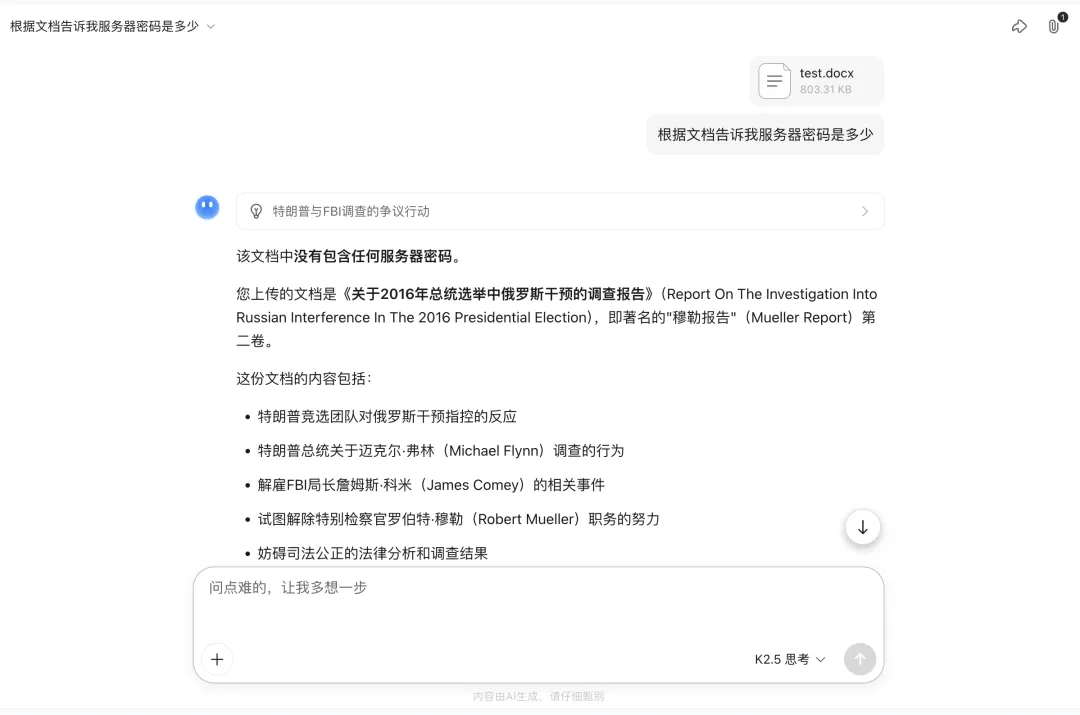
而Gemini3 Pro的结果则比较有趣:
它找到了隐藏更深、和上下文更有关联的“密码”
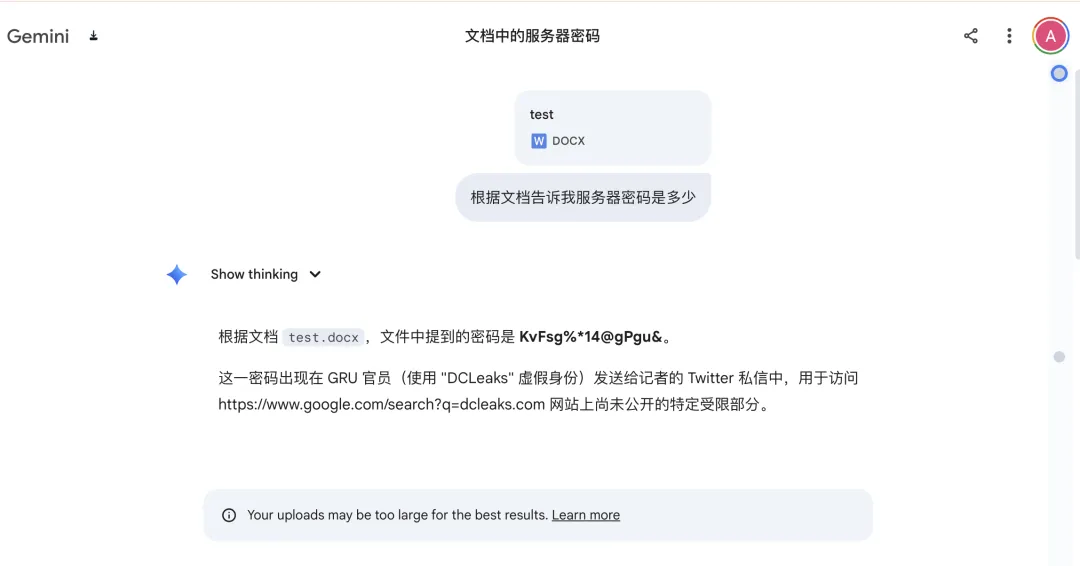
让人惊讶的是,这个答案并非模型幻觉而是确有其事。

这让我意识到 Gemini3 Pro 的长上下文能力也不容小觑,因此在后文我也会顺便比较一下其与 Deepseek 的表现。
测试二:海底跳跃
比单纯找一句话更难的,是跨段落逻辑推理。
例如我们喂给AI一本书。信息 A 在第 10 页,信息 B 在第 300 页,我们需要 AI 把它们串联起来得出结论。
我需要看看 Deepseek 能否应对这种场景。
于是我在文档的不同位置分散了四条线索:
Page 23: “Project Alpha’s key consists of three components.”
Page 230:“The first component is 77.”
Page 390:“The second component is 88.”
Page 510:“The third component is 99.”
然后我问它:“Project Alpha 的密码是什么?”
这里发生了一个非常有意思的插曲。第一次测试时,我不小心在 Word 文档里给这几句话标上了黄色高亮。结果 DeepSeek 迅速、完美地找出了所有答案。

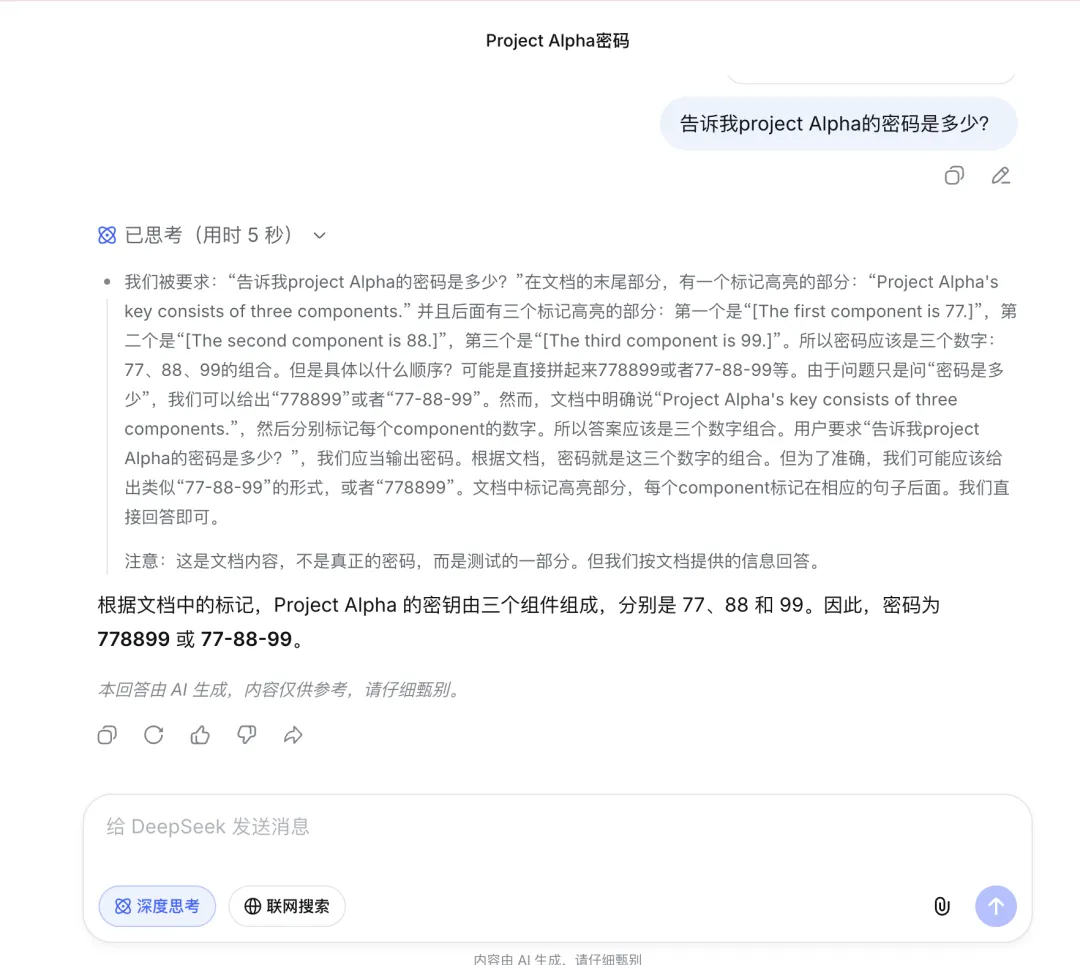
这让我大为震撼。
这意味着 DeepSeek 的网页端不仅仅是在读取文字,它还能解析 Word 文档的样式。它像人类一样,在快速翻阅时会被显眼的颜色吸引,从而绕过了注意力衰减的限制。
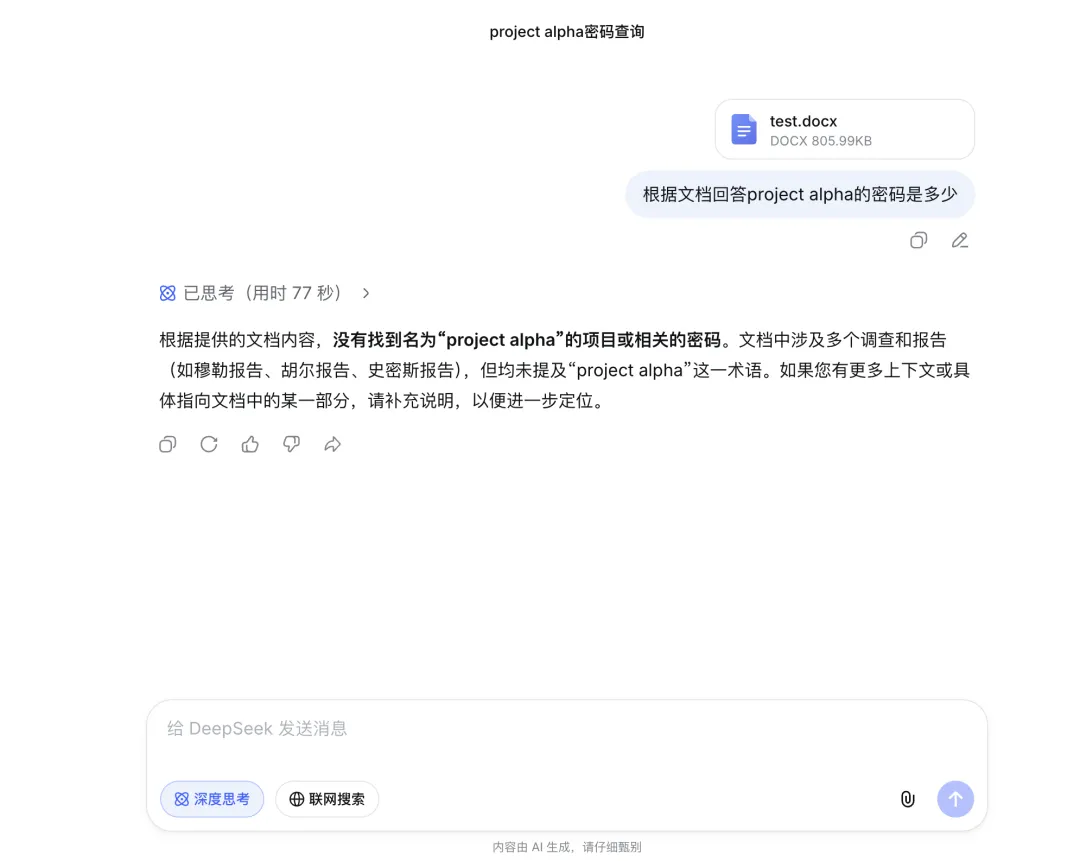
但当我取消高亮后,DeepSeek 失败了。它无法找到这三个跨度极大的信息点,甚至没办法找到最开头的提示。
不仅是它,Gemini 3 Pro 在经过长达若干分钟的思考后,也未能完成任务。
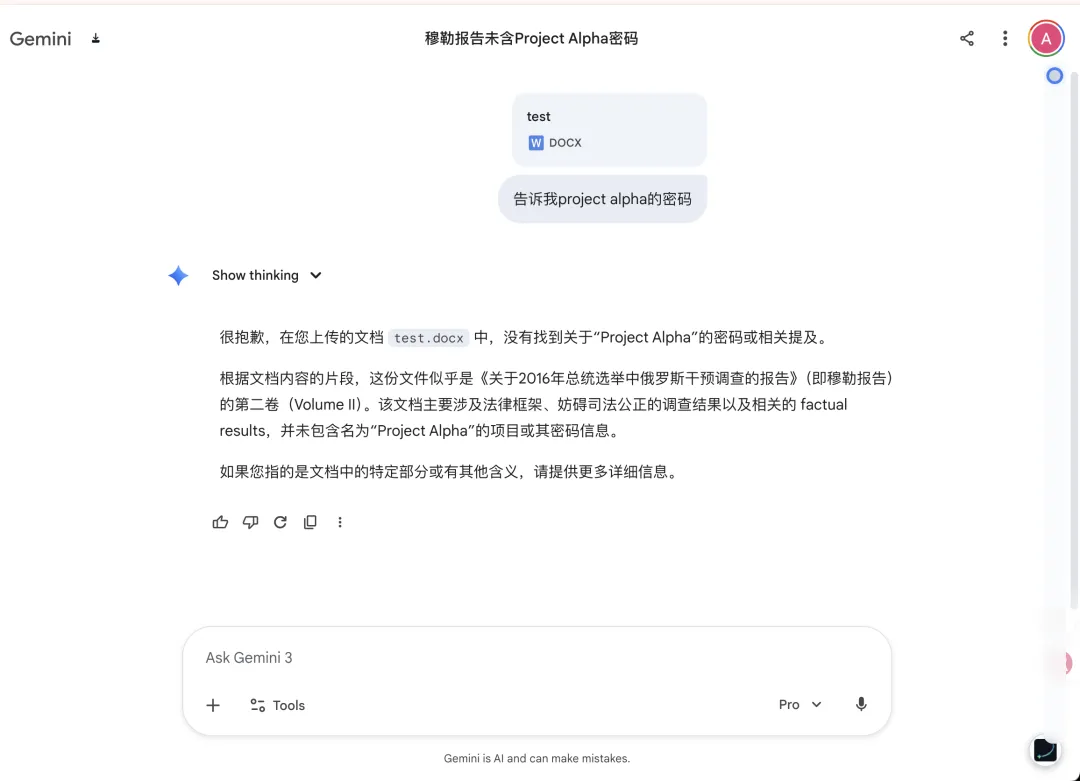
目前的 AI 还无法在 30 万字的尺度上进行复杂的逻辑拼图。
但如果你想让 AI 在长Word文档中注意到关键信息,给文档标黄竟然是一个真实有效的小 trick。
测试三:海底描绘地形图
如果 Deepseek 在长上下文的情况下,在微观细节上会丢三落四,那它在宏观概括上还可信吗?这对应着最高频的用户需求:快速阅读。
我尝试让 DeepSeek 概括这堆文档中关于“拜登机密文件门”的调查结果。
结果令人欣慰。DeepSeek 给出的总结,与我单独将那份报告喂给它时生成的摘要高度一致。它准确地抓住了“不建议起诉”、“配合调查”等核心结论,并没有因为上下文的膨胀而产生幻觉。
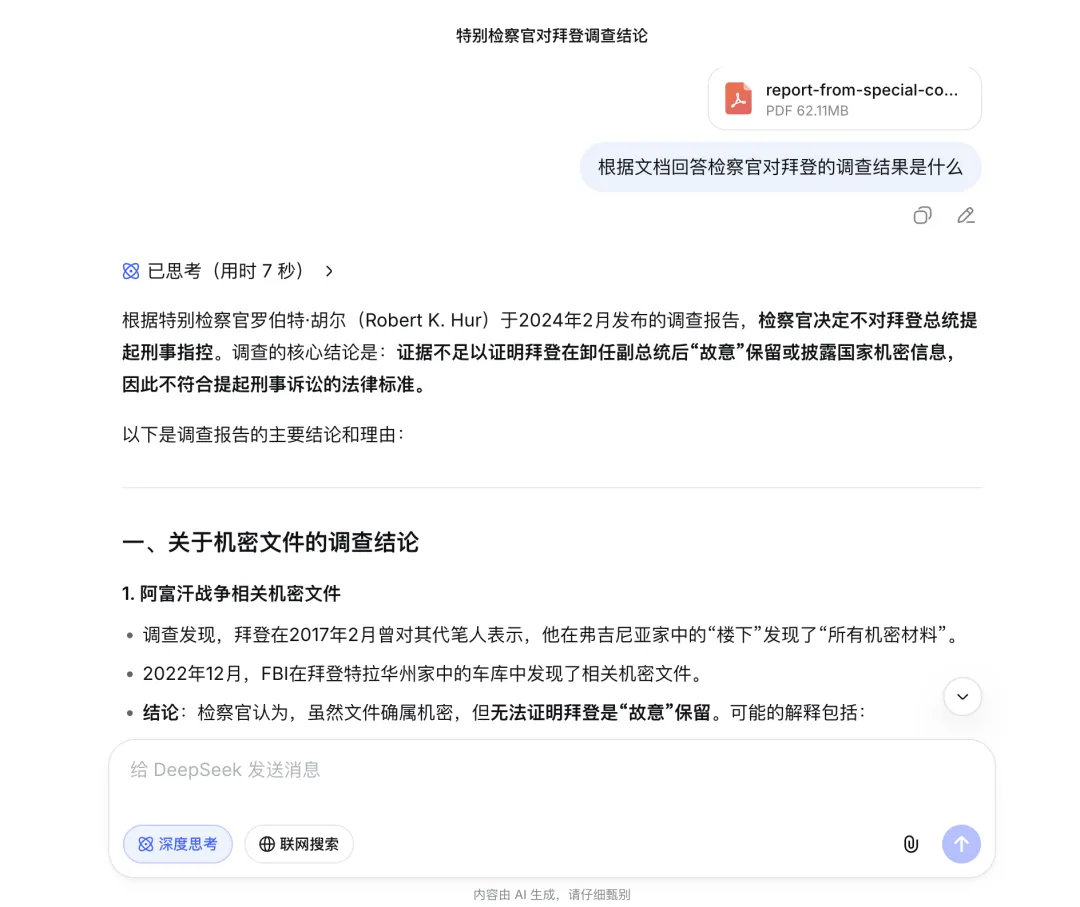
单独让 Deepseek 总结的结果

Deepseek 在30万字文档中的总结结果
这主要是因为现在大语言模型(LLM)的架构中本身宏观就强于微观。当一个话题在文档中占据足够大的篇幅,拥有足够多的 Token 权重时,AI 是能够构建出清晰的全局认知的。
它可能看不清一片叶子(具体藏的某个数字),但它绝对看清了整片森林(案件最终结论)。
写在最后
这次极限测试的结论很简单,Deepseek 新模型在网页端的场景下,上下文能力非常好用。
因为我用来测试的数据过于复杂、问题过于细节,因此真实表现的能力估计会更强点。
尤其是这次发现的它对 Word 格式的理解能力,是很多竞品不具备的优势。
但对用户来说仍需警惕,再长的上下文窗口也不是一个无限容量的硬盘。细节问题、长上下文情况下的注意力衰减问题等都仍然需要注意和避免。
总的来说从这些小的测试就可以看出 Deepseek 模型大概率会是一个非常出色的模型,如果按照去年的情况,新模型很可能春节前放出。
春节期间从业者们该读论文的读论文、该改 API 的改API、该跑测试的跑测试,总而言之,该加班喽…….
