 夜雨聆风
夜雨聆风





Soul App 又放大招!把 42000 小时数据喂出的“歌神” SoulX-Singer 开源了!
语音合成这两年爆发式增长。
TTS 模型越来越强,音乐生成模型也是层出不穷,除了闭源的 Suno、Udio 等一骑绝尘外。
开源领域也不乏强大优秀的音乐模型,比如前两周的 HeartMuLa,又或是前两天刚开源的 ACE-Step1.5,它们在某些场景下也不弱于闭源音乐生成模型。
但今天给大家介绍的都不是上面的模型,而且一个真正稳定、可控、工业级可用的开源歌声合成模型。
它就是国内社交巨头 Soul APP 联合 AIC、天津大学、西北工业大学开源的 SoulX-Singer。

这是一个喂了 42000 小时高质量歌声数据的庞然大物。它主打 “零样本歌声合成(SVS)”,而且同时支持基于 旋律控制(F0 音高曲线) 和 乐谱控制(MIDI 音符) 的两种歌声合成控制方式。
选取了一个官方演示:
它不是实验室演示级模型,而是:
-
• 42,000+ 小时训练数据 -
• 支持零样本歌声克隆 -
• 多语言(普通话 / 英语 / 粤语) -
• MIDI + Melody 双控制 -
• 本地运行,100% 开源 -
• 面向工业真实场景
这一次,SVS 真正进入「可用阶段」。
两大核心亮点
1、4.2 万小时数据打底,零样本能力封神
零样本歌声合成的核心就是数据,SoulX-Singer 直接甩出42000 小时高质量歌声数据,覆盖普通话、英语、粤语三种语言,还有上百种音色、几十种演唱风格,从流行到古风、从抒情到摇滚都能 hold 住。
42,000+ 小时。 这是一个什么概念?如果一个人不吃不喝连续唱歌,要唱整整 5 年。
它直接解决了零样本(Zero-shot)合成中最大的痛点——泛化能力。
即使是它从未见过的歌手音色,或者极其复杂的音乐条件,它也能稳得住。它不再是模仿,而是真正学会了“如何像人一样发声”。
2、双重控制范式,满足不同需求
SoulX-Singer 的技术实力也完全配得上工业级定位,它提供了两种指挥 AI 唱歌的方式:
-
• Music Score (MIDI) 驱动:这是专业音乐人最想要的功能。你可以直接导入一个 MIDI 文件(乐谱)和歌词,模型会严格按照你设定的音高、时长、节奏来演唱。 -
• Melody (旋律) 驱动:这个模式支持“哼唱转歌唱”或“风格迁移”。你提供一段参考音频(比如你跑调的哼唱,或者原唱),模型会提取其中的旋律和演技巧,然后用目标音色重新演绎。(也是目前比较火的 AI 翻唱中的一种形式)
3、多语言与跨语言能力
支持普通话、英语、粤语。最强的是跨语言风格迁移:你可以给它一段周杰伦的中文素材,然后让它用标准的伦敦音唱 Adele 的歌,或者让 Taylor Swift 的声音唱粤语歌。
技术原理
扒开技术文档,你会发现 SoulX-Singer 在架构设计上非常“鸡贼”(褒义)。它没有沿用老旧的扩散模型,而是采用了当下最先进的 Flow Matching(流匹配) 范式。
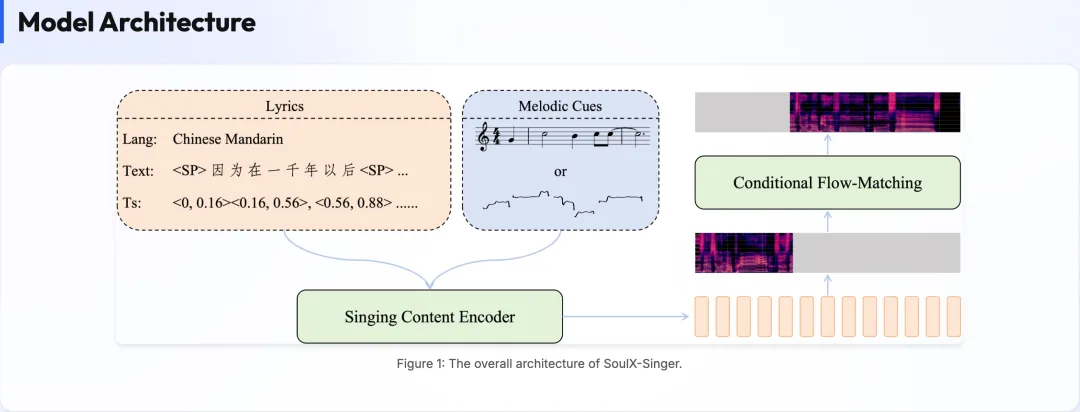
为了解决“歌词-旋律-发声”的强耦合问题,它引入了三个关键设计:
-
• Audio Infilling(音频补全)建模:它把歌声合成看作是一种填空题。给它上下文,它补全中间的波形。这种生成方式天然具备极高的连贯性。 -
• 显式对齐机制:它不让模型去“猜”歌词对应哪个音,而是强制建立歌词、MIDI 音符与声学特征的对齐关系。这就好比给 AI 戴上了“节拍器”,想跑调都难。 -
• 两阶段训练策略(The Two-Stage Magic): -
• 阶段一(打基础):用 2-16 秒的短切片训练,让模型学会看乐谱,减少对上下文的依赖,提高鲁棒性。 -
• 阶段二(练气息):用 30-90 秒的长片段训练,让模型学会“长气口”。这使得它在演唱长段落时,气息连贯,不会出现“断气”的机械感。
评测表现
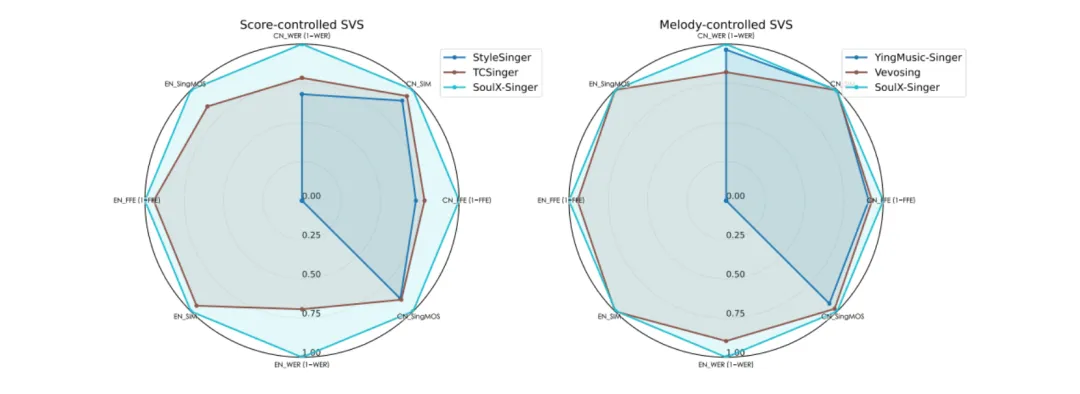
评测数据集:
-
• GMO-SVS(整合主流开源数据) -
• SoulX-Singer-Eval(严格零样本测试)
结果:
-
• 语义清晰度领先 -
• 歌手相似度领先 -
• 基频一致性更高 -
• 主观听感明显更好
在多个维度上超过此前开源方案。
快速使用
怕部署麻烦?SoulX-Singer 早就为你想好了:
在线 Demo 直接玩
https://huggingface.co/spaces/Soul-AILab/SoulX-Singer
不用下载任何东西,上传音频、输入歌词就能生成歌声,还能直接用内置 MIDI 编辑器调旋律(需魔法)
本地部署也简单
克隆 GitHub 仓库
git clone https://github.com/Soul-AILab/SoulX-Singer.git
cd SoulX-Singer配置 Python3.10 环境,安装依赖
conda create -n soulxsinger -y python=3.10
conda activate soulxsinger
pip install -r requirements.txt下载预训练模型
pip install -U huggingface_hub
# Download the SoulX-Singer SVS model
hf download Soul-AILab/SoulX-Singer --local-dir pretrained_models/SoulX-Singer
# Download models required for preprocessing
hf download Soul-AILab/SoulX-Singer-Preprocess --local-dir pretrained_models/SoulX-Singer-Preprocess运行推理
bash example/infer.sh可以使用以下命令启动交互式界面:
python webui.py写在最后
过去几年,音乐生成在热闹,TTS 在爆发,但 SVS 一直缺一个真正稳定、开源、可控、可用的模型。
SoulX-Singer 的开源,很可能是:开源歌声合成进入工业级阶段的里程碑。
如果你关注音乐创作、虚拟歌手、AI 内容生成,这个项目非常值得深入研究,也可以顺便为这个国产模型点点 Star。
GitHub: https://github.com/Soul-AILab/SoulX-Singer
项目地址:https://soul-ailab.github.io/soulx-singer/

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️

