夜雨聆风
夜雨聆风





彻底告别云端!LocalGPT:让机密文档在本地与AI对话,数据永不泄露
点击上方“小妖同学学AI”,选择“星标”公众号
超级无敌干货,第一时间送达!!!
LocalGPT 完全解析:构建100%私有的企业级文档问答系统
项目介绍:为什么你需要一个本地RAG?
当企业将内部文档上传至云端AI服务时,数据泄露风险始终如影随形。LocalGPT 正是为解决这一痛点而生——它是一个完全离线、端到端私有的文档智能平台,让你在自己的计算机上就能与PDF、Word、Markdown等文件进行自然语言对话。
该项目由 PromtEngineer 发起,GitHub 上已斩获 22.2k Stars,是目前最活跃的本地RAG解决方案之一。与同类工具不同,LocalGPT 并非简单的检索-生成流水线,而是集成了混合搜索、查询分解、答案验证、上下文丰富等企业级功能,且纯Python核心,无重型框架依赖,轻量到甚至可在树莓派上运行。
核心承诺:您的文档永不离开设备,AI模型全部本地加载,100%隐私保障。
核心功能:不仅是聊天,更是智能文档分析平台
极致隐私与离线运行
所有处理均在本地完成,无需联网(除首次下载模型外) 支持 Ollama 托管的开源LLM(如 Qwen3、Llama3),也可直接使用 HuggingFace 模型
多格式文档处理
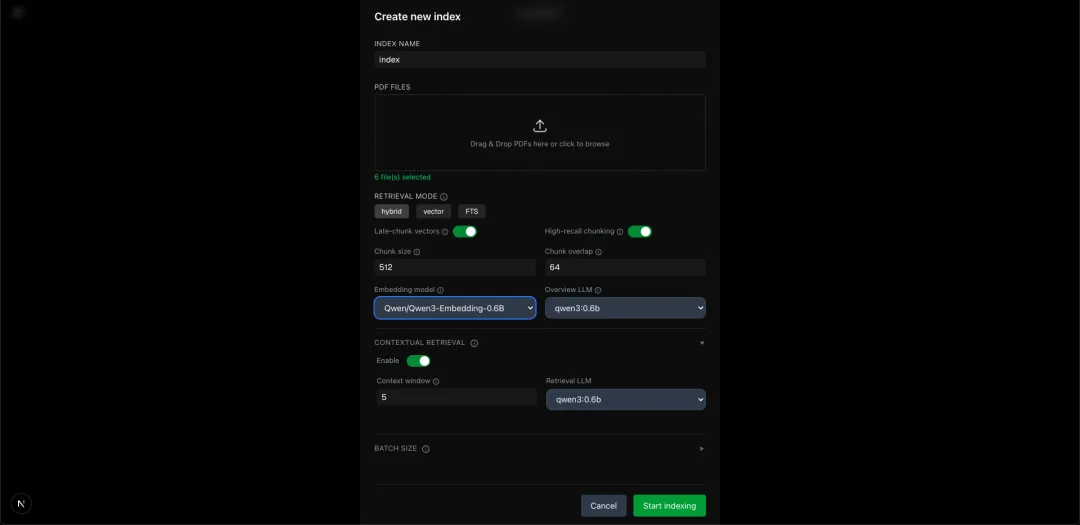
PDF、DOCX、TXT、Markdown、HTML(通过 Docling 解析) 批量索引:同时处理数百份文档,支持断点续传 上下文丰富:AI自动为每段文本生成摘要性描述,提升检索精度(灵感来自 Anthropic 的 Contextual Retrieval) 智能检索与生成
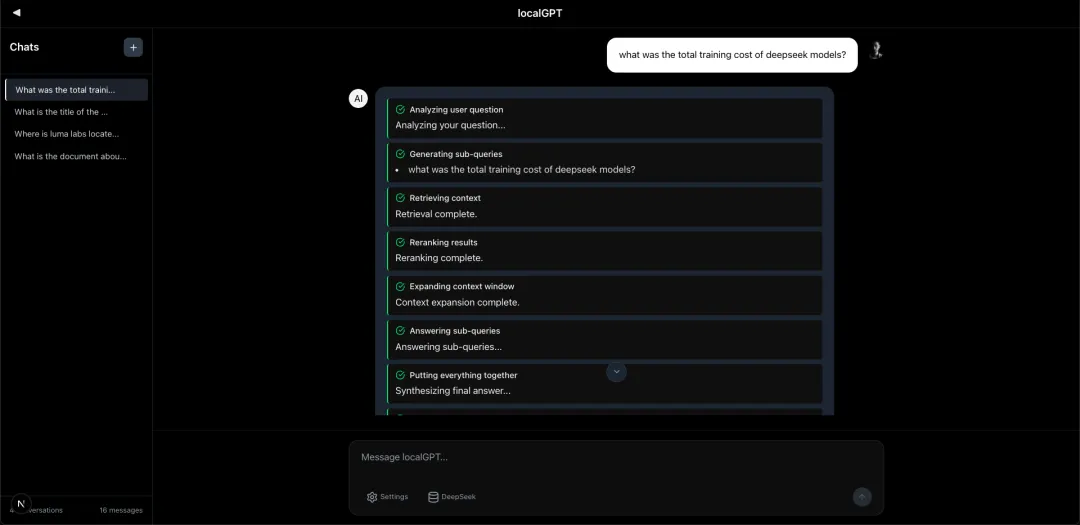
混合搜索:向量(dense)+ 关键词(BM25)加权融合,默认权重 0.7:0.3 迟分块(Late Chunking):先嵌入长文本再切块,保留全局语义 AI重排序:使用 ColBERT 或 BGE 模型对召回结果二次筛选 查询分解:将复杂问题拆分为多个子问题,综合回答 答案验证:独立模型对最终答案进行事实性核对 开发者友好
RESTful API:完整的会话、索引、文档管理接口 实时进度反馈:索引构建、聊天流式输出均有事件推送 多硬件支持:CUDA、CPU、HPU(Intel Gaudi)、MPS(Apple Silicon) 现代化Web UI
基于 Next.js 的响应式界面 多会话管理、索引库管理、实时流式响应 源文档引用预览,点击直接定位原文段落
使用方法:5分钟启动你的私有文档问答
环境准备
# 克隆 localgpt-v2 分支(当前稳定版)git clone -b localgpt-v2 https://github.com/PromtEngineer/localGPT.gitcd localGPT# 安装 Ollama 并下载推荐模型curl -fsSL https://ollama.ai/install.sh | shollama pull qwen3:0.6b # 轻量路由模型ollama pull qwen3:8b # 主生成模型ollama serve # 启动 Ollama 服务(新开终端)方式一:Docker 一键部署(推荐生产)
./start-docker.sh# 访问 http://localhost:3000方式二:直接开发模式(推荐自定义)
pip install -r requirements.txtnpm installpython run_system.py # 自动启动后端、RAG API 和前端open http://localhost:3000代码示例:通过API与文档对话
import requests# 1. 创建索引并上传文档index_res = requests.post("http://localhost:8000/indexes", json={"name": "财务报告", "description": "2025年报"})index_id = index_res.json()["id"]with open("annual_report.pdf", "rb") as f: requests.post(f"http://localhost:8000/indexes/{index_id}/upload", files={"files": f})# 2. 构建索引(异步处理)requests.post(f"http://localhost:8000/indexes/{index_id}/build", json={"config_mode": "default"})# 3. 创建会话并关联索引session = requests.post("http://localhost:8000/sessions", json={"title": "年报分析"}).json()session_id = session["session_id"]requests.post(f"http://localhost:8000/sessions/{session_id}/indexes/{index_id}")# 4. 提问response = requests.post(f"http://localhost:8000/sessions/{session_id}/chat", json={"query": "今年研发投入增长多少?","search_type": "hybrid"})print(response.json()["response"])# 输出: 根据年报第23页,研发投入同比增长18.7%,主要由于AI实验室扩建。优势对比:LocalGPT vs. 其他本地RAG方案
维度 LocalGPT privateGPT AnythingLLM 商业云端服务 (OpenAI) 数据隐私 ✅ 完全离线,零外传 ✅ 完全离线 ✅ 本地运行可选 ❌ 数据上传至厂商服务器 检索策略 混合搜索 + AI重排序 + 查询分解 仅向量 + 相似度 向量/关键词可切换 仅向量检索 答案验证 ✅ 独立模型二次校验 ❌ ❌ ❌ 迟分块 ✅ 支持 ❌ ❌ ❌ 多模态支持 即将支持 ColPali(图像/图表) ❌ ❌ ✅ GPT-4V 硬件兼容 CUDA/CPU/HPU/MPS CUDA/CPU/MPS CUDA/CPU 仅云端 配置复杂度 中等(模块化,可裁剪) 低 低 无 开源协议 MIT MIT MIT 闭源,按token收费 结论:LocalGPT 在检索精度和企业级功能上明显领先同类开源项目,尤其适合对事实准确性要求高的金融、法律、医疗场景。
总结:本地私域知识库的最佳选择
LocalGPT 绝非又一个RAG玩具。它通过混合搜索、迟分块、查询分解、答案验证等一系列创新,将开源Tiny模型的能力发挥到极致,在MTEB等基准上甚至能媲美某些云端商用服务。
更难得的是,它的模块化设计允许你只启用需要的组件——如果只需要简单的向量检索,关掉重排序和验证即可;如果需要最高精度,所有增强功能一键开启。这种灵活性使其既能跑在树莓派上做概念验证,也能部署在多卡服务器上处理百万级文档。
如果你还在犹豫将企业知识库接入AI的隐私成本,现在就用LocalGPT在自己的电脑上搭建第一个私有问答系统吧。
项目地址:https://github.com/PromtEngineer/localGPT