 夜雨聆风
夜雨聆风





PDF:躺了三十年,该起来干活了
PDF:躺了三十年,该起来干活了
AI 都能写代码、画图、剪视频了。但你把一份 PDF 变成 PPT,还是得截图粘贴两小时。
全球 3 万亿份 PDF 在流通,每一份都是一块数字混凝土——能看,不能用。
不是工具不行,是这个格式从第一天起就不是给”用”设计的。它是给打印机设计的。
3 万亿份”数字混凝土”
全球有 3 万亿份 PDF 在流通。很多人每天见 PDF 的次数比见家人还多。
但这些 PDF 是什么?数字世界的”混凝土”——一旦生成,就固化了。能看,但改不了;能读,但用不了;能存,但活不了。
全球有 3 万亿份 PDF 在流通。很多人每天见 PDF 的次数比见家人还多。但这些 PDF 是什么?是数字世界的”混凝土”——一旦生成,就固化了。
回头看文档的进化史,其实就三步:
1.0 数字泥土(Word,80 年代)——你能随意捏,但结构乱、版本混、隐私还容易泄露。
2.0 数字混凝土(PDF,90 年代)——Adobe 为了让文件在任何打印机上输出一致,把文字变成了死坐标。在打印时代是革命,在 AI 时代是灾难。
3.0 数字流(Google Docs,2006)——文档上了云,能协作了,但最终输出呢?还是导成 PDF 签字发出去。
所以现状很分裂:用 Word 排版,最后导成 PDF。一旦变成 PDF 发出去,你就失去了对它的控制。版本混乱,权限不明,数据变成黑盒。
PDF 的本质问题不是”格式转换难”,而是它对 AI 不友好。
过去文档是给人看的,现在文档是给 AI 用的。AI时代的核心生产资料是结构化数据,而 PDF是结构化的反面——它把文字变成死坐标、死像素,是给打印机设计的产物。
AI 读 PDF本质上是在做逆向工程:用 OCR扫像素猜文字,猜完文字猜结构,猜完结构猜语义,每一层都在丢信息。一份双栏论文,AI分不清左栏右栏;一张复杂表格,AI 搞不清行列关系;一个嵌套列表,AI 读成一坨纯文本。
3万亿份文档躺在那,对人类是知识,对 AI 是噪声。不是 AI 不行,是 PDF没给它留路。底层格式不变,上层工具再强也是在混凝土上种花。
反过来想,谁能把这 3 万亿份混凝土重新变成结构化数据,谁就掌握了 AI时代的石油精炼厂。每一份论文、每一本书、每一套行业标准,背后都是几十年沉淀的专业知识。
这些知识不缺,缺的是 AI 能读懂的格式。大模型的能力天花板,很大程度上不是算法问题,是喂养问题——你给它混凝土,它只能输出混凝土。把 PDF 变成 AI可读、可理解、可调用的结构化数据,不是一个工具功能,是整个知识经济的基础设施升级。
让 PDF”活”的三个层次
我们做了一系列工具,叫 PDF2x。
核心就是让 PDF 从”存档”变成”执行”,分三层:
第一,可编辑
PDF2PPT、PDF2Word,不是简单的格式转换。
传统工具用规则引擎,遇到双栏论文、复杂表格就翻车。我们让 AI 像人一样”看懂”版式,而不是靠坐标猜。
格式保留率 99%,不是吹的。图片、表格、公式,该在哪就在哪。
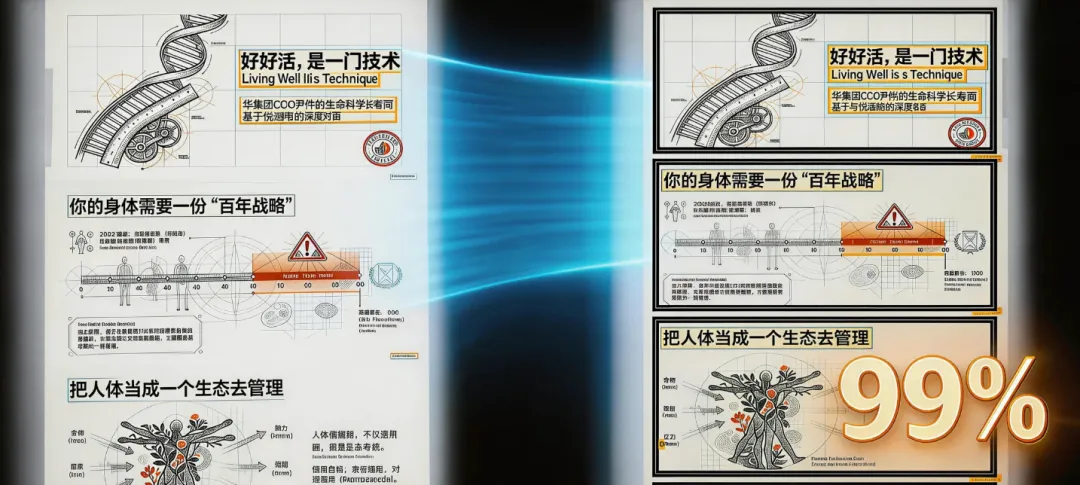
第二,可理解
PDF2Tree,把 PDF 变成树形结构。
不是简单的文字流,而是 LLM 能理解的结构化数据:哪些是标题,哪些是段落,哪些是列表,一层层拆清楚。
文件是负债,API 是资产。静态文件堆在那是成本,结构化之后才是可调用的资产。
PDF2Tree 干的就是这件事:把负债变资产。
这样大模型才能真正”读懂”你的文档,而不是瞎猜。

第三,可执行
PDF2Skills,这是最野的部分。
一本书不该只是用来看的,它该变成可以调用的技能,一本书可以变为app。
比如一本《心理咨询手册》,不是给你读完了事,而是变成一个可以对话的咨询助手。一本《健身指南》,变成根据你身体状况定制训练计划的教练。一本《麻衣神相》,变成帮你分析面相的 AI 工具。
知识的终点不是被记住,是被执行。
怎么用
打开微信小程序,搜”PDF2x”。
上传一个 PDF,选你要的功能:
-
• 要做 PPT?10 秒出稿 -
• 要理清结构?生成思维导图 -
• 要做成 APP?变成可交互的技能
目前完全免费,限时。

若你懒得自己用,以上所有能力,我们也放到了喂养龙虾的社区,来让你的龙虾到这儿觅食(干活)
PDF 这个格式,三十年没人动过它。
3 万亿份文档躺在那,从”数字泥土”到”数字混凝土”,越存越死。
一份论文该变成一场演讲,一本书该变成一个助手,一套方法论该变成可执行的技能。
存档的时代结束了,执行的时代开始了。
