 夜雨聆风
夜雨聆风





Soul App 开源AI歌声合成模型!SoulX-Singer:覆盖多语言、多音色及多种演唱风格!

在语音合成(TTS)与音乐生成模型迅猛发展的浪潮中,一个真正具备工业级可用性的开源歌声合成(SVS)模型正式登场。

由Soul App联合 AIC、天津大学及西北工业大学共同开源的SoulX-Singer,以其4.2万小时高质量数据的雄厚底力与创新的技术架构,将开源AI歌声合成从实验室演示迈向了稳定、可控、真实可用的新阶段。
咱们先来看一段官方演示。
核心功能
SoulX-Singer 的核心使命是解决零样本歌声合成的实际应用难题。与众多实验性模型不同,它的核心定位就是面向工业需求,具备以下鲜明特性:
海量数据基石:使用超过 42,000 小时的高质量歌声数据进行训练,覆盖普通话、英语、粤语,包含上百种音色与数十种演唱风格。
这为其提供了无与伦比的泛化能力,即使面对从未接触过的音色或复杂乐曲,也能生成自然、稳定的演唱。
双重控制范式:提供两种精准控制方式,满足从专业音乐人到普通用户的不同需求。
-
乐谱(MIDI)驱动:可直接导入 MIDI 文件与歌词,模型将严格按照设定的音高、时长和节奏进行演唱,为音乐创作提供精准工具。
-
旋律(F0)驱动:支持“哼唱转歌唱”或“风格迁移”。用户提供一段参考音频(如哼唱或原唱),模型能提取其旋律技巧,并用目标音色重新演绎,极大简化了 AI 翻唱与内容创作的流程。
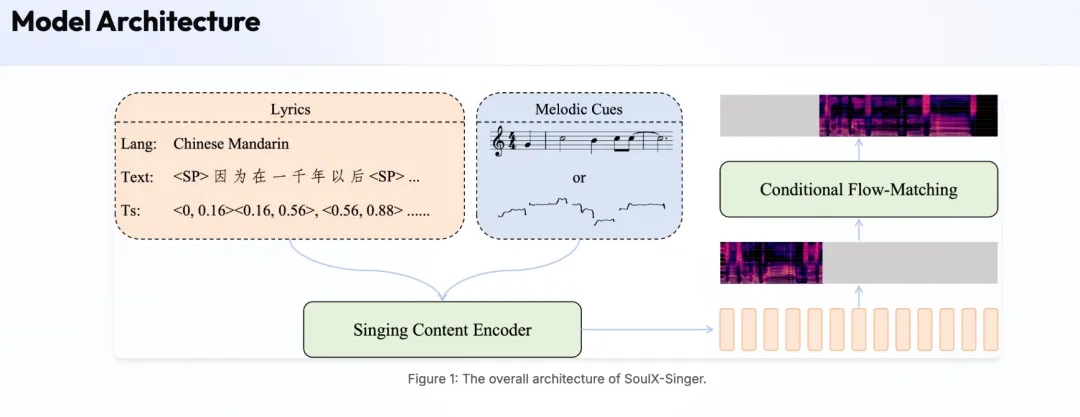
强大的多语言与跨语言能力:除支持普、英、粤三语演唱外,更可实现跨语言风格迁移。例如,可用一段中文歌曲素材,驱动生成标准英语发音的演唱,打破了语言与音色间的壁垒。
技术原理
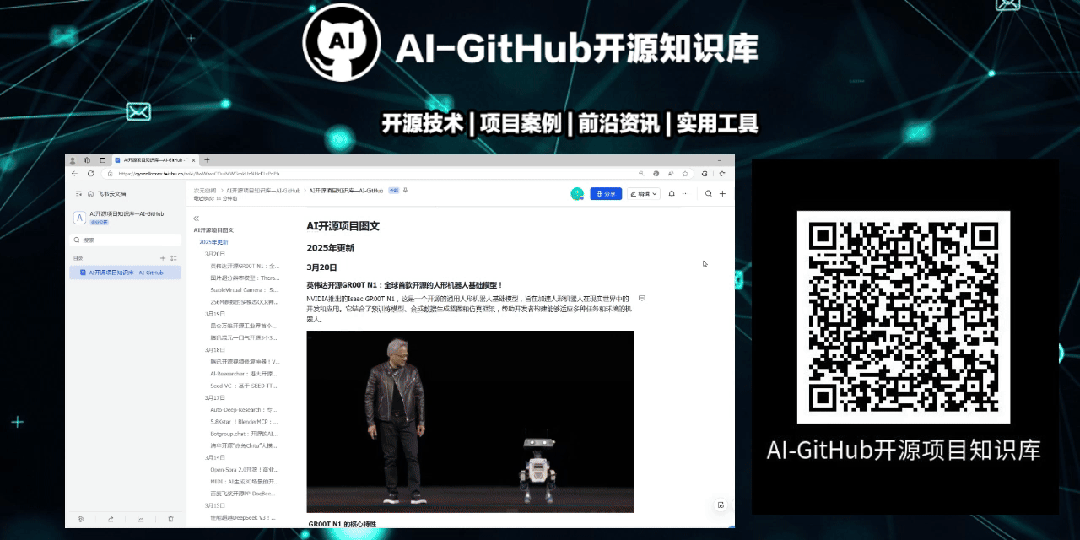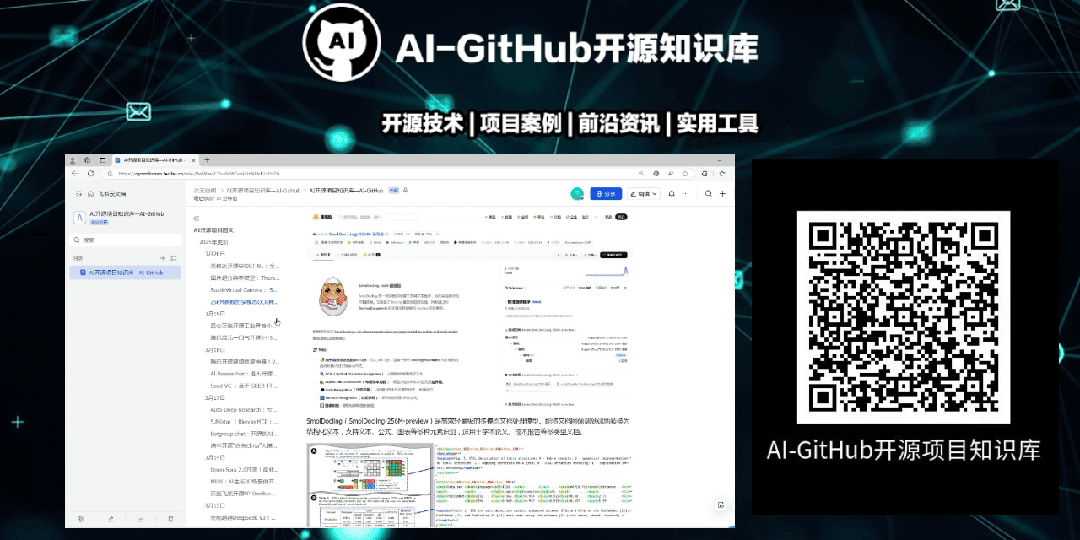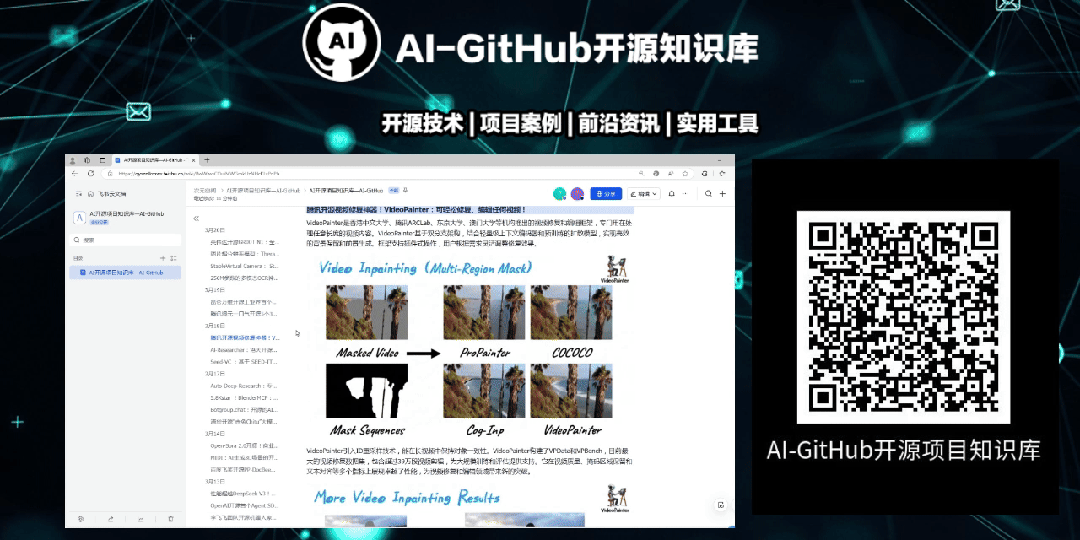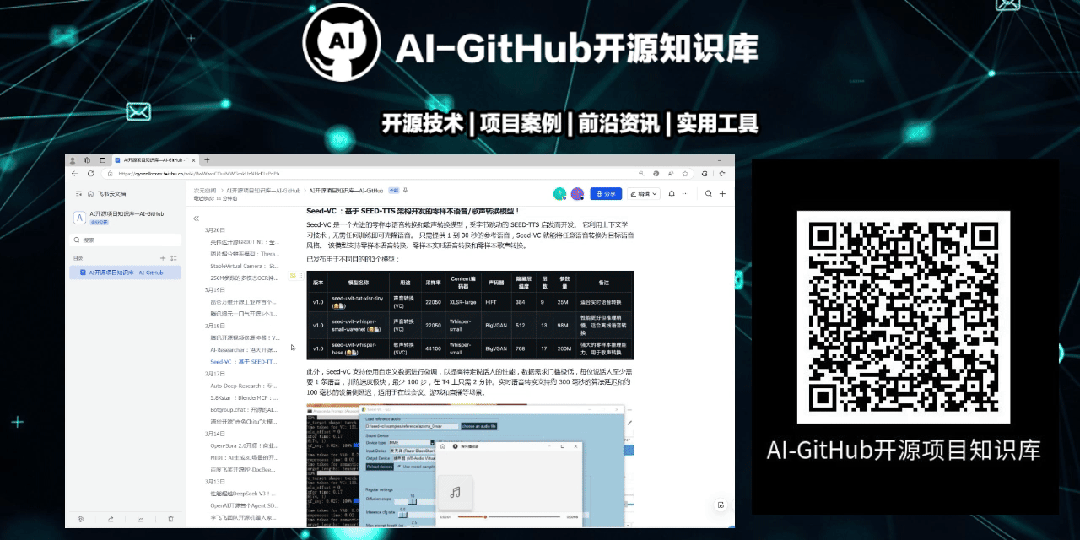
Flow Matching 生成框架:采用流匹配替代传统扩散模型,通过直接学习概率分布的传输路径,实现更高效稳定的音频生成。
Audio Infilling 补全机制:将歌声合成建模为条件化波形补全任务,利用上下文片段预测目标音频,天然保证长时连贯性与音色一致性。
显式多模态对齐:通过长度调节器强制对齐歌词文本、MIDI 音符与声学特征的时序关系,消除隐式对齐带来的节奏偏差与发音模糊。
渐进式两阶段训练:用短片段训练建立乐谱理解能力,长片段训练捕获长程气息控制,最终兼顾局部精确度与全局自然度。
性能表现
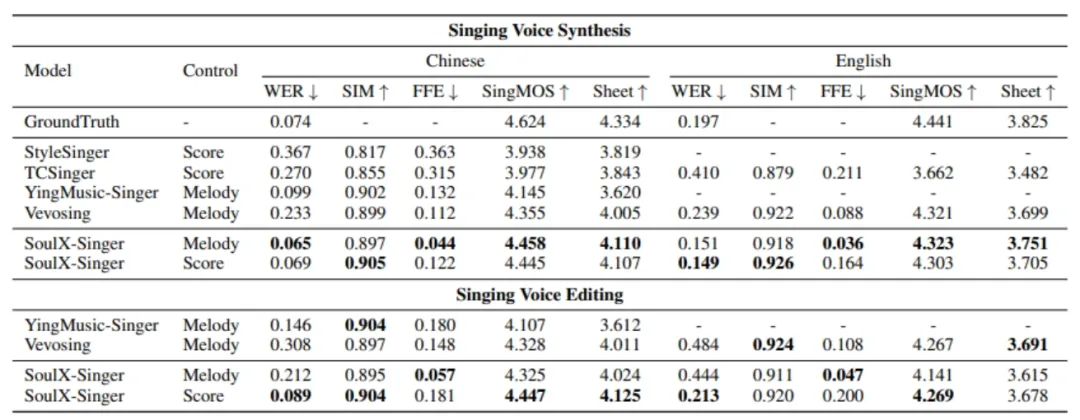
在评测方面,SoulX-Singer 在 GMO-SVS 和 SoulX-Singer-Eval 两个数据集上,对零样本歌声合成、歌词编辑后的歌声合成以及跨语言歌声合成等多项任务进行了系统评测。
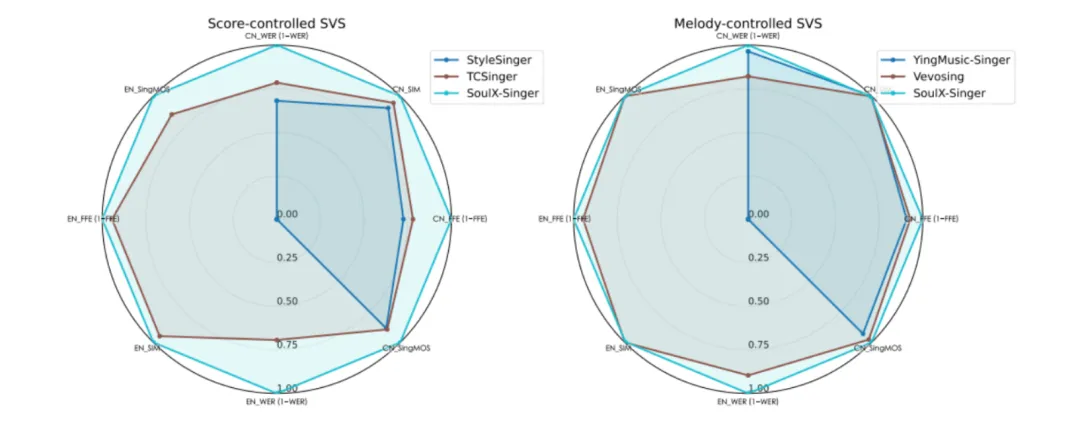
其中,GMO-SVS 综合了 GTSinger、M4Singer 和 Opencpop 等主流开源 SVS 数据集;而 SoulX-Singer-Eval 则专门面向严格的零样本场景构建,通过独立音乐人等渠道采集数据,确保测试歌手未出现在训练集中。
实验结果表明,SoulX-Singer 在语义清晰度、歌手相似度、基频一致性以及整体合成质量等多个维度上均显著优于此前的相关工作;在主观听感评测中,其表现同样取得了明显领先优势。
结语
SoulX-Singer 的发布,以其庞大的数据基础、创新的技术架构、双重控制范式及出色的生成效果,很有可能成为开源歌声合成领域进入工业级应用阶段的一个里程碑。
对于从事音乐创作、虚拟歌手开发或AI内容生成的研究者与开发者而言,该项目无疑是一个值得深入关注和探索的宝贵资源。
GitHub: https://github.com/Soul-AILab/SoulX-Singer项目地址:https://soul-ailab.github.io/soulx-singer/
欢迎扫码加入社群
一起交流AI前沿技术!

小编免费共享AI开源项目知识库,
实现大家的AI资讯自由!
直接扫码或点击链接即可查看!
AI开源项目知识库:https://qyxznlkmwx.feishu.cn/wiki/BwWIwsCOuiMWGmkUzNHcKLvPnPh
