 夜雨聆风
夜雨聆风





OpenClaw 源码漫游指南(十二):测试驱动开发——OpenClaw 的 E2E 与 Live Test 体系
核心观点:对于一个不仅要写代码,还要调用 LLM、连接第三方 API 的 AI Agent 系统来说,传统的单元测试远远不够。OpenClaw 构建了一套分层测试金字塔 (Test Pyramid),定义了 AI 应用的测试标准。
在前面的系列中,我们构建了强大的 Agent、灵活的插件和安全的沙箱。但如何保证这些复杂的组件在持续迭代中不崩塌?
今天,我们深入 docs/testing.md 和 src 目录下的测试文件,看看 OpenClaw 如何驯服 AI 的不确定性。
1. 测试的挑战:AI 的不确定性
测试普通的 Web 应用很简单:输入 1+1,断言输出 2。
但测试 AI Agent 很难:
-
1. 非确定性 (Non-deterministic): 同样的 Prompt,LLM 这次说 “Hello”,下次说 “Hi”。 -
2. 外部依赖 (External Deps): 依赖 OpenAI、Claude、Telegram 等第三方服务,它们可能随时挂掉或改 API。 -
3. 副作用 (Side Effects): Agent 可能会真的去发邮件、写文件,测试不能弄脏生产环境。
OpenClaw 采用了一个三层金字塔模型来解决这些问题:
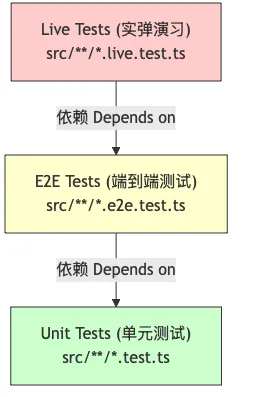
2. 第一层:单元测试 (Unit Tests) —— 极速反馈
目标:测试纯逻辑函数,不涉及 IO,毫秒级响应。
代码位置:src/**/*.test.ts
工具:Vitest
在 src/agents/auth-profiles/auth-profiles.test.ts 中,我们看到了典型的单元测试:
// src/agents/auth-profiles/auth-profiles.test.ts
import{ describe, it, expect }from'vitest';
import{ resolveAuthProfileOrder }from'./order';
describe('Auth Profiles',()=>{
it('should prioritize last used profile (应优先使用上次使用的配置文件)',()=>{
const profiles =['gpt-4','claude-3'];
const result =resolveAuthProfileOrder(profiles,'claude-3');
expect(result[0]).toBe('claude-3');
});
});这层测试覆盖了:
-
• Prompt 模板渲染:确保 {{variable}}被正确替换。 -
• 工具参数解析:确保 JSON Schema 校验逻辑正确。 -
• 配置合并逻辑:确保 defaults和userConfig正确 merge。
它们是开发的安全网,运行速度极快,每次保存代码都会自动运行。
3. 第二层:E2E 测试 (End-to-End) —— 模拟真实环境
目标:测试 Gateway、Agent、Channel 之间的协作,但 Mock 掉外部 LLM 和网络。
代码位置:src/**/*.e2e.test.ts
核心机制:Mock Server
在 src/gateway/gateway.e2e.test.ts 中,OpenClaw 会启动一个真实的 Gateway 实例,但拦截了所有发往 OpenAI 的 HTTP 请求:
// src/gateway/gateway.e2e.test.ts
import{ createGateway }from'../server';
import{ MockOpenAI }from'../test-helpers/openai-mock';
test('Agent should reply to user message (Agent 应回复用户消息)',async()=>{
// 1. 启动网关
const gateway =awaitcreateGateway({ mode:'test'});
// 2. 注入 Mock LLM
const mockLLM =newMockOpenAI();
mockLLM.onChatCompletion((messages)=>{
return{ content:'Hello from Mock AI'};
});
gateway.use(mockLLM);
// 3. 模拟用户发送消息
await gateway.injectMessage({ content:'Hi', channel:'telegram'});
// 4. 断言:Agent 是否调用了 LLM,并且 LLM 的回复是否被推回给了用户
expect(mockLLM.requests).toHaveLength(1);
expect(gateway.outbox).toContain('Hello from Mock AI');
});它验证的是系统链路:
-
• 消息是否正确路由到了 Agent? -
• Agent 的工具调用请求 (Tool Call) 是否正确发回了 Gateway? -
• 权限审批 (Approval) 流程是否被正确触发?
4. 第三层:Live Tests (实弹演习) —— 玩真的!
这是 OpenClaw 测试体系中最震撼的部分。
目标:验证与真实世界的集成(Real Credentials, Real Models)。
代码位置:src/**/*.live.test.ts
命令:pnpm test:live
在 src/gateway/gateway-models.profiles.live.test.ts 中,测试代码会读取你本地环境中的真实 API Key:
// src/gateway/gateway-models.profiles.live.test.ts
import{ loadEnv }from'../test-helpers';
// 只有显式开启 LIVE=1 才运行
test.skipIf(!process.env.LIVE)('Connect to Real OpenAI (连接真实 OpenAI)',async()=>{
// 读取 ~/.profile 或 .env 中的真实 Key
const config =loadEnv();
const response =awaitfetch('https://api.openai.com/v1/chat/completions',{
headers:{ Authorization:`Bearer ${config.OPENAI_API_KEY}`},
// ...
});
expect(response.status).toBe(200);
});它解决的核心问题:
-
• “OpenAI 的 API 格式是不是又变了?” -
• “Claude-3-Opus 的工具调用能力是不是下降了?” -
• “Telegram 的 Long Polling 是否还能收到消息?”
为了防止 Live Test 消耗过多 Token 或造成破坏,OpenClaw 设计了沙箱保护和成本监控,确保测试产生的副作用(如创建的文件)在测试结束后被清理。
5. 深度解密:模拟的艺术 (The Art of Simulation)
除了连接真实 API,OpenClaw 还实现了一套极高保真的 流式模拟器 (Streaming Simulator)。
在 src/gateway/test-helpers.openai-mock.ts 中,我们发现了 fakeOpenAIResponsesStream 函数。它不仅仅是返回一个 JSON,而是逐字逐句地模拟 LLM 的 SSE (Server-Sent Events) 数据流:
// src/gateway/test-helpers.openai-mock.ts
asyncfunction*fakeOpenAIResponsesStream(params: OpenAIResponsesParams){
// 1. 模拟 Tool Call 的思考过程
yield{
type:"response.output_item.added",
item:{ type:"function_call", name:"read", arguments:""},
};
// 2. 模拟参数生成的延迟 (Delta)
yield{ type:"response.function_call_arguments.delta", delta:'{"path":'};
yield{ type:"response.function_call_arguments.delta", delta:'"package.json"}'};
// 3. 模拟完成
yield{ type:"response.output_item.done",...};
}这种级别的模拟确保了 Gateway 的流式处理管道(如打字机效果、背压控制)在单元测试阶段就能经受住考验,而不仅仅是测通了 Request/Response。
6. Docker 测试矩阵
除了代码层面的测试,OpenClaw 还有一套基于 Docker 的集成测试。
脚本位于 scripts/test-docker-*.sh。
它会在 Docker 容器中从零构建环境,模拟用户的全新安装过程:
-
1. Clean Install: npm install -g openclaw -
2. Bootstrap: 启动 Gateway。 -
3. Pairing: 进行 Node Pairing (节点配对)。 -
4. Task: 执行实际任务(如 “分析 README.md”)。
这种在 CI 环节引入 Docker 隔离环境的做法,极大地提升了发版信心。以下是 scripts/e2e/onboard-docker.sh 的核心片段,它展示了如何在没有图形界面的容器中,通过模拟键盘输入(send)和日志断言(wait_for_log)来验证 CLI 交互:
# scripts/e2e/onboard-docker.sh
# 模拟键盘输入
send(){
localpayload="$1"
localdelay="${2:-0.4}"
sleep"$delay"
# 将输入写入文件描述符 3,模拟 TTY 输入
printf"%b""$payload">&32>/dev/null ||true
}
# 智能等待日志出现
wait_for_log(){
localneedle="$1"
whiletrue;do
ifgrep-a-F-q"$needle""$WIZARD_LOG_PATH";then
return0
fi
# ... 超时处理 ...
sleep0.2
done
}
# 实际测试流程
echo"Running onboarding E2E..."
docker run --rm-t"$IMAGE_NAME"bash-lc'
# 启动 Gateway
start_gateway
wait_for_gateway
# 模拟用户操作:回车确认 -> 输入 Token -> 验证成功日志
send "\n" # Confirm start
wait_for_log "Please enter your token"
send "sk-fake-token\n"
wait_for_log "Setup complete"
'这不仅验证了代码逻辑,更验证了完整的用户体验流程。
7. 深度测试配置:Vitest 覆盖率与 CI 策略
在 vitest.config.ts 中,OpenClaw 定义了严格的代码质量门槛。这不仅仅是一个配置文件,更是团队对代码质量的承诺。
7.1 覆盖率门槛 (Coverage Thresholds)
OpenClaw 并不追求盲目的 100% 覆盖率,而是设定了一个务实的目标:
// vitest.config.ts
coverage:{
provider:"v8",
thresholds:{
lines:70,// 行覆盖率 70%
functions:70,// 函数覆盖率 70%
branches:55,// 分支覆盖率 55%
statements:70,// 语句覆盖率 70%
},
// 排除 CLI 和 UI 层,专注于核心逻辑
exclude:[
"src/cli/**",
"src/tui/**",
"src/discord/**"// Channel 层通常由 Live Test 覆盖
]
}设计哲学:
-
• 核心逻辑 (Core Logic):必须有高覆盖率。例如 src/agents和src/memory。 -
• 交互层 (Interaction Layer):如 CLI 和 TUI,很难通过单元测试模拟(涉及 ANSI 转义码、键盘事件),因此被明确排除,转而依赖 Docker E2E 测试来验证。 -
• 分支覆盖率 (Branch Coverage):设定为 55% 较低,是因为 AI 代码中常有大量的 defensive coding(防御性编程)和 fallback logic(如 LLM 返回格式错误时的兜底),这些边缘情况在正常测试中很难全部触发。
7.2 并行化与 CI 优化
在 CI 环境(GitHub Actions)中,测试速度就是金钱。OpenClaw 在 vitest.config.ts 中实现了智能的并发控制:
// vitest.config.ts
const isCI = process.env.CI==="true";
const isWindows = process.platform ==="win32";
// 本地开发利用所有 CPU 核心,CI 环境限制 worker 数量以避免 OOM
const localWorkers = Math.max(4, Math.min(16, os.cpus().length));
const ciWorkers = isWindows ?2:3;
exportdefaultdefineConfig({
test:{
pool:"forks",// 使用进程隔离而非线程,防止全局变量污染
maxWorkers: isCI ? ciWorkers : localWorkers,
}
});这种配置确保了:
-
1. 本地开发快:开发者在 MacBook Pro 上跑测试时,能跑满 16 个核,秒级出结果。 -
2. CI 稳定:在资源受限的 CI 容器中,限制并发数,防止因内存不足导致测试随机失败(Flaky Tests)。
8. 开发者设计哲学与方法论 (Developer Design Philosophy & Methodology)
以下设计原则将帮助你写出符合项目“味道”的代码:
8.1 测试方法论 (Testing Methodology)
-
• 金字塔策略: -
• Unit Tests ( *.test.ts): 覆盖核心逻辑分支,Mock 所有 I/O。要求运行速度极快。 -
• Live Tests ( LIVE=1 pnpm test:live): 针对真实 Provider(如 Anthropic API)的集成测试。这是验证 API 变更的最有效手段。 -
• Docker E2E: 验证完整镜像构建和启动流程。 -
• 快照测试 (Snapshot Testing): -
• 对于复杂的 Prompt 生成逻辑或 CLI 输出,使用 Vitest 的 toMatchSnapshot()。这能帮你捕捉到任何微小的文本变动,防止 Prompt 劣化。
8.2 开发习惯 (Habits)
-
• Commit 规范: 遵循 Conventional Commits (如 feat(cli): add verbose flag)。保持 Git 历史整洁,不仅是为了好看,更是为了能自动生成 Changelog。 -
• 文档即代码: 在修改功能时,同步更新 docs/下的文档。过期的文档比没有文档更糟糕。
9. 当前局限性与未来展望 (Limitations & Future Work)
-
• UI 测试缺口: -
• 目前的测试主要集中在逻辑层和协议层,对于 CLI 交互界面(TUI)和 Canvas UI 的自动化测试覆盖率较低。 -
• Live Test 成本: -
• 运行全套 Live Test 需要消耗真实的 Token,随着测试用例增加,CI 成本会线性上升。可以建立更完善的 (流量回放) 机制,录制一次真实交互,后续测试尽量复用录制数据。
10. 总结:信心来自测试
宁可由开发者发现错误,也不要由用户发现错误。
通过 Unit (逻辑正确) -> E2E (链路打通) -> Live (真实集成) -> Docker (环境一致) 的四层防护网,OpenClaw 建立了一个坚固的质量堡垒。对于任何想要开发生产级 AI 应用的团队来说,这套测试体系都是教科书级别的范例。
下一篇,我们将深入 OpenClaw 的神经中枢:Condition Reflex System —— 自动回复与消息分发引擎。 看看它是如何在 LLM 介入之前,像脊髓反射一样处理高频交互的。
