 夜雨聆风
夜雨聆风





Soul App 联合吉利汽车研究院 AIC、天津大学及西北工业大学,正式开源SoulX-Singer,主打工业级稳定可控 + 三语全能
Soul App 联合吉利汽车研究院 AIC、天津大学及西北工业大学,正式开源SoulX-Singer—— 一款基于42000 小时高质量歌声数据训练的零样本歌声合成(SVS)模型,主打工业级稳定可控 + 三语全能,可在未见过歌手音色的情况下,生成普通话、英语、粤语三种语言的自然歌声,彻底解决 SVS 领域 “零样本能力弱、可控性差、音质不稳定” 三大痛点。

模型背景与目标
背景:生成式人工智能在音乐行业的应用正不断创造新体验,但歌唱语音合成(SVS)领域整体进展相对缓慢。为拓展这一领域,Soul App AI 团队联合多家机构正式开源了歌声合成模型 SoulX-Singer。
目标:SoulX-Singer 是一个面向真实工业应用场景设计的零样本歌声合成模型,其核心目标是在未见过歌手音色的情况下,实现稳定、自然且高度可控的歌声生成。
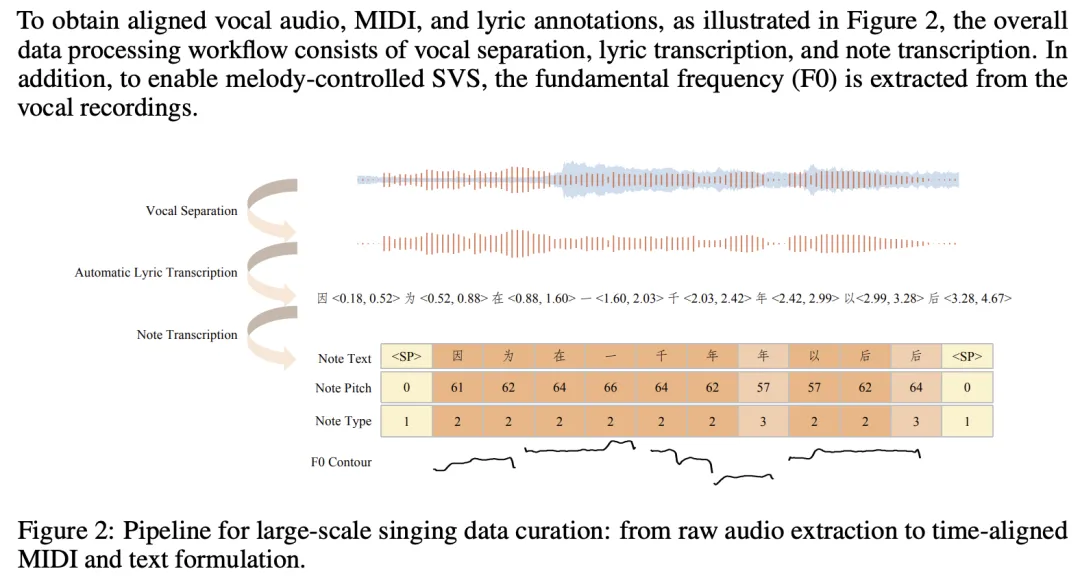
模型特点与优势
大规模训练数据:
SoulX-Singer 得益于超过 42000 小时的高质量歌声数据进行训练,覆盖多语言、多音色及多种演唱风格。
在如此大规模数据的支持下,模型在面对未见过的歌手与复杂音乐条件时,依然能够保持稳定、自然且高质量的合成表现。
先进的模型架构:
SoulX-Singer 采用基于 Flow Matching 的生成建模范式,并将歌声合成问题建模为一种 audio infilling(音频补全)任务。
针对歌声合成中“歌词—旋律—发声”三者强耦合的特点,SoulX-Singer 在建模阶段显式引入了 note 级别的对齐机制,使得每一个音符的起止时间、音高(pitch)以及持续时长都能够被准确建模和独立控制。
多种控制方式:
SoulX-Singer 同时支持基于 Music Score(MIDI)和基于 Melody 的两种歌声合成控制方式。
Music Score(MIDI)驱动生成支持直接基于乐谱与歌词生成歌声,适用于音乐创作、歌词编辑、歌曲重制等场景。
Melody 驱动生成支持从已有歌曲旋律出发进行歌声合成,可复刻参考音频中的演唱技巧与表达方式,适用于翻唱、风格迁移等应用场景。
多语言支持:
SoulX-Singer 当前支持普通话、英语和粤语三种语言的歌声合成,并在不同语言和音乐风格下均展现出稳定一致的合成质量。
模型评测与表现
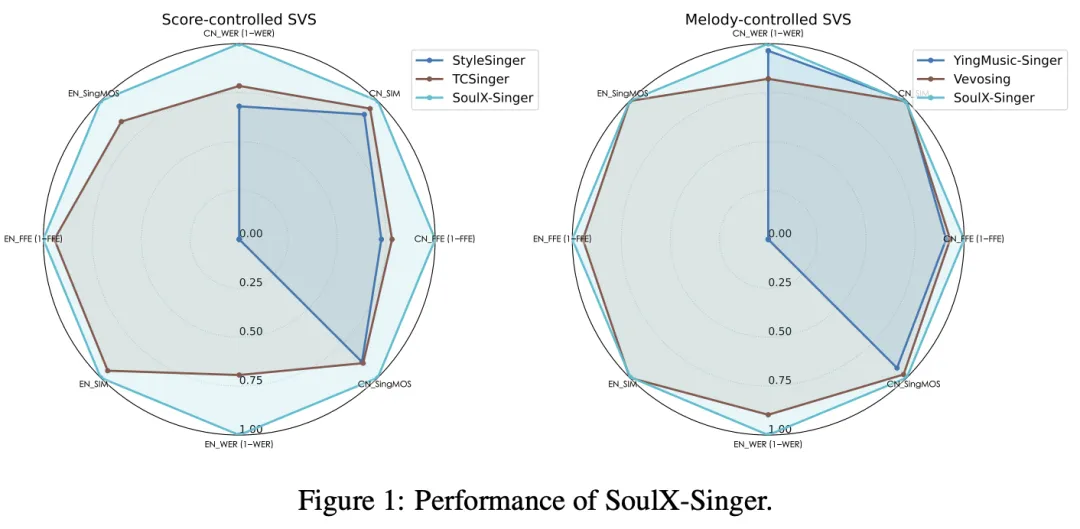
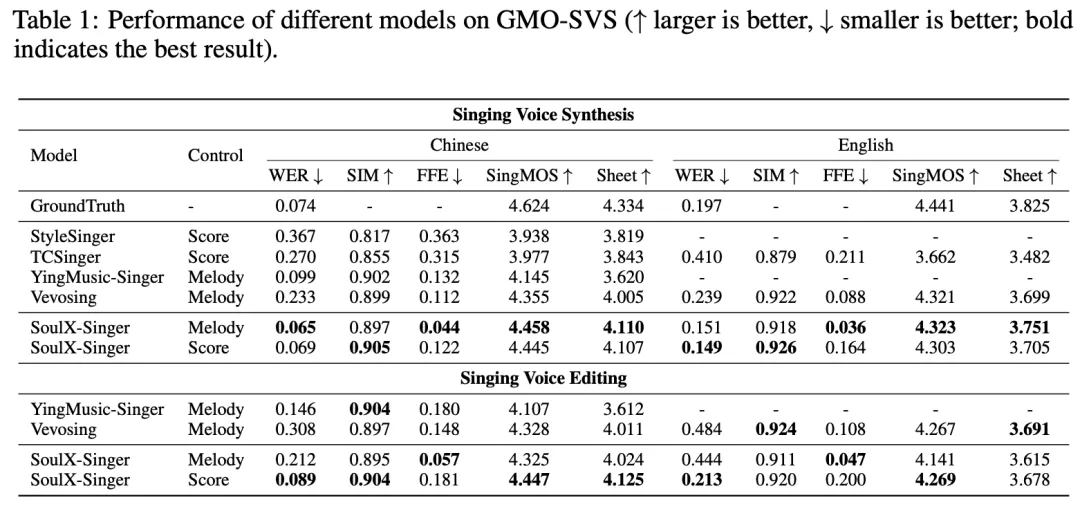
SoulX-Singer 在 GMO-SVS 和 SoulX-Singer-Eval 两个数据集上,对零样本歌声合成、歌词编辑后的歌声合成以及跨语言歌声合成等多项任务进行了系统评测。
实验结果表明,SoulX-Singer 在语义清晰度、歌手相似度、基频一致性以及整体合成质量等多个维度上均显著优于此前的相关工作。
在主观听感评测中,SoulX-Singer 的表现同样取得了明显领先优势。
SoulX-Singer 的核心价值在于:42000 小时数据训练的零样本能力 + 三语全能 + 工业级稳定可控,将歌声合成技术从实验室推向大规模应用。它不仅是一款开源模型,更是音乐创作、娱乐互动等领域的 “生产力工具”,有望重塑 AI 音乐生态。
