 夜雨聆风
夜雨聆风





iReg小程序-统计Word和PDF字符数
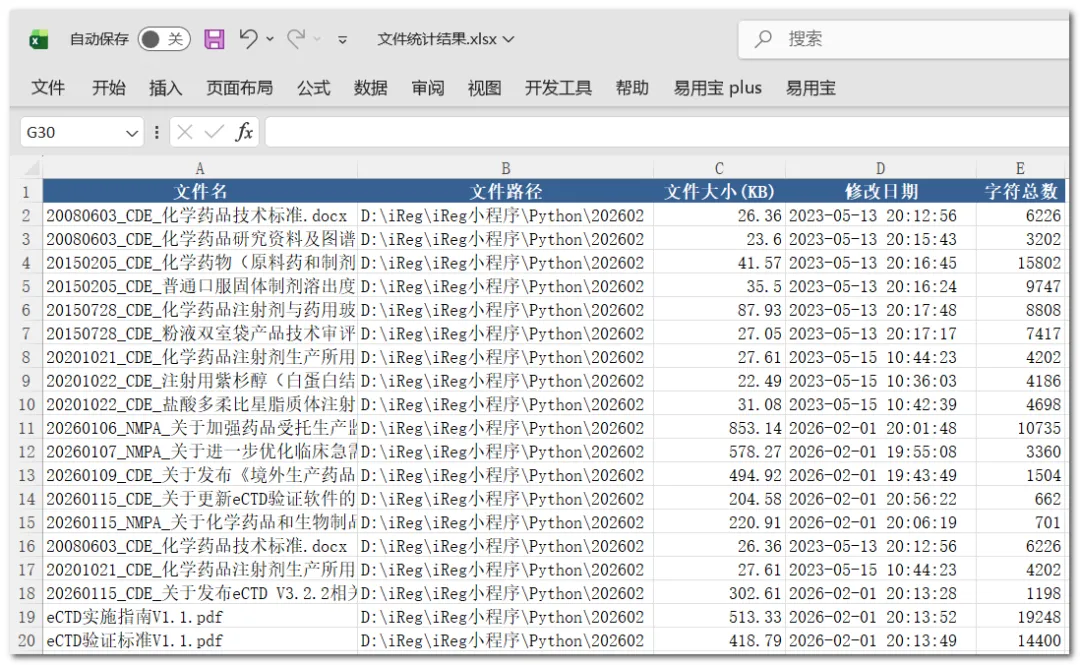
 ),小格用Python开发了一个小程序,可以将指定文件夹及其子文件夹下所有docx和pdf文件的文件名、文件路径、修改日期、文件大小和字符数汇总到一个Excel文件中:
),小格用Python开发了一个小程序,可以将指定文件夹及其子文件夹下所有docx和pdf文件的文件名、文件路径、修改日期、文件大小和字符数汇总到一个Excel文件中: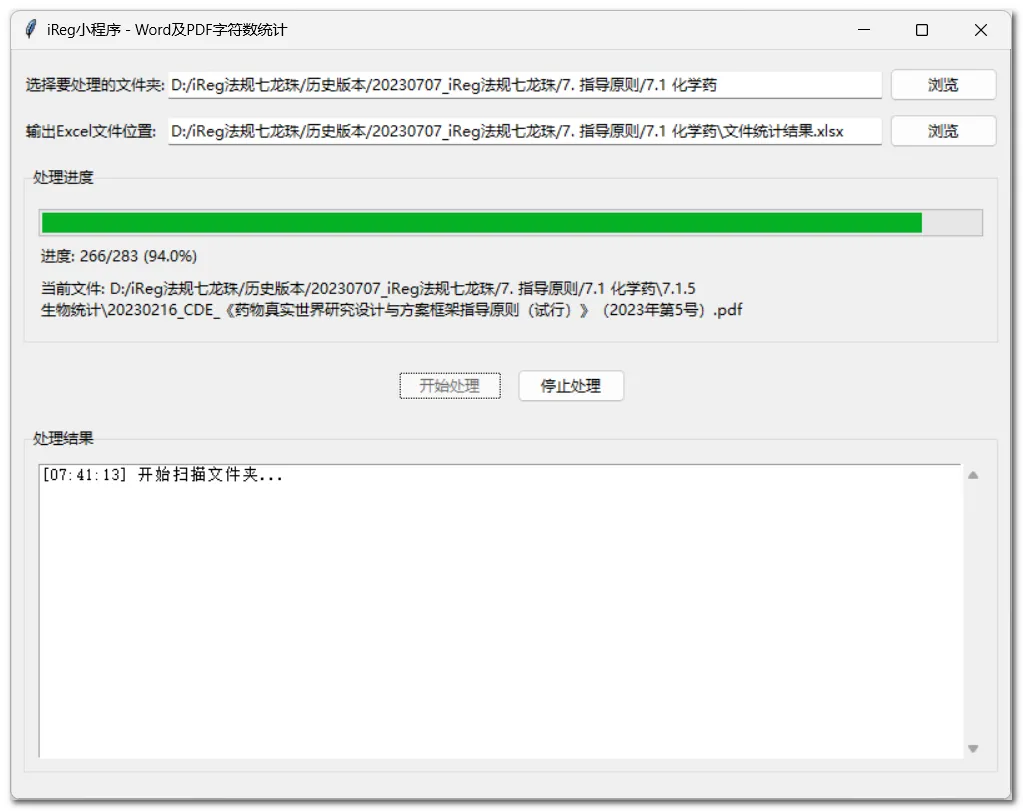
https://pan.baidu.com/s/1MamQJMIeFYOQm6wilQVGdA?pwd=iReg

同时把源代码分享如下,欢迎大家提出宝贵意见,大家日常工作如果有特别重复繁琐的工作,也欢迎提出来,小格可以试着为大家开发自动化的解决方案~~
import osimport tkinter as tkfrom tkinter import ttk, filedialog, messageboxfrom datetime import datetimeimport threadingimport queueimport time# 导入文件处理相关的库try:from docx import Documentimport PyPDF2from openpyxl import Workbookfrom openpyxl.styles import Font, Alignment, PatternFillexcept ImportError:# 如果库未安装,在运行时提示passclass FileProcessor:def __init__(self):self.file_queue = queue.Queue()self.results = []self.is_running = Falsedef count_docx_characters(self, file_path):"""统计docx文件的字符数"""try:doc = Document(file_path)text = ""for paragraph in doc.paragraphs:text += paragraph.textreturn len(text)except Exception as e:print(f"Error reading docx file {file_path}: {e}")return 0def count_pdf_characters(self, file_path):"""统计pdf文件的字符数"""try:with open(file_path, 'rb') as file:pdf_reader = PyPDF2.PdfReader(file)text = ""for page in pdf_reader.pages:text += page.extract_text() or ""return len(text)except Exception as e:print(f"Error reading pdf file {file_path}: {e}")return 0def get_file_info(self, file_path):"""获取文件信息"""try:file_stat = os.stat(file_path)file_size = file_stat.st_size / 1024 # 转换为KBmod_time = datetime.fromtimestamp(file_stat.st_mtime)mod_date = mod_time.strftime("%Y-%m-%d %H:%M:%S")# 统计字符数char_count = 0if file_path.lower().endswith('.docx'):char_count = self.count_docx_characters(file_path)elif file_path.lower().endswith('.pdf'):char_count = self.count_pdf_characters(file_path)return {'文件名': os.path.basename(file_path),'文件路径': file_path.replace('/', '\\'),'文件大小(KB)': round(file_size, 2),'修改日期': mod_date,'字符总数': char_count}except Exception as e:print(f"Error processing file {file_path}: {e}")return Nonedef find_files(self, folder_path):"""查找所有docx和pdf文件"""supported_extensions = ('.docx', '.pdf')file_paths = []for root, dirs, files in os.walk(folder_path):for file in files:if file.lower().endswith(supported_extensions):file_paths.append(os.path.join(root, file))return file_pathsdef process_files(self, folder_path, progress_callback=None):"""处理文件的主函数"""self.is_running = Trueself.results = []# 查找所有文件file_paths = self.find_files(folder_path)total_files = len(file_paths)if total_files == 0:return False, "未找到任何docx或pdf文件"# 处理每个文件for i, file_path in enumerate(file_paths):if not self.is_running:breakfile_info = self.get_file_info(file_path)if file_info:self.results.append(file_info)# 更新进度if progress_callback:progress = (i + 1) / total_files * 100progress_callback(progress, i + 1, total_files, file_path)return True, f"处理完成,共处理 {len(self.results)} 个文件"def stop_processing(self):"""停止处理"""self.is_running = Falseclass FileProcessorApp:def __init__(self, root):self.root = rootself.root.title("iReg小程序 - Word及PDF字符数统计")self.root.geometry("800x600")self.processor = FileProcessor()self.setup_ui()def setup_ui(self):"""设置用户界面"""# 主框架main_frame = ttk.Frame(self.root, padding="10")main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))# 配置网格权重self.root.columnconfigure(0, weight=1)self.root.rowconfigure(0, weight=1)main_frame.columnconfigure(1, weight=1)# 选择文件夹区域ttk.Label(main_frame, text="选择要处理的文件夹:").grid(row=0, column=0, sticky=tk.W, pady=5)self.folder_path = tk.StringVar()ttk.Entry(main_frame, textvariable=self.folder_path, width=60).grid(row=0, column=1, sticky=(tk.W, tk.E), pady=5, padx=(0, 5))ttk.Button(main_frame, text="浏览", command=self.browse_folder).grid(row=0, column=2, pady=5)# 输出文件夹区域ttk.Label(main_frame, text="输出Excel文件位置:").grid(row=1, column=0, sticky=tk.W, pady=5)self.output_path = tk.StringVar()ttk.Entry(main_frame, textvariable=self.output_path, width=60).grid(row=1, column=1, sticky=(tk.W, tk.E), pady=5, padx=(0, 5))ttk.Button(main_frame, text="浏览", command=self.browse_output).grid(row=1, column=2, pady=5)# 进度区域progress_frame = ttk.LabelFrame(main_frame, text="处理进度", padding="10")progress_frame.grid(row=2, column=0, columnspan=3, sticky=(tk.W, tk.E, tk.N, tk.S), pady=10)progress_frame.columnconfigure(0, weight=1)self.progress_var = tk.DoubleVar()self.progress_bar = ttk.Progressbar(progress_frame, variable=self.progress_var, maximum=100)self.progress_bar.grid(row=0, column=0, sticky=(tk.W, tk.E), pady=5)self.progress_label = ttk.Label(progress_frame, text="准备就绪")self.progress_label.grid(row=1, column=0, sticky=tk.W)self.current_file_label = ttk.Label(progress_frame, text="", wraplength=700)self.current_file_label.grid(row=2, column=0, sticky=tk.W, pady=5)# 按钮区域button_frame = ttk.Frame(main_frame)button_frame.grid(row=3, column=0, columnspan=3, pady=10)self.start_button = ttk.Button(button_frame, text="开始处理", command=self.start_processing)self.start_button.pack(side=tk.LEFT, padx=5)self.stop_button = ttk.Button(button_frame, text="停止处理", command=self.stop_processing, state=tk.DISABLED)self.stop_button.pack(side=tk.LEFT, padx=5)# 结果区域result_frame = ttk.LabelFrame(main_frame, text="处理结果", padding="10")result_frame.grid(row=4, column=0, columnspan=3, sticky=(tk.W, tk.E, tk.N, tk.S), pady=10)result_frame.columnconfigure(0, weight=1)result_frame.rowconfigure(0, weight=1)# 文本框和滚动条text_frame = ttk.Frame(result_frame)text_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))text_frame.columnconfigure(0, weight=1)text_frame.rowconfigure(0, weight=1)self.result_text = tk.Text(text_frame, height=15, wrap=tk.WORD)scrollbar = ttk.Scrollbar(text_frame, orient=tk.VERTICAL, command=self.result_text.yview)self.result_text.configure(yscrollcommand=scrollbar.set)self.result_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))scrollbar.grid(row=0, column=1, sticky=(tk.N, tk.S))# 配置主框架的行权重main_frame.rowconfigure(4, weight=1)def browse_folder(self):"""选择要处理的文件夹"""folder = filedialog.askdirectory()if folder:self.folder_path.set(folder)# 自动设置输出路径if not self.output_path.get():self.output_path.set(os.path.join(folder, "文件统计结果.xlsx"))def browse_output(self):"""选择输出Excel文件位置"""filename = filedialog.asksaveasfilename(defaultextension=".xlsx",filetypes=[("Excel files", "*.xlsx"), ("All files", "*.*")])if filename:self.output_path.set(filename)def update_progress(self, progress, current, total, current_file):"""更新进度显示"""self.progress_var.set(progress)self.progress_label.config(text=f"进度: {current}/{total} ({progress:.1f}%)")self.current_file_label.config(text=f"当前文件: {current_file}")self.root.update_idletasks()def log_message(self, message):"""在结果区域记录消息"""timestamp = datetime.now().strftime("%H:%M:%S")self.result_text.insert(tk.END, f"[{timestamp}] {message}\n")self.result_text.see(tk.END)self.root.update_idletasks()def save_to_excel(self, results, output_path):"""使用openpyxl保存结果到Excel文件"""# 创建工作簿和工作表wb = Workbook()ws = wb.activews.title = "文件统计结果"# 定义表头headers = ['文件名', '文件路径', '文件大小(KB)', '修改日期', '字符总数']# 设置表头样式header_font = Font(bold=True, color="FFFFFF")header_fill = PatternFill(start_color="366092", end_color="366092", fill_type="solid")alignment = Alignment(horizontal="center", vertical="center")# 写入表头for col, header in enumerate(headers, 1):cell = ws.cell(row=1, column=col, value=header)cell.font = header_fontcell.fill = header_fillcell.alignment = alignment# 写入数据total_chars = 0total_size = 0for row, result in enumerate(results, 2):ws.cell(row=row, column=1, value=result['文件名'])ws.cell(row=row, column=2, value=result['文件路径'])ws.cell(row=row, column=3, value=result['文件大小(KB)'])ws.cell(row=row, column=4, value=result['修改日期'])ws.cell(row=row, column=5, value=result['字符总数'])# 累加统计信息total_chars += result['字符总数']total_size += result['文件大小(KB)']# 自动调整列宽for column in ws.columns:max_length = 0column_letter = column[0].column_letterfor cell in column:try:if len(str(cell.value)) > max_length:max_length = len(str(cell.value))except:passadjusted_width = min(max_length + 2, 50)ws.column_dimensions[column_letter].width = adjusted_width# 保存文件wb.save(output_path)return total_chars, total_sizedef start_processing(self):"""开始处理文件"""if not self.folder_path.get():messagebox.showerror("错误", "请选择要处理的文件夹")returnif not self.output_path.get():messagebox.showerror("错误", "请选择输出Excel文件位置")return# 检查必要的库是否安装try:from docx import Documentimport PyPDF2from openpyxl import Workbookfrom openpyxl.styles import Font, Alignment, PatternFillexcept ImportError:messagebox.showerror("错误", "请先安装必要的库:\npip install python-docx PyPDF2 openpyxl")return# 禁用开始按钮,启用停止按钮self.start_button.config(state=tk.DISABLED)self.stop_button.config(state=tk.NORMAL)# 清空结果区域self.result_text.delete(1.0, tk.END)# 在新线程中处理文件self.processing_thread = threading.Thread(target=self.process_files_thread)self.processing_thread.daemon = Trueself.processing_thread.start()def process_files_thread(self):"""在新线程中处理文件"""try:self.log_message("开始扫描文件夹...")success, message = self.processor.process_files(self.folder_path.get(),self.update_progress)if success and self.processor.results:# 保存到Excelself.log_message("正在生成Excel文件...")total_chars, total_size = self.save_to_excel(self.processor.results, self.output_path.get())self.log_message(f"处理完成!共处理 {len(self.processor.results)} 个文件")self.log_message(f"结果已保存到: {self.output_path.get()}")# 显示统计信息self.log_message(f"总字符数: {total_chars:,}")self.log_message(f"总文件大小: {total_size:.2f} KB")else:self.log_message(message)except Exception as e:self.log_message(f"处理过程中发生错误: {str(e)}")finally:# 重新启用开始按钮,禁用停止按钮self.root.after(0, self.processing_finished)def processing_finished(self):"""处理完成后的清理工作"""self.start_button.config(state=tk.NORMAL)self.stop_button.config(state=tk.DISABLED)self.progress_var.set(0)self.progress_label.config(text="处理完成")def stop_processing(self):"""停止处理"""self.processor.stop_processing()self.log_message("正在停止处理...")self.stop_button.config(state=tk.DISABLED)def main():# 检查必要的库是否安装try:from docx import Documentimport PyPDF2from openpyxl import Workbookfrom openpyxl.styles import Font, Alignment, PatternFillexcept ImportError as e:print("请先安装必要的库:")print("pip install python-docx PyPDF2 openpyxl")returnroot = tk.Tk()app = FileProcessorApp(root)root.mainloop()if __name__ == "__main__":main()
