 夜雨聆风
夜雨聆风





无代码LLM平台重塑文档处理
导读:还在为从五花八门的文档里提取结构化数据而头疼吗?GitHub上这个爆火的无代码LLM平台,让你用“画图”的方式定义数据,一键生成API和ETL管道,号称能达到接近100%的准确率。
大家好,我是你们的科技观察员。今天要聊的,是GitHub Trending上一个迅速蹿红的项目——Unstract。这个项目定位非常精准:“Agentic Workflows的数据层”。简单说,它要解决的就是AI应用开发中最磨人的一个环节——如何从PDF、Word、邮件等非结构化文档中,稳定、准确地提取出我们需要的结构化数据。
一、痛点:从文档到数据的“最后一公里”
无论是构建智能客服、自动化财务系统,还是开发一个能读懂合同的AI Agent,开发者都绕不开一个核心问题:如何让LLM理解并提取文档中的关键信息?传统方法要么需要复杂的规则引擎,要么需要大量标注数据训练模型,成本高、周期长、灵活性差。
⚡ Unstract的解法
它提供了一个无代码的“Prompt Studio”环境。你无需编写复杂代码,只需通过可视化界面定义你希望提取的数据“Schema”(比如合同中的“甲方”、“金额”、“签署日期”),平台会自动为你生成和优化提示词,并调用底层LLM(支持多种模型)完成高精度提取。
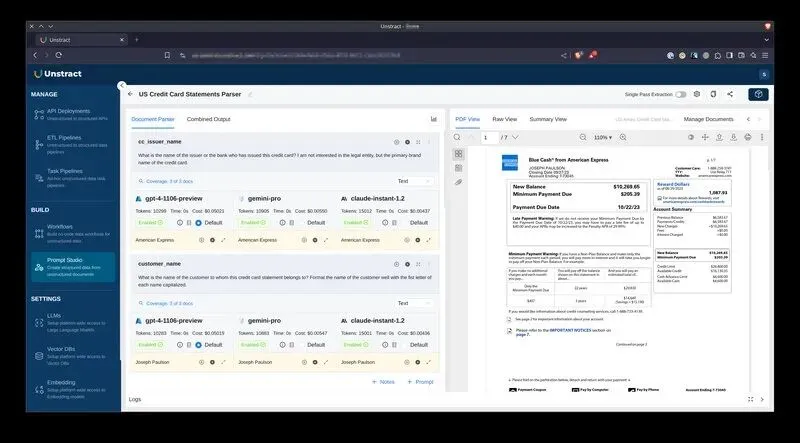
Unstract的核心——Prompt Studio界面,可对比不同LLM的输出并优化提示词
二、核心亮点:不止于API,四种集成范式
Unstract最吸引人的地方在于,它不是一个孤立的工具。当你用Prompt Studio定义好数据提取逻辑后,它可以一键转化为多种可部署的形态,无缝嵌入到你现有的技术栈中。
1. MCP服务器:这是为AI Agent生态量身打造的。将Unstract作为MCP(Model Context Protocol)服务器运行,你的Agent或LLM应用就能直接调用它,获得结构化数据提取能力,就像调用一个内置函数一样简单。
2. REST API:最通用的方式。一键将项目部署为API端点,任何应用程序通过一个HTTP请求,就能把文档变成规整的JSON。
3. ETL管道:直接嵌入到数据工程流程中。在将海量文档数据灌入数据仓库前,用Unstract进行批处理清洗和结构化,极大减轻了数据工程师的负担。
4. n8n节点:为低代码/无代码自动化而生。以预制节点的形式出现在n8n等自动化平台中,让业务人员也能通过拖拽搭建包含智能文档处理的流程。
“它本质上是一个‘数据提取即服务’的生成器。你定义What(要什么数据),它解决How(如何稳定获取),并提供多种Where(部署到哪里)的选项。”—— 一位早期用户的评价
三、快速上手:云服务与本地部署
对于想立即体验的开发者,最快捷的方式是使用其官方云服务。注册后即可进入Prompt Studio开始创建项目。项目也提供了完善的本地和私有化部署方案。
使用Docker Compose可以快速在本地拉起全套服务:
git clone https://github.com/Zipstack/unstract.gitcd unstract
docker-compose up -d
启动后,访问本地端口即可开始使用。项目基于Python构建,技术栈现代,代码质量颇高,从它详尽的SonarCloud质量检测徽章就可见一斑。
Unstract项目Logo
四、谁最适合使用Unstract?
1. AI应用开发者:正在构建基于LLM的Agent、Copilot或垂直领域智能工具,急需可靠的文档信息抽取模块。
2. 数据工程团队:需要处理大量非结构化文档数据源(如扫描件、报告、表单),并希望将其自动化、批量化地转换为可分析的表格数据。
3. 企业IT与业务自动化团队:希望通过低代码方式,将发票处理、合同审核、简历解析等文档密集型工作流自动化。
4. 独立开发者与小团队:缺乏专业的NLP算法工程师,但希望快速为自己的产品增加智能文档处理功能。
· · ·
总的来说,Unstract的出现,标志着LLM应用开发正从“玩具演示”走向“生产级系统”。它填补了“强大的LLM模型”与“稳定的业务数据输入”之间的关键缺口。项目开源仅数月,就获得了超过6000颗星,社区活跃,文档齐全,非常值得正在寻找文档智能处理方案的开发者们深入研究和尝试。
随着AI Agent生态的爆发,像Unstract这样专注于提供标准化、可部署、高可靠数据能力的“中间件”或“数据层”项目,价值会愈发凸显。它或许能成为你下一个AI产品中,那个默默无闻却至关重要的“数据基石”。
