 夜雨聆风
夜雨聆风





读GLM-5模型架构源码有感 | 大模型架构的设计空间可能已经被充分探索,并收敛出了最优解
前两天智谱发布了GLM-5,也在Huggingface上开放了权重和推理代码(代码链接见文末附录),从中可以一窥模型架构。对比GLM-4.7,GLM-5的架构绝对是一次值得玩味的迭代。注:这两天发布的豆包Seed-2.0 Pro也很能打,可惜没开源,公布的近百页的技术报告也几乎没提模型架构。
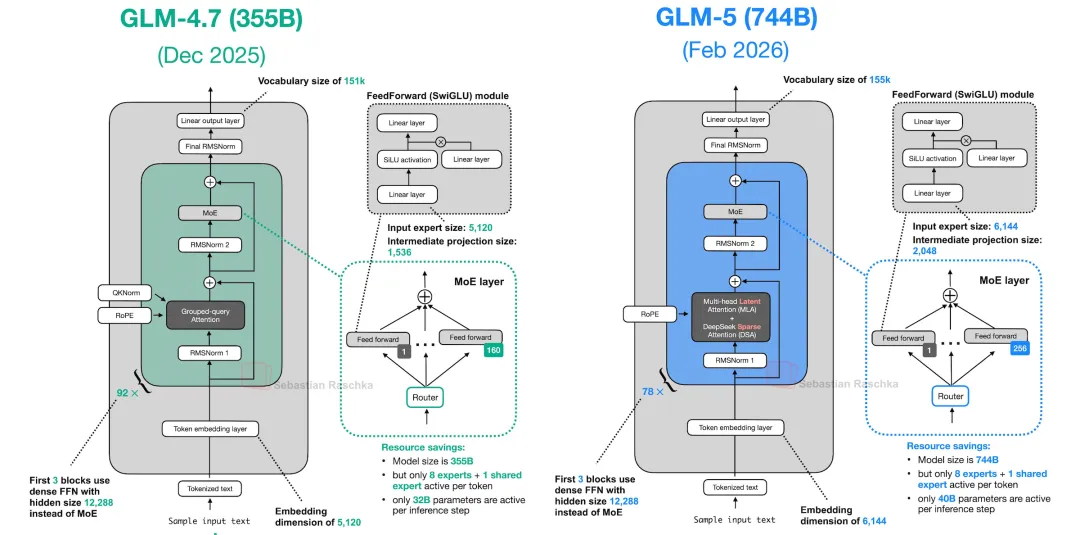
图的作者rasbt@x
如果说以前各家模型还在架构的黑暗森林里各自探索,那么 GLM-5 的出现释放了一个强烈信号:大模型架构设计的探索期,可能已经结束了。 直接说结论:在架构层面,GLM-5 几乎就是微调版的 DeepSeek-V3。这并非贬义,而是标志着行业共识的达成。我们可以从以下几个核心维度,看看这次“大换血”背后的技术细节。
Attention:全面拥抱 MLA
从 GLM-4.7 到 GLM-5,最大的变化在于 Attention(注意力机制)。GLM-4.7 还在使用标准的 GQA(分组查询注意力),配置是 96 个 Query 头配合 8 个 KV 头。而在 GLM-5 中,这套方案被彻底推倒,取而代之的是 DeepSeek 招牌式的 MLA(Multi-head Latent Attention)。
其核心逻辑与 DeepSeek-V3 如出一辙:
-
Query 投影: 走 LoRA 风格的两阶段投影(先降维到 Rank 2048,再扩展到多头); -
KV 压缩: Key 和 Value 联合压缩进一个低秩瓶颈(Latent),再分裂为两路(KV 路径 + RoPE 路径)。
这不仅是思路上的借鉴,连实现细节都高度一致。GLM-5 仅仅是调整了几个超参数(如 q_lora_rank 设为 2048,v_head_dim 设为 256),但其底层的“KV 压缩”与“去偏置(Bias-free)”设计与 V3 完全相同。甚至连 Bias 都去掉了。 在 GLM-5 的所有投影层中,attention_bias 默认设为 False。放眼 2025 年发布的主流模型,除了 GPT-oss 还在坚持使用 bias,其他玩家都已经达成了“去偏置”的共识。
此外,GLM-5 唯一明确高亮提及的架构特性,是采用了 DeepSeek V3.2 的原生DSA(稀疏注意力),通过专门的索引器在每步只选取 top-2048 个相关 token,而非全量扫描。
MoE 路由:相同的配方,不同的“减法”
在混合专家(MoE)的设计上,GLM-5 同样拿到了那份“标准配方”:
-
专家数量: 256 个路由专家 + 1 个共享专家(Shared Expert)。这与 DeepSeek-V3 完全一致,而 GLM-4.7 只有 128 个。目前只有 Qwen-3 激进地去掉了共享专家,其他家基本都保留了。 -
路由机制: 每个 Token 选 Top-8 专家;使用 Sigmoid 路由(而非 Softmax);引入 bias 修正负载均衡,完全放弃了辅助损失(Aux Loss)。 -
参数细节: 路由缩放因子为 2.5,专家中间层维度 2048 —— 这些数字与 DeepSeek-V3 分毫不差。
但 GLM-5 做了一个有趣的简化:DeepSeek-V3 采用了“分组路由”(Grouped Routing),先选组,再选专家。而 GLM-5 放弃了分组,直接在 256 个专家中进行扁平化的 Top-8 选择。这延续了 GLM-4.7 的设计思路。这也侧面说明,DeepSeek 那个复杂的分组路由机制,可能并不是性能提升的必要条件,简单的扁平路由依然能打。
骨架与训练:MTP 已成标配
在整体骨架上,GLM-5 堆到了 78 层 transformer(比 V3 更深),上下文窗口干到了 202k。值得注意的是 FFN(前馈网络)的排布:
-
全员 SwiGLU: 没有任何 Bias。 -
Dense-then-MoE: 前 3 层是标准 Dense 层,后面 75 层全是 MoE。这种“起手几层 Dense,后面全 MoE”的混合模式,也是 DeepSeek-V3 的典型特征。
最后,关于 MTP(多 Token 预测)。 DeepSeek-V3 带火了 MTP 训练(即一次预测未来多个 Token,提升表征质量,推理时丢弃额外 Head)。 GLM-5 的 Checkpoint 中包含了第 79 层(model.layers.78)的权重,但在加载时被代码显式跳过。这正是典型的 MTP 训练痕迹 —— 训练用的辅助头,发布时留着权重,推理时不用。
结语:架构战争的终结
看到这里,你可能会觉得 GLM-5 “致敬”得有点多。它换掉了自己的 Attention 机制(GQA -> MLA),引入了 DSA,采用了 Sigmoid 路由、无 Aux Loss、256+1 专家结构,甚至连缩放因子和 MTP 策略都一一对齐。除了保留“扁平路由”这一独苗外,GLM-5 的架构几乎就是 DeepSeek-V3 的翻版。
当一家顶尖的大模型实验室,愿意放弃自己延续数代的架构惯性,转而采用竞争对手的蓝图,并精确对齐关键参数时,这意味着:大模型架构的设计空间可能已经被充分探索,并收敛出了最优解。
MLA + Sigmoid MoE + Shared Expert + No Aux Loss + MTP,这套组合拳可能已经成为了当前版本的“标准答案”。
对于行业而言,Transformer Block 的架构红利已近尾声。接下来的差异化竞争,将不再是“谁的积木搭得更花哨”,而是回归到更本质的维度:数据清洗的质量、训练配方的调优,以及推理基础设施的效率。
架构已定,剩下的就是拼内功了。
Appendix
GLM-5大模型架构源代码见: https://github.com/huggingface/transformers/blob/main/src/transformers/models/glm_moe_dsa/modeling_glm_moe_dsa.py
