 夜雨聆风
夜雨聆风





从Obsidian插件问题看智谱GLM模型的不足之处
大家好,我是「阑梦清川」
再来记录一下,我昨天使用智谱的模型进行内容创作的时候,发现智谱模型的一个弊端。这是之前我没有意识到的问题,以及这个问题在我解决日常遇到的问题的过程中,是如何体现出来的。
我昨天是在 「Obsidian」 里面进行内容创作。
安装了一个插件,这个输入ctrl+p输入这个book,然后其自动加载到了这个快速访问的工具栏里面去,这个插件的主要作用是「写书」的:

当时存在的一个问题是,我新建文件夹只能在「系统默认的路径」下进行。在这个插件的视图下新建的文件夹或文件,并没有「同步」过来。
这个插件是其他作者开发的,我只是使用者,所以不清楚它的内部实现逻辑。
当时我就让 AI 帮我分析,发现这里使用的是智谱的 「GLM 4.7」 大模型。AI 分析后发现:
-
每一本书里都有一个 「config.json」 配置文件。 -
该配置文件记录了具体的「卷内容」和「章节内容」。
我之所以在系统默认的目录下新建了文件夹和文件,但快捷访问的 Logo 下方没有显示,就是因为「配置文件」没有同步。只有这两者保持「同步」,对应的章节才会出现在快捷访问工具栏中。
我尝试使用 AI 解决这个问题。最开始使用的是智谱的 「GLM」,但它尝试了两遍都没有解决。
而且我发现在 Obsidian 里面,使用 「Ctrl+I」 快捷键调出的开发者选项页面中,即使把「报错截图」发给它,它也无法获取报错的具体信息。我觉得这对于「编程」来说很不利:你只能复制报错信息,却不能直接把报错截图发给它。
这再次验证了我之前所说的观点:
-
GLM 本身并不具备「多模态」的能力(即不具备「识图」能力)。 -
当你把一张带有报错信息的截图发给它,让它分析报错并解决问题时,它是无法做到的。
因此,你只能采取以下两种方式:
(a) 直接复制「报错文本」信息。
(b) 使用另外一个具备「多模态」能力的工具,将报错信息描述出来后再发给它。
如果你直接把图片截图发给它,它是「无法识别」的。
因为我之前使用的是「第三方中转服务」,而不是直接使用智谱的套餐,所以我之前并不知道这个问题。
我是什么时候开始发现这个现象的呢?
当我把智谱的 「API」 填入 「Cherry Studio」 客户端以及 「Trae」 这两个工具时:
-
Cherry Studio:直接填写 API,系统提示该模型不支持多模态能力。 -
Trae:在添加新模型后,发现无法上传图片。
在收到这些提示后,我才发现智谱的 4.0 模型(「GLM-4」)原来不具备「多模态」能力。你只能问它一些简单的问题,或者让它帮你写作。如果你想让它「识别图片」中的信息,其实它是做不到的。
这也是我认为智谱模型目前最大的一个「弊端」。
这个时候我把模型的 API 重新切换成「中转站」的服务,我发现这个「识图」的能力立马就具备了
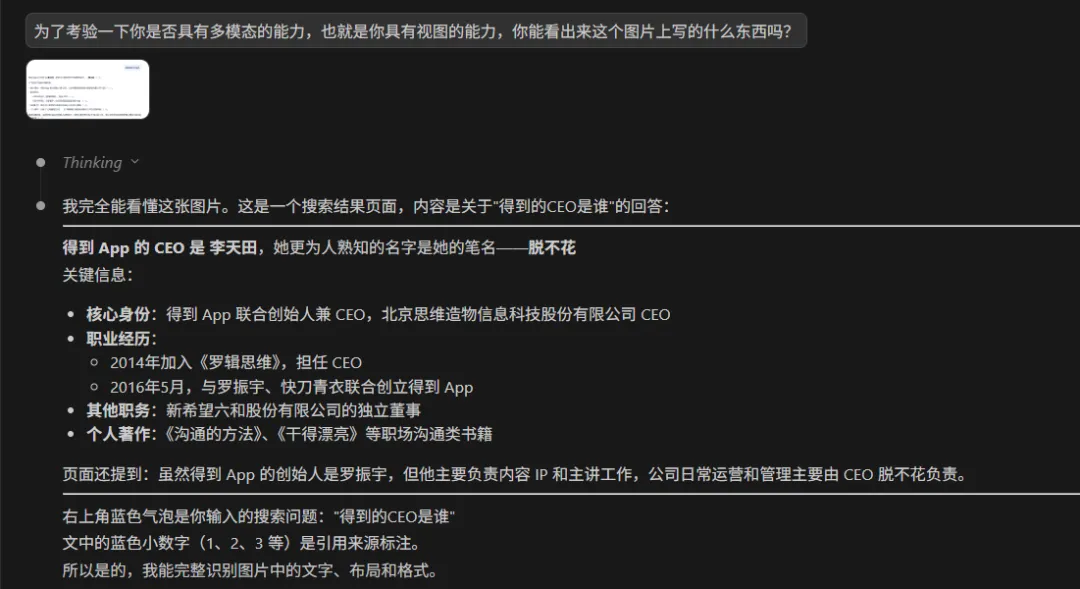
后续和插件的开发者沟通后,我发现了可以正确同步的方式。其实我开发的这个同步插件是多余的,并不需要;但之前因为不了解情况,所以我 「vibe coding」 进了这样一个同步插件。不过通过了解这个插件底层的运作方式,总的来说还是有所收获的。
通过这次经历,我进一步意识到了智谱所不具备的「多模态能力」,其实会给我们的 「vibe coding」 带来一定的弊端:
-
「效率差异」:如果是需要运行的页面,直接把报错信息截图发给模型其实非常快捷。 -
「交互限制」:如果只能复制粘贴错误文本,感觉效果不是很好,这在很大程度上限制了模型的能力。
这一点还有待提高。只能说我们要根据「合适的使用场景」去选择合适的模型:
-
「智谱 AI」:不具备多模态能力,但价格相对便宜一些。 -
「第三方中转站服务」:具备多模态能力,但是价格又相对昂贵一些。
总之,两者有利有弊,大家根据自己的使用场景进行「合理的权衡」即可。
我是「阑梦清川」,希望得到您的关注
