夜雨聆风
夜雨聆风





QRRanker:用注意力对候选文档快速打分
一、动机
在 RAG(检索增强生成)系统中,”找对文档”是一切的基础。目前的检索流程通常分两步走:先用 Embedding 模型做粗筛(召回),再用 Reranker 做精排(重排序)。这个两步走的流程本身没问题,但每一步都有各自的烦恼
困境一:Embedding 模型的”几何瓶颈”
Embedding 模型会把 query 和文档各自压缩成固定维度的向量,然后用余弦相似度来比较。这就好比给每个人拍一张证件照,然后用照片来判断两个人是否合得来——信息损失太大了。
有理论研究证明,固定维度的向量根本无法编码查询和文档之间复杂的交互关系。更麻烦的是,相似度度量的归纳偏置限制了它只能捕捉”像不像”的关系,而现实中我们还需要判断因果、联想、类比等更复杂的关系。
困境二:Pointwise Reranker 的”一叶障目”
为了弥补 Embedding 模型的不足,Pointwise Reranker(如 Qwen-Reranker)会对每对 query-document 做交叉注意力编码,给出一个相关性分数。这种方式虽然比 Embedding 更精确,但有一个天然缺陷:它每次只看一个文档,看不到全局
就像一个考试阅卷老师,Pointwise 逐份批改试卷,但不能同时看几份试卷来比较——这就很难判断 A 的答案是”还行”还是”已经是最好的了”
困境三:Listwise Reranker 的”笨嘴拙舌”
基于 LLM 的 Listwise Reranker(如 GroupRank、RankZephyr)把候选文档拼在一起,让大模型输出排序结果。但问题在于:LLM 的自回归文本生成天生不擅长输出精确数值
有研究表明,LLM 输出的浮点数并不能准确反映模型的“信心”。对此,一般退而求其次采用 5/10 分制(Likert 量表)来代替精确数值。但这又带来了更多格式限制
破局思路
之前的研究(Retrieval Heads、QR Heads)发现,当你把查询和多个文档一起喂给 LLM 时,某些注意力头会自动把注意力集中到与查询相关的文档上——这些头的注意力权重分布,天然就是一种相关性排名
准确识别检索头,提高大模型长上下文能力
QRRanker 的想法非常直接:既然这些注意力头已经有检索能力了,为什么不专门训练它们,让它们排得更准? 这样一来:
- 全局视野:所有候选文档在前向传播中被同时编码,天然能看到全局信息
- 连续分数:注意力分数本身就是连续的实数值,不需要 Likert 量表的折中
- 无需生成:不需要逐个 token 地生成,速度更快
- 训练数据友好:不存在特别的格式限制
二、技术实现:如何训练注意力头来做排序
2.1 识别 QR Head
-
把查询 Q 和上下文 C(包含相关文档和干扰文档)拼在一起输入模型 -
查看每个注意力头在编码 Q 时,注意力权重是否集中在了相关文档上 -
用 QR Score量化这种集中程度——分数越高,说明该头越像一个”检索器”

简单来说,对于一个注意力头 h,它的 QRscore 就是查询 Q 的所有 token 对正确文档所有 token 的注意力权重之和
作者最终在 Qwen3-4B 模型上,用 NarrativeQA 的 1000 个样本计算了所有注意力头的 QR Score,选出了得分最高的 16 个头作为 QR Heads
2.2 训练数据构造
第一步:准备正样本。 基于 MuSiQue(维基百科多跳 QA)和 NarrativeQA(长篇小说 QA)构造训练集。MuSiQue 带有 Golden Evidence 标注,可以直接作为正样本;NarrativeQA 则基于 “Silver Evidence 方法”(query增强、多次检索、投票、LLM精筛),构造不完美但能用的相关性标注
MiA-RAG:基于分层摘要构建一个覆盖全文的全局语义“mindscape(心境图景)”,再用它同时指导检索与生成
第二步:构造 Listwise 训练样本。 对每个问题,用 Qwen3-Embedding-8B 检索 top-50 候选文档。在这 50 个文档中,与预先构造的证据匹配的标记为正样本,其余为负样本
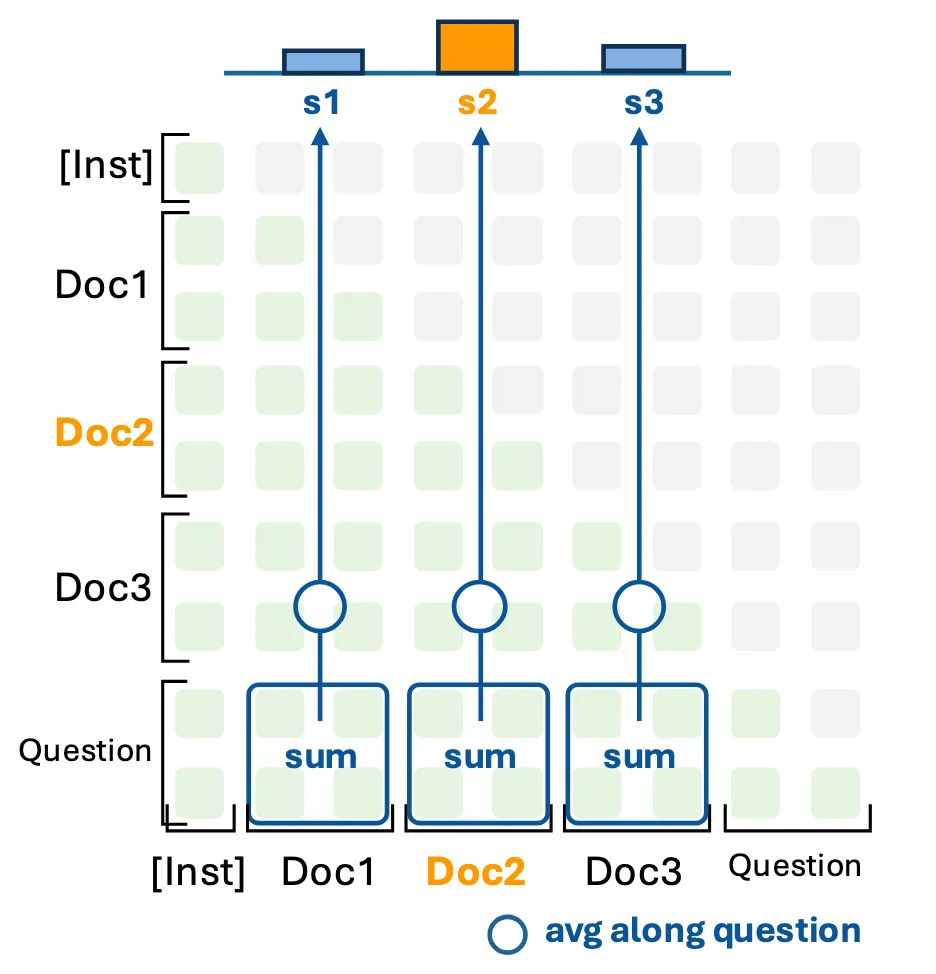
第三步(可选):加入摘要前缀。 为了帮助模型理解长文本的全局脉络,论文还提出了可选的”记忆增强”:在候选文档列表前面加上一段摘要作为上下文。针对不同场景设计了两种摘要:
- 分块摘要:每 20 个连续片段生成一个摘要(长篇小说)
- 事件摘要:从对话中提取结构化事件(对话场景)
2.3 训练流程
-
将查询 Q 和 50 个候选文档 C 拼成一个 prompt,输入模型做前向传播 -
从 16 个 QR Head 中提取查询对每个文档的注意力分数 -
将 16 个头的分数求和,得到每个文档的最终检索分数 -
用对比损失优化这些分数
其中有两个值得注意的技术细节:
Max-Min 归一化:不同样本的注意力分数波动很大,主要挑战是 attention sink(注意力汇聚),即某些位置的 token(尤其是序列开头的 BOS token、标点符号等)会异常地吸引大量注意力权重,即使这些 token 本身并不包含重要的语义信息。对此,论文通过 max-min 归一化,把分数线性映射到 [0, 8]
分组对比损失:传统对比损失每次只处理一个正样本,但 top-50 中可能有多个正样本。对此,论文提出了分组版本的对比损失,把所有正样本都纳入考虑:对每个正样本分别计算损失再取平均
2.4 推理过程
-
把查询和候选文档拼好,输入模型 -
只做 prefill,不做任何生成 -
从 QR Head 的注意力矩阵中提取分数 -
按分数排序
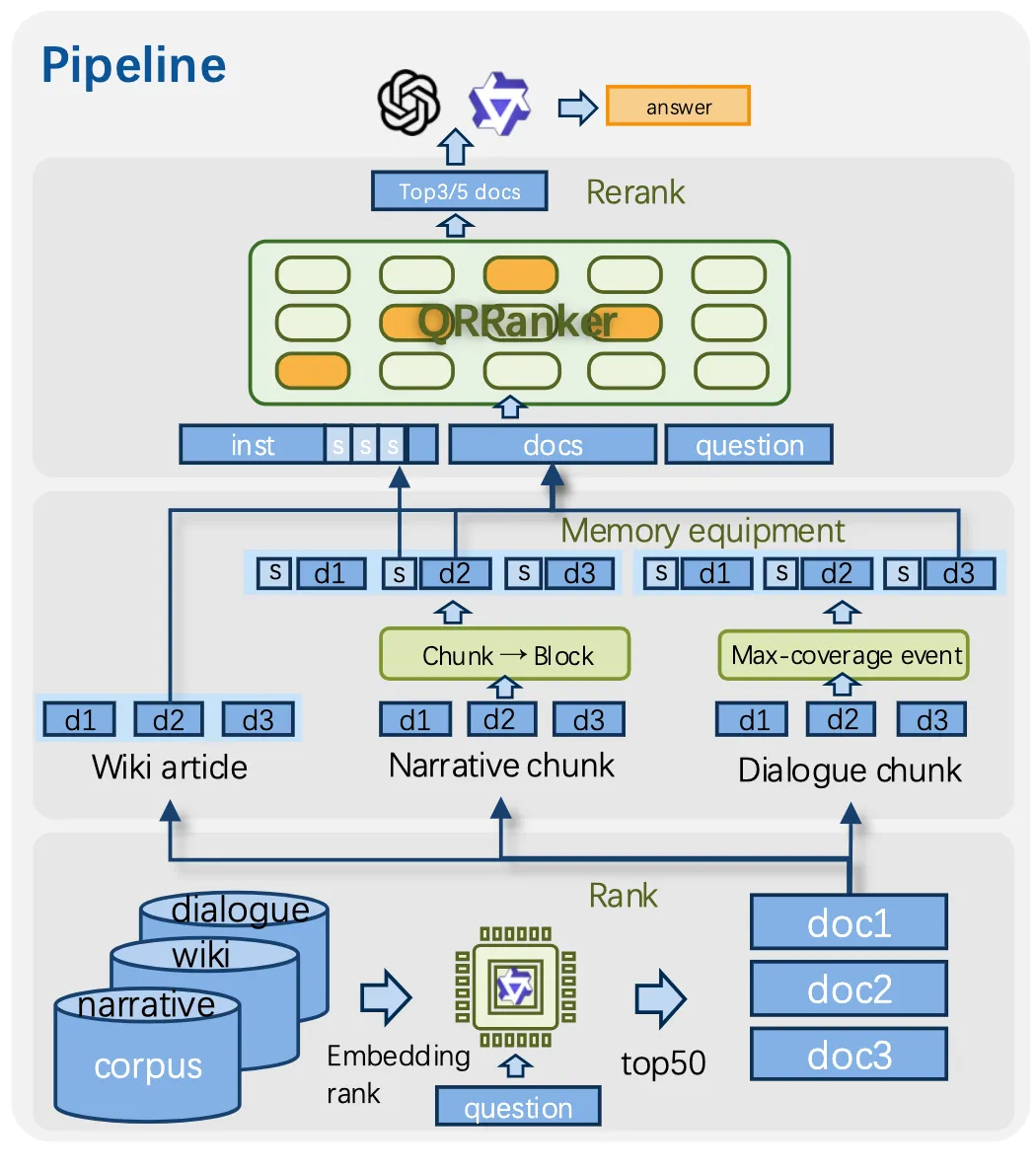
三、实验结果
3.1 重排序性能
论文在五个数据集上进行了评测,覆盖三大场景:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
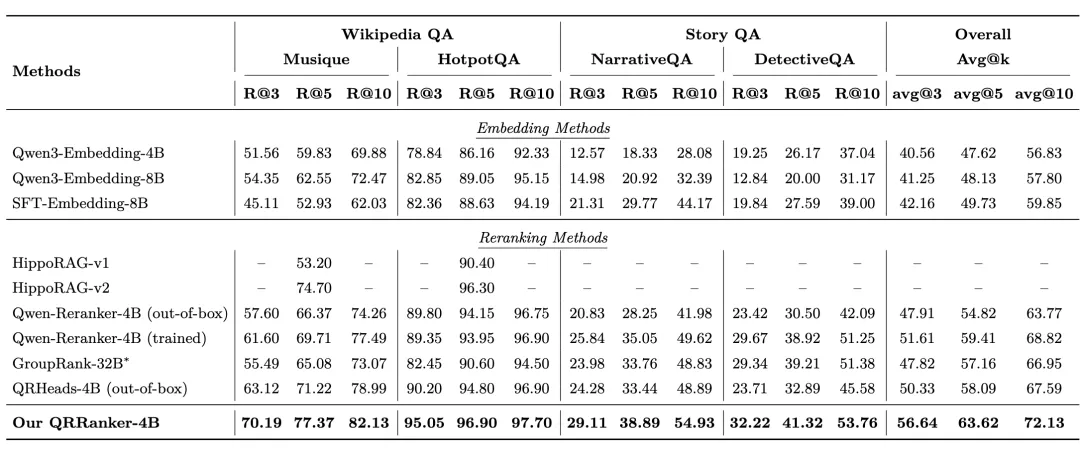
核心结果:
- QRRanker-4B 全面超越 GroupRank-32B
一个 4B 的模型打赢了 32B 的模型,体积只有对方的八分之一。在整体平均 Recall@10 上,QRRanker 达到 72.13,而 GroupRank 只有 66.95。 - 显著优于同规模的 Qwen-Reranker-4B
即使是用相同数据训练过的 Qwen-Reranker,平均 Recall@10 也只有 68.82,比 QRRanker 低了 3.3 个百分点。 - 超越图方法 HippoRAG-v2
在 HippoRAG 精心设计的维基百科 QA 任务上,QRRanker 的 MuSiQue Recall@5 达到 77.37,远超 HippoRAG-v2 的 74.70。
3.2 下游 QA 任务表现
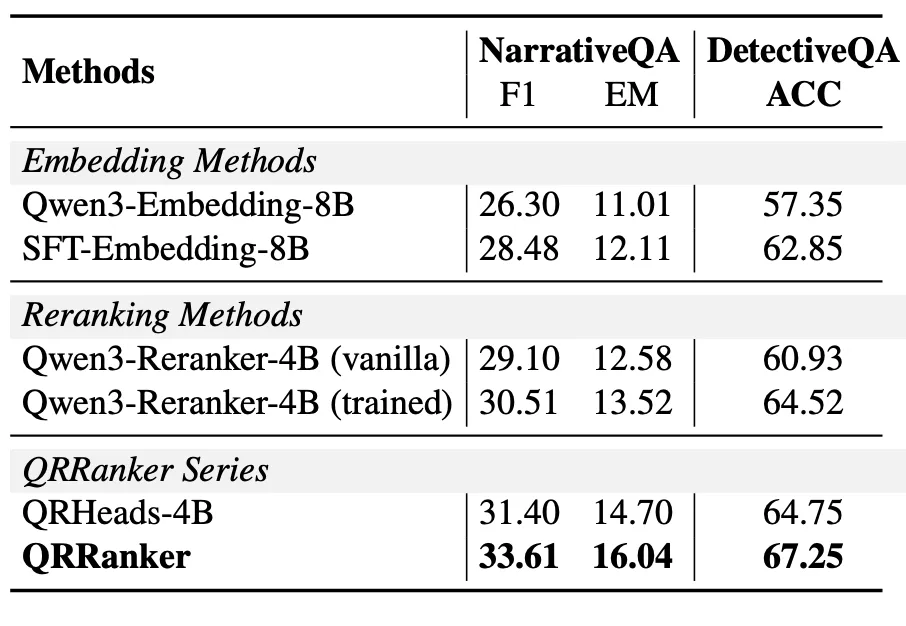
-
NarrativeQA 上,QRRanker 达到 33.61 F1(vs 训练版 Qwen-Reranker 的 30.51) -
DetectiveQA 上,准确率从 Embedding 的 62.85 提升到 67.25
3.3 对话记忆任务的惊艳表现
在 LoCoMo 基准上,QRRanker 的结果尤其令人印象深刻:
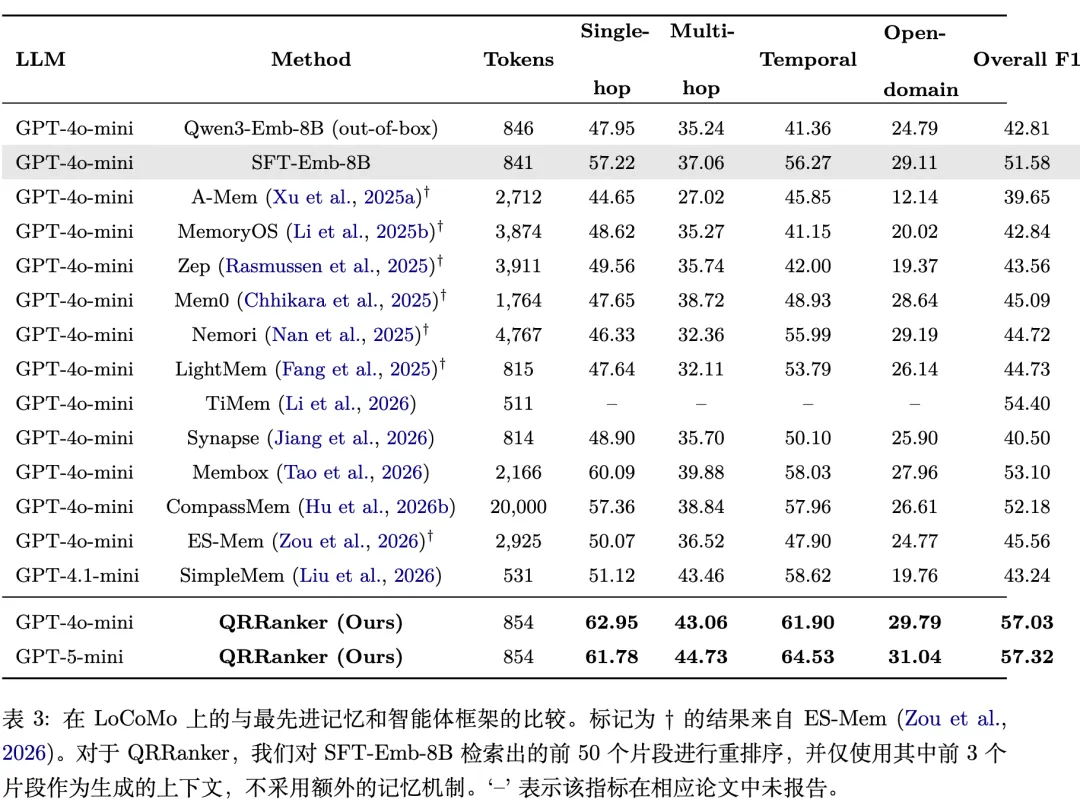
3.4 摘要前缀的效果
-
对长篇叙事和对话场景有稳定提升(DetectiveQA +2.67, NarrativeQA +1.02, LoCoMo +0.70) -
对维基百科 QA 基本无效甚至略有下降(HotpotQA -0.30, MuSiQue -0.03)
这很好理解:长篇叙事需要全局的故事脉络来辅助理解,而维基百科的证据通常很局部、很明确,全局摘要反而可能引入噪音。
3.5 中间层头的潜力
一个非常有趣的发现:用中间层(17-24 层)的注意力头来训练,性能几乎不下降。
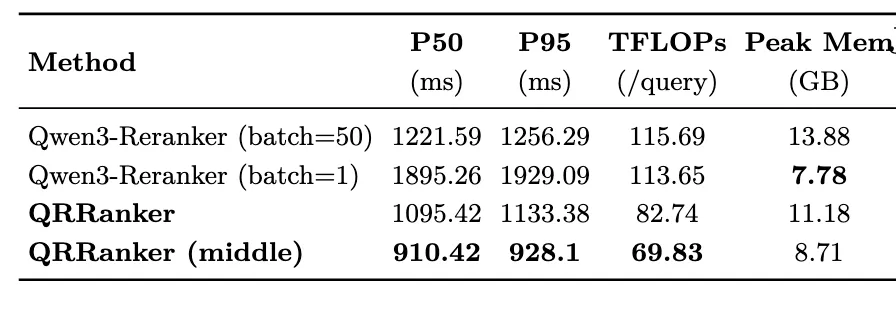
这意味着可以在推理时直接砍掉第 24 层以上的所有层,得到一个更小更快的模型。实际测试中,这种”中间层截断”版本的 QRRanker:
-
P50 延迟从 1095ms 降到 910ms -
计算量从 82.74 TFLOPs 降到 69.83 TFLOPs -
显存从 11.18GB 降到 8.71GB
而且性能几乎没有损失。更令人惊讶的是,中间层选出的头和预计算的 QR Head 重合度很低——说明 QR 训练确实激活了那些原本潜力未被发挥的头,这些头并不是天生的检索者,但在训练后学会了检索
3.6 推理效率
与 Qwen-Reranker-4B 相比,QRRanker 在各项效率指标上都更优: