 夜雨聆风
夜雨聆风





轻量索引,深度推理:针对视觉密集型文档问答的延迟视觉摄取技术
Index Light, Reason Deep: Deferred Visual Ingestion for Visual-Dense Document Question Answering
Authors: Tao Xu
Deep-Dive Summary:
摘要 (Abstract)
现有的多模态文档问答方法普遍采用“供应端摄取”策略:在索引阶段对每一页运行愿景-语言模型(VLM)以生成详细描述,然后通过文本检索回答问题。然而,这种“预摄取”方法成本极高(113 页的工程图纸包约需 80,000 个 VLM token),端到端可靠性低(VLM 输出可能因检索基础设施的格式不匹配而无法被正确检索),且一旦失败便无法补救。
本文提出了延迟视觉摄取(Deferred Visual Ingestion, DVI)框架,采用“需求端摄取”策略:索引阶段仅执行轻量级元数据提取,将视觉理解推迟到用户提出特定问题的时刻。DVI 的核心原则是“索引为了定位,而非理解”——通过结构化元数据索引和 BM25 全文搜索实现页面定位,然后将原始图像连同特定问题发送给 VLM 进行针对性分析。
在两个真实工业工程图纸(113 页和 7 页)上的实验表明,DVI 在 VLM 摄取成本为零的情况下实现了相当的整体准确率(46.7% vs. 48.9%),在视觉必要性查询上的有效率达到 50%(预摄取为 0%),并实现了 100% 的页面定位(搜索空间压缩 98%)。DVI 还支持交互式改进和渐进式缓存,将“问答准确性”问题转化为“页面定位”问题——一旦找到正确的图纸页,获取答案就变成了交互轮次的问题。
关键词: 延迟视觉摄取;需求端摄取;多模态文档问答;检索增强生成;工程图纸;页面定位;渐进式缓存;零视觉模型索引
1. 引言 (Introduction)
1.1 背景与动机
视觉密集型文档(如工程图纸、电气原理图、建筑蓝图)是工业领域的核心知识载体。将检索增强生成(RAG)应用于此类文档面临三重挑战:(1) OCR 对图纸几乎无效——符号、接线和标注在页面上高度交织;(2) VLM 预摄取成本高昂——对 113 页文档运行 VLM 生成描述需要约 80,000 token 和 13 分钟;(3) 预摄取在端到端上不可靠——即使描述捕捉到了信息,格式不匹配也可能导致检索失败,且系统在查询时无法回溯原始图像。
1.2 核心思想
DVI 提出了“延迟视觉摄取”——索引时仅构建轻量级的页面定位能力(零 VLM 调用),将视觉理解推迟到查询时。这类似于计算机科学中的“惰性求值”:仅在需要时进行计算,并将结果缓存以备复用。其设计原则是“索引为了定位,而非理解”,旨在将搜索空间缩小 98% 后,再由 VLM 进行针对性分析。
1.3 主要贡献
-
提出 DVI 框架:索引阶段零 VLM 调用,显著降低成本。 -
轻量级级联检索索引:四层结构化元数据结合 BM25,实现 100% 页面定位。 -
置信度路由机制:将约 60% 的查询路由至纯索引路径,节省 58% 的 VLM 调用。 -
渐进式缓存:自动缓存 VLM 分析结果,后续类似查询零成本。 -
构建工业对比实验框架:在真实工程图纸上验证了成本、准确率和定位率。 -
展示交互式改进价值:将问答问题转化为页面定位问题。
2. 相关工作 (Related Work)
本节回顾了 RAG 与文档理解、视觉文档检索(如 ColPali)、查询时视觉推理(如 VisRAG)、OCR 噪声问题、工程文档分析以及查询路由。DVI 的核心创新在于摄取和索引阶段的零 VLM 调用,并证明了无需重量级索引也能实现高效的多模态文档问答。
3. 方法:延迟视觉摄取框架 (Method: The DVI Framework)
3.1 框架概述
DVI 将文档问答分解为两个阶段:渐进式轻量索引和带视觉推理的智能查询路由。
-
阶段 1(摄取与索引):轻量级解析 PDF,分类页面(文本或图纸),提取结构化文本和表格,构建四层索引和 BM25 引擎。全程为纯 CPU 计算,零 VLM 调用。 -
阶段 2(查询与推理):查询分类器将问题分为 9 类并提取实体。基于置信度的路由器选择检索策略:高置信度直接返回文本答案;必要时将定位的原始图像发给 VLM;否则回退至 BM25。
图 1 展示了 DVI 框架的总体架构:
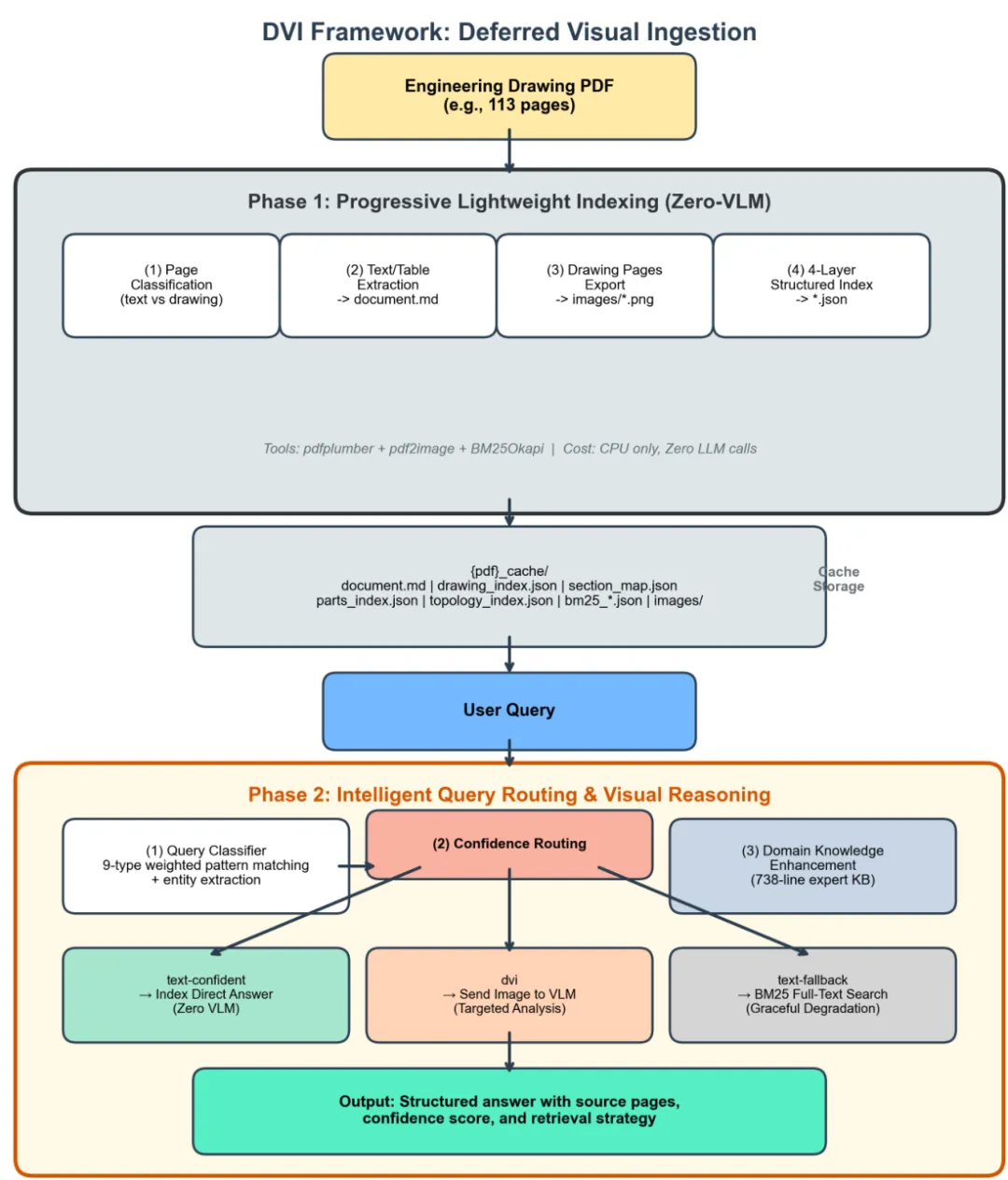
3.2 阶段 1:渐进式轻量索引
该阶段采用纯规则流水线。
3.2.1 文档解析
根据文本密度对页面分类。文本页进行结构化提取,图纸页导出为原始图像,不进行任何预处理。
3.2.2 四层结构化元数据索引
针对工程图纸的层级结构构建索引:
-
L1(图号索引):通过图号定位。 -
L2(拓扑索引):通过功能单元查找。 -
L3(零件索引):精确到组件级的查询(如零件编号)。 -
L4(辅助索引):通过交叉验证补偿信息缺失。
3.2.3 BM25 全文搜索引擎
作为回退方案,提供语义级的检索能力。
3.2.4 复杂度分析
时间复杂度为 。在 D1 数据集上,索引构建仅需不到 10 秒(不含图像导出时间)。
3.3 阶段 2:智能查询路由与视觉推理
3.3.1 查询分类与实体提取
分类器将问题归为 9 类(见下表),并提取关键实体。约 60% 的查询可通过纯索引路径(零 VLM)解决。
|
|
|
|
|---|---|---|
| 零件编号 |
|
|
| 接线查询 |
|
|
| 布局查询 |
|
|
|
|
|
|
3.3.2 级联检索链
DVI 在四层索引和 BM25 之间执行级联检索(见图 2)。如果高层索引命中则直接返回,否则逐层回退,必要时触发 VLM。
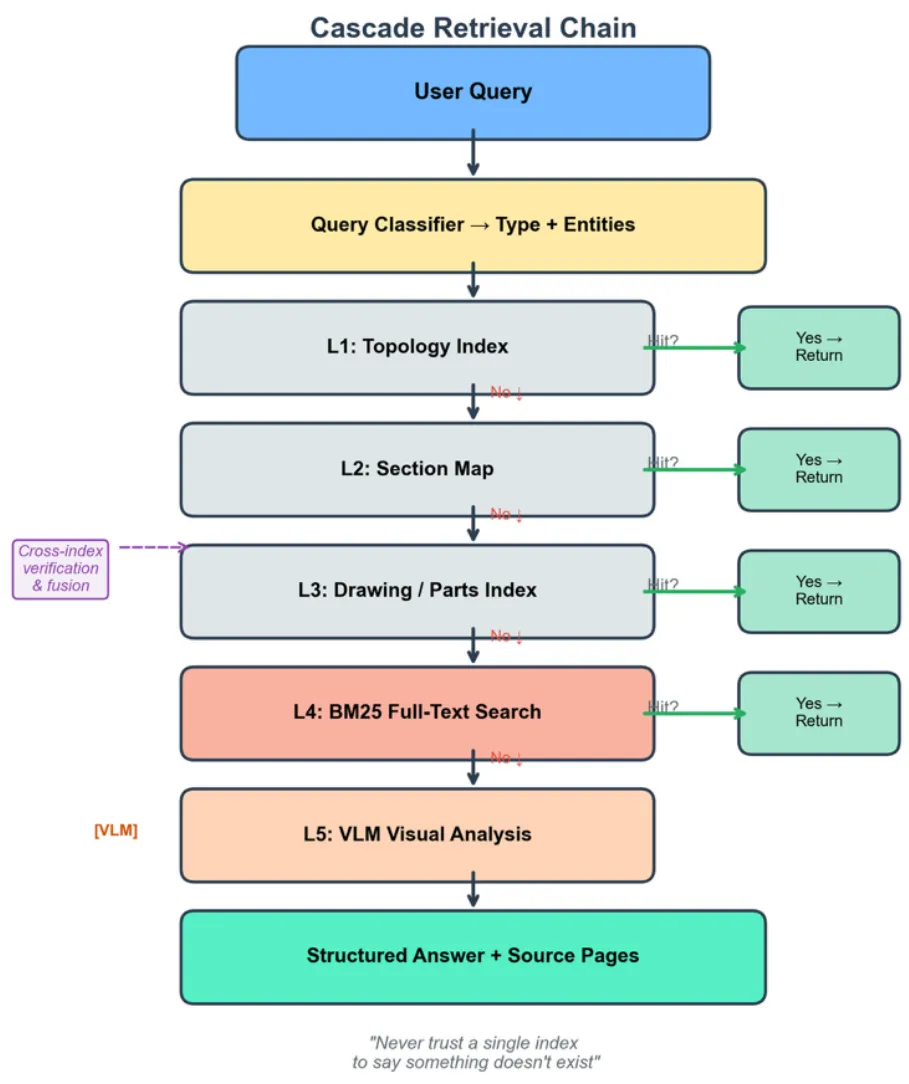
3.4 领域知识增强层
通过结构化提示词注入(Prompt Injection)引入工业领域专家知识(如 NEMA/IEC 标准),提升 VLM 在特定场景下的推理能力。
3.5 理论分析:DVI 与预摄取的六维对比
3.5.1 摄取成本
预摄取在 D1 数据集消耗 80,830 个 VLM token;DVI 为零,降低了 100%。
3.5.2 摄取时间
预摄取受限于 VLM API 延迟(D1 需 13.5 分钟);DVI 仅需约 5 分钟,提速 。
3.5.3 页面定位能力
预摄取结果通常为文本片段,缺乏页面概念。DVI 实现了 100% 的页面定位成功率,将 113 页搜索空间压缩至 2-3 页(压缩率 98%)。
3.5.4 首检准确率
DVI 的首检准确率与预摄取相当,但成本显著降低,且支持通过交互式改进和渐进式缓存进一步提升。
Original Abstract: Existing multimodal document question answering methods universally adopt a supply-side ingestion strategy: running a Vision-Language Model (VLM) on every page during indexing to generate comprehensive descriptions, then answering questions through text retrieval. However, this “pre-ingestion” approach is costly (a 113-page engineering drawing package requires approximately 80,000 VLM tokens), end-to-end unreliable (VLM outputs may fail to be correctly retrieved due to format mismatches in the retrieval infrastructure), and irrecoverable once it fails. This paper proposes the Deferred Visual Ingestion (DVI) framework, adopting a demand-side ingestion strategy: the indexing phase performs only lightweight metadata extraction, deferring visual understanding to the moment users pose specific questions. DVI’s core principle is “Index for locating, not understanding”–achieving page localization through structured metadata indexes and BM25 full-text search, then sending original images along with specific questions to a VLM for targeted analysis. Experiments on two real industrial engineering drawings (113 pages + 7 pages) demonstrate that DVI achieves comparable overall accuracy at zero ingestion VLM cost (46.7% vs. 48.9%), an effectiveness rate of 50% on visually necessary queries (vs. 0% for pre-ingestion), and 100% page localization (98% search space compression). DVI also supports interactive refinement and progressive caching, transforming the “QA accuracy” problem into a “page localization” problem–once the correct drawing page is found, obtaining the answer becomes a matter of interaction rounds.
PDF Link:2602.14162v1
