 夜雨聆风
夜雨聆风





当AI一小时能造个App,应用商店就成了古董店
一、跑分这件事,和考试一样,认真你就输了
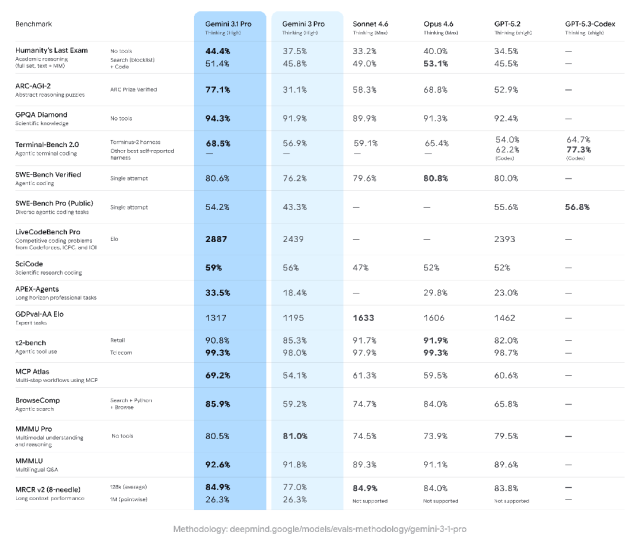
今天凌晨,Google发了Gemini 3.1 Pro。
按版本号的行业惯例,0.1的升级,一般是修修补补、打打补丁。就像你手机系统从16.3升到16.4,换了个壁纸加了个emoji,你甚至感觉不到区别。
但这次Google显然没按常理出牌。
ARC-AGI-2跑分从31.1%直接干到77.1%,翻了一倍多。
什么概念呢?就好比你高考模拟从专科线一路冲到清北线,老师都以为你偷看答案了。
Anthropic的Opus 4.6拿了68.8%,OpenAI的GPT-5.2是52.9%。
于是你就看到了一个经典的科技圈景观:
Google在官方博客里一脸无辜地摆出一堆柱状图,柱子的颜色搭配恰到好处地让自家那根最醒目,然后用一种”我也很意外”的语气说——哎呀,我们也没想到进步这么大。
这表演,我给满分。
但跑分这件事,和考试一样,得看你怎么解读。
你见过太多高考状元出了校门泯然众人,也见过中等生后来居上把日子过得有滋有味。
AI模型的基准测试本质上就是一场标准化考试——题是别人出的,场景是限定的,答案是唯一的。
真正决定一个模型值不值钱的,从来不是它在考场里考了多少分,而是它走出考场之后,能不能帮你把活儿干了。
所以我对跑分的态度一直很简单:
看看就得了,别太当真,更别用跑分表去指导你的技术选型。
那和用高考分数选对象,没什么本质区别。
二、Google这次的节奏感,有点东西
发布时间选在全球AI峰会之后。
三巨头刚在台前展示完微妙的默契与距离,观众还没散场呢,Google直接上硬菜。
别跟我玩社交,我跟你玩产品。
而且这次更聪明的地方在于,3.1 Pro发的是预览版。
预览版三个字的含义是:这还不是我的全力,后面还有正式版。
这招在行业竞争中非常好用。
打赢了,说”你看我预览版就这么强”。
打输了某些单项,说”毕竟只是预览版嘛”。
进可攻退可守,怎么都不亏。
做产品做到这个份上,属于把竞争当高考填志愿——冲稳保全安排明白了。
三、真正值得聊的不是Gemini,是Karpathy那条推文
说实话,Gemini 3.1 Pro发布这件事,放在2026年的AI行业里,已经不算什么炸裂新闻了。
大家每隔两周就要被一个”最强模型”轰炸一次,审美疲劳了。
但Karpathy同一时间发的那条推文,含金量比模型发布本身高得多。
他说:我想用8周把静息心率从50降到45,需要追踪跑步机数据。于是花1小时用AI辅助编程做了一个专属仪表盘。两年前这事得花10小时,现在1小时。
但他真正在意的是:这本来应该只花1分钟。
这句话的潜台词是——
现在之所以还需要1小时,不是AI不够强,是这个世界的基础设施还没为AI做好准备。
跑步机本质上就是个传感器,它的核心价值是数据。
但你想拿到这些数据,还得让AI去逆向它的接口,处理一堆公制英制混用的坑,对付日历格式对不上的问题。
为什么?
因为跑步机厂商的产品逻辑还停留在上一个时代——它默认使用者是人,所以给你做了一个漂亮的App和前端界面。
但现在的事实是:越来越多的使用者,是AI。
Karpathy说得很直白:99%的产品仍然没有AI原生的接口,还在维护给人看的界面,而不是提供便于智能体调用的通道。
翻译成大白话就是:
你们做产品的,还在给客人修大门呢,殊不知客人已经开始走后门了。
四、应用商店不是要死,是要变
Karpathy的结论更直接:应用商店模式正在过时。
300行代码、大模型几秒生成的专属工具,没必要变成一个正经App让你去搜索下载。
这话说得对不对?
对,但也没全对。
它对在哪?对在”标准化需求”正在被AI消解。
以前你想记账,得去应用商店搜一个记账App,在十几个竞品里挑来挑去,下载安装注册登录,然后发现它的分类逻辑和你的消费习惯完全不匹配,又得将就着用。
现在呢?你跟AI说一句”帮我做个按我习惯分类的记账工具”,它十分钟给你搓一个。界面可能没那么精致,但胜在完全贴合你一个人的需求。
这就是定制化干掉标准化的经典路径。
它没全对的地方在哪?不是所有需求都能被300行代码覆盖。
社交网络、协同办公、复杂的企业管理——这些涉及多人协作、需要持续运维、有复杂权限体系的产品,不是一个大模型临时搓出来的小工具能替代的。
所以更准确的说法应该是:
应用商店不会消失,但会萎缩。大量”功能型”App会被AI即时生成的一次性工具替代,而真正有网络效应和生态壁垒的平台型产品,反而会活得更好。
打个比方,街边的打印店可能会因为家用打印机普及而减少,但你不会因为家里有台打印机就不去出版社了。
层次不同,逻辑也不同。
五、Demo很炸裂,但别被Demo骗了
这次Google展示的几个Demo确实能打。
用3.1 Pro做城市规划、从零生成可交互的界面;实时追踪国际空间站轨道的仪表盘;3D鸟群模拟还能用手势操控;把《呼啸山庄》的文学氛围转化成个人网站……
网友们也贡献了不少精彩案例,效果确实让人眼前一亮。
但我要说一句可能不那么好听的话:
Demo永远是Demo。
Demo的本质是什么?
是在最理想的条件下,展示产品最好的一面。它跟你相亲时对方精心修过的照片一个道理——你不能说它是假的,但你得知道,真实场景里会有色差。
一个Demo跑通了,不代表这件事可以稳定复现。
一个Demo效果炸裂,不代表普通用户照着同样的提示词能得到同样的结果。
我见过太多人被Demo种草,兴冲冲地去试,然后发现自己生成的东西和官方展示的差了十万八千里,最后得出”AI不行”的结论。
不是AI不行,是你对Demo的期望管理出了问题。
正确的态度是:Demo看个方向就行,别看完就觉得未来已来。未来确实在来的路上,但路上的坑,Demo不会提前告诉你。
六、这场技术角力,最终受益的是谁?
Google、OpenAI、Anthropic三家你追我赶,每隔几天就刷一次榜单,看起来卷得飞起。
但如果你把视角拉远一点,会发现一件有意思的事:
这三家卷的方向,已经在收敛了。
编程能力、科学知识、智能体能力、多模态理解——大家比的东西越来越像,分数差距越来越小。
3.1 Pro的SWE-Bench Verified是80.6%,Opus 4.6是80.8%,差0.2个百分点。这种差距放到工程实践中,基本可以忽略不计。
这意味着什么?
意味着在基础模型层面,差异化正在消失。
当三家模型的能力逐渐趋同,竞争的焦点就不再是”谁更聪明”,而是”谁更便宜、谁更稳定、谁的生态更好用”。
3.1 Pro跑完一整套测试花了约5700万tokens,成本不到Opus 4.6的一半。能打又省钱,这个组合确实有吸引力。
所以这场技术角力的终局,很可能不是某家遥遥领先,而是模型变成水电煤一样的基础设施——谁都差不多好用,选谁取决于价格和服务。
而真正赚到钱的人,是拿着这些”水电煤”去盖房子、做菜、开工厂的人。
换句话说——
在大模型技术比拼中围观打分的人,永远不如拿起模型去解决具体问题的人赚得多。
七、一个朴素的判断
把Jeff Dean的城市规划Demo和Karpathy的跑步仪表盘放在一起看,本质上是同一件事的两面。
一面是:AI已经能独立完成一整套专业工作流了。
另一面是:但周围的世界还没准备好迎接它。
传感器不开放接口,产品不支持AI调用,数据格式混乱,系统彼此封闭——AI的能力已经溢出来了,但周围的管道还是老的。
这种错配,就是接下来几年最大的机会。
谁能把”老管道”换成”AI原生管道”,谁就能吃到这波红利。
不是做模型的人吃,是做连接的人吃。
Karpathy那1小时里,最大的时间消耗不是AI写代码,而是让AI去适配一台跑步机的老旧接口。
所以最后一句话,送给所有还在围观的朋友:
别再纠结哪个模型跑分更高了。能跑的模型满大街都是,缺的是你知道拿它去跑什么。
全文完。觉得有点意思,转发比点赞更有用。
