当前时间: 2026-02-20 19:32:38
分类:软件教程
评论(0)
继续分享:神奇的豆包,PDF翻译神器
竖版的PDF日文文献,之前我一直用微信文字识别,再放到deepseek里翻译。微信文字识别还算准确,但问题是:竖版是从右到左排版,而文字识别默认是从左往右。
比如用微信文字识别是这样的:第一句成了最后一句——
比如用deepseek翻译的结果是这样的:要重新组织语序:
刚刚,就在刚刚,羽宝同学坐在我旁边喝茶,指点我说:你要不试试豆包?豆包可以上传附件,直接识别图片。
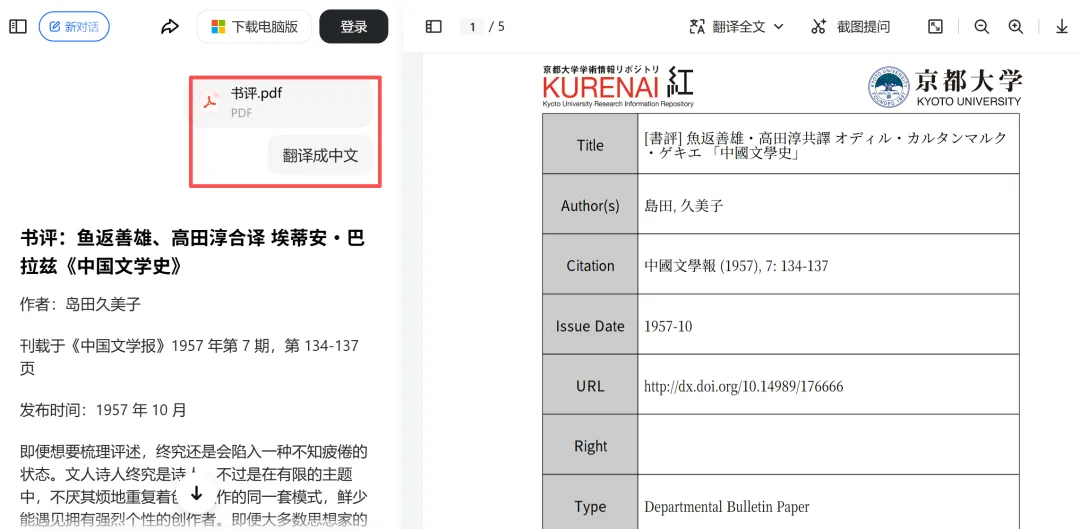
于是,我把文件保存为PDF文档(如果不能下载,用页面截图保存成图片也可),上传到豆包的附件,奇迹发生了——
不仅可以迅速识别整个文档,还可以根据指令翻译、提取主要内容。如果你不确定全文或者段落翻译是否准确,还可以轻松逐句翻译。
鼠标落在哪一行上,就会自动选定,然后就可以逐句翻译,精准校对。
真的是工欲善其事,必先利其器。可能好多人都已经会用了,不过对于我而言,这可真是一个事半功倍的好工具,更特别的是——这是羽宝同学教我的,新脑子就是好用一些。她还给我分享了其他工具,有机会再逐一试试。

本站文章均为手工撰写未经允许谢绝转载:
夜雨聆风 »
继续分享:神奇的豆包,PDF翻译神器
 夜雨聆风
夜雨聆风