 夜雨聆风
夜雨聆风





源码拆解|我把 nanobot 读了一遍,一套 4000 行的 Agent 内核靠什么跑起来

此前发布的大年初一,龙虾大战这篇文章,我盘点了OpenClaw、nanobot、PicoClaw、ZeroClaw 等开源项目的最新进展。
其中,nanobot 是一个非常值得研究的开源项目,启发了 PicoClaw 和 ZeroClaw 等项目。

nanobot 是一个极度轻量(Ultra-Lightweight)的个人 AI 助手,在 README 里给了一个硬指标,核心 agent 功能大约 4000 行,实时统计 3,761 行(甚至提供了脚本 core_agent_lines.sh 用来核对)。
我们可以研究 nanobot 的设计思路,从而我们自己的 AI 产品中融入相关功能。
代码库:https://github.com/HKUDS/nanobot
我从 nanobot/agent/loop.py 里第一个 class AgentLoop 开始往下读,发现它把智能体写得很直白,先把端到端(end-to-end)链路讲清楚,再把每一段责任收敛到一个文件里。
本文为 nanobot 源代码拆解的第一篇。
先不讲细枝末节,我想先回答一个关键的问题,这套系统为什么能跑起来?
我会先把骨架捋清楚,再用几段关键代码,讲清楚它是如何实现的。
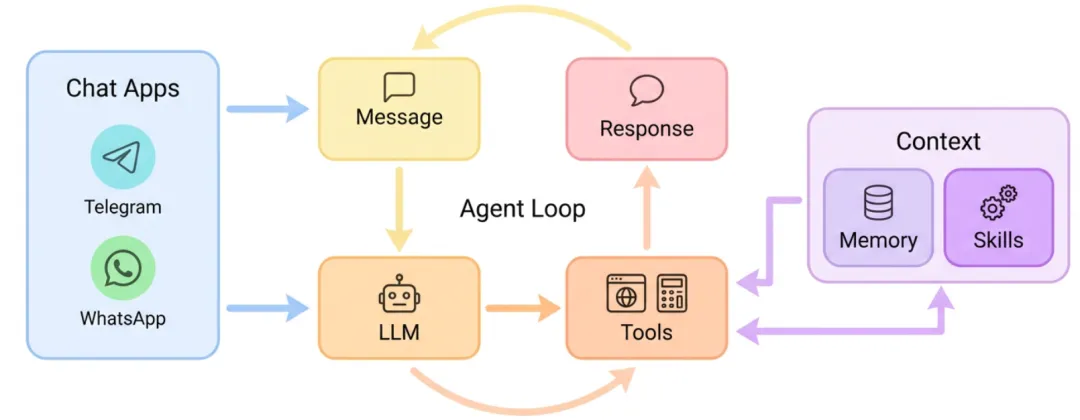
PART 01|我给 nanobot 画了一张文字架构图
如果只看目录,很容易迷路。我自己的读法是按“消息从哪里来、要到哪里去”来读。
nanobot 的主链路可以拆成 5 层。
-
入口层(Channels / CLI),Telegram、Slack、WhatsApp、CLI 等,把用户输入变成统一的 InboundMessage。
-
总线层(MessageBus),两个 asyncio.Queue 把入口与核心解耦。你可以把它理解成一个很小的 event bus。
-
执行层(AgentLoop),把 session/history、memory、skills 组合成 prompt,调用模型,再执行工具。
-
能力层(Tools / Skills),Tools 是可执行能力,Skills 是说明书。一个负责动手,一个负责教会模型怎么动手。
-
持续运行层(Cron / Heartbeat),让它从一个会话机器人变成能常驻的系统。
这五层背后的一个设计取舍很明确,尽量把复杂度外置,把核心 loop 写薄。
PART 02|MessageBus,两条队列,把复杂系统压扁
我最喜欢的设计,往往是少。MessageBus 就是典型例子。
在 nanobot/bus/queue.py 里,核心就是两条队列。
class MessageBus:"""Async message bus that decouples chat channels from the agent core.Channels push messages to the inbound queue, and the agent processesthem and pushes responses to the outbound queue."""def __init__(self):self.inbound: asyncio.Queue[InboundMessage] = asyncio.Queue()self.outbound: asyncio.Queue[OutboundMessage] = asyncio.Queue()self._outbound_subscribers: dict[str, list[Callable[[OutboundMessage], Awaitable[None]]]] = {}self._running = False
这句话的价值在于,它让渠道接入与智能体内核变成两个可替换模块。
-
你想接 Telegram?去写 channels/telegram.py,把消息 push 到 inbound。
-
你想换成企业微信?同样的模式再来一份。
-
AgentLoop 只盯着 inbound 消费消息,产出的统一发到 outbound。
而消息结构也很干净。在 nanobot/bus/events.py 里,InboundMessage 用一个 session_key 把会话抽象出来。
@dataclassclass InboundMessage:"""Message received from a chat channel."""channel: str # telegram, discord, slack, whatsappsender_id: str # User identifierchat_id: str # Chat/channel identifiercontent: str # Message texttimestamp: datetime = field(default_factory=datetime.now)media: list[str] = field(default_factory=list) # Media URLsmetadata: dict[str, Any] = field(default_factory=dict) # Channel-specific data@propertydef session_key(self) -> str:"""Unique key for session identification."""return f"{self.channel}:{self.chat_id}"
这就是我说的把复杂度压扁。不管你的 chat 平台多复杂,最终都会被压成 channel:chat_id 这一把钥匙。
PART 03|Gateway,把 Agent、Channels、Cron、Heartbeat 拼成一个常驻进程
很多开源 Agent 项目只写能跑,不写怎么长期跑。nanobot 的 gateway 命令里,我看到三个生产系统的味道。
-
cron(定时任务)
-
heartbeat(心跳/后台自驱)
-
channel manager(多渠道并发)
在 nanobot/cli/commands.py 的 gateway() 里,它用 asyncio.gather 把这些东西拉起来。
async def run():await cron.start()await heartbeat.start()await asyncio.gather(agent.run(),channels.start_all(),)
这里没有复杂的框架,没有厚重的依赖。它像一个朴素的控制面(control plane)。我把服务都启动了,剩下的交给事件循环。
这很符合 nanobot 的定位,轻量、研究友好、可改造。
PART 04|Session,JSONL 的取舍比记忆更聪明更重要
智能体最容易崩的地方,往往不是模型不够聪明。更多时候,是状态管理失控。
nanobot 在 nanobot/session/manager.py 里用 JSONL 做 session 持久化,并且强调一个关键点,append-only。
@dataclassclass Session:"""A conversation session.Stores messages in JSONL format for easy reading and persistence.Important: Messages are append-only for LLM cache efficiency.The consolidation process writes summaries to MEMORY.md/HISTORY.mdbut does NOT modify the messages list or get_history() output."""
def add_message(self, role: str, content: str, **kwargs: Any) -> None:"""Add a message to the session."""msg = {"role": role,"content": content,"timestamp": datetime.now().isoformat(),**kwargs}self.messages.append(msg)self.updated_at = datetime.now()
这在工程上很重要。
-
JSONL 便于增量写入、便于 tail、便于 grep。
-
append-only 的行为让缓存、回放、审计更容易。
-
即使你后面做更复杂的 memory(总结、提炼、向量化),也不影响原始对话日志。
这更像系统纪律。
PART 05|为什么说 nanobot 适合做你的产品基线
我把 nanobot 看成一套可读的最小内核。它更适合当你自己 AI 产品的底座(baseline),而不是直接拿去当产品。
原因很简单。
-
边界清晰,bus / session / agent / tools / skills 各司其职
-
可扩展但不乱,工具是 schema 化的(JSON Schema),skills 是文件化的(SKILL.md)
-
有生产味道但不沉重,cron、heartbeat、多渠道都在,但实现仍然轻
当然,如果你真要上生产(production),你还得补很多东西。比如权限、审计、隔离、限流、沙箱、观测……这些我会在本系列最后一篇集中讲清楚。
PART 06|写在最后
我相信,好的系统,在于核心硬,而不是功能多。
nanobot 的硬,不在于它写了多少抽象层。它更像一种克制,把复杂度控制在几千行里,让你读得懂、改得动。
下一篇我们就从它的心脏下刀,AgentLoop。看它如何在 20 次迭代里,把模型、工具调用、进度流(progress streaming)串成一条可控的执行链路。
