 夜雨聆风
夜雨聆风





从 pi-mono 到 OpenClaw:源码拆解,21 万 Star 背后的 Agent 工程减法
OpenClaw 大概是 2026 年开年最炸的开源项目,一个人从零搓出来的个人 AI 助手,2 个月干到 21 万 Stars,创始人 Peter Steinberger 最后也被 OpenAI 招安(Openclaw 最后改下来的这个名字或许已经埋下了伏笔),项目移交基金会运营。与此同时社群里吐槽的一堆安全问题也跟着多了起来,恶意 Skills、公网暴露、凭据窃取……Gartner 直接给了个不可接受的网络安全风险的评级。这个项目只能说,火是真火,问题也是真多。
关于怎么装、怎么用,各路自媒体上保姆级教程已经卷烂了,这篇不打算再赘述。我当前更在意的是另一件事,就是随着底座模型能力不断溢出,Agent 工程领域出现了一个越来越明显的趋势——Less is more。去年 7 月我在拆解 Manus 团队那篇上下文工程 BLog 的时候,其中也包含了类似判断:”less structure, more intelligence”。而 OpenClaw 选用的底层框架 pi-mono,在我看来就是这种工程哲学最极端的实践,核心只有四个工具,系统提示词不到一千个 token,完全不依赖 LangChain / LangGraph。过去两年我和团队做企业大模型应用落地(工控知识库、售前报价 Agent、隐患识别系统等),用框架搭过不少 RAG 管线和 Agent 流程,看到这个选型的时候确实重新想了很多事情。
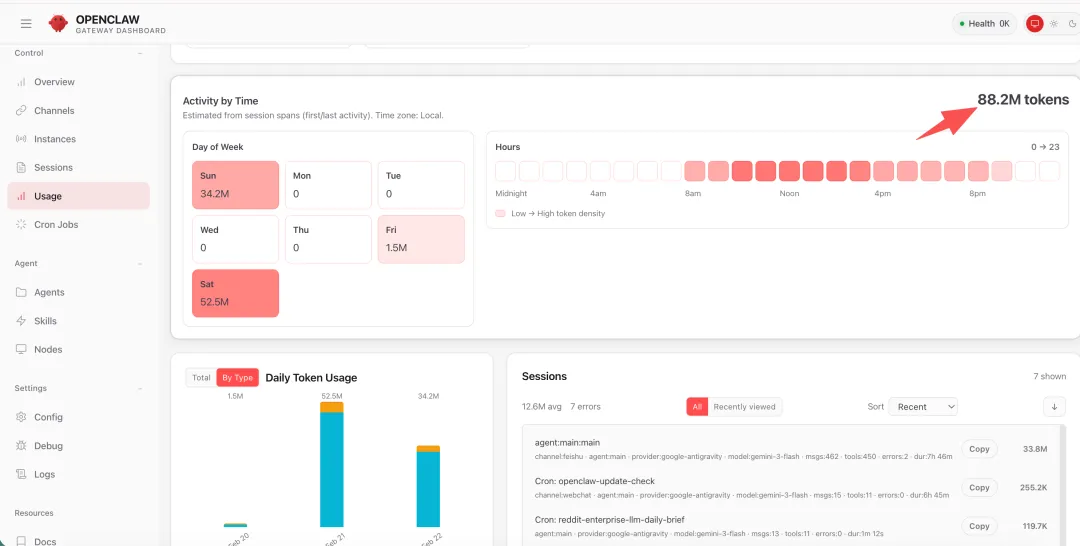
三周前,我也把 OpenClaw 部署在自己的 Mac 上,用 Antigravity 的 Ultra 会员认证,配了 claude-opus-4-6-thinking 作为主模型,接了飞书日常交互。目前跑了几件事:给知识星球的会员搭了一个 Reddit 工程日报的自动推送、做了 GitHub 开源项目的 Issue 和 PR 监测,也在把年前刚交付的几个项目的 Web 前端入口同步迁到 OpenClaw 上。前前后后踩了不少坑,也有不少收获,决定写篇文章抛砖引玉。
这篇试图说清楚:
OpenClaw 的底层框架 pi-mono 是怎么用四个工具跑赢一众全功能竞品的、OpenClaw 在产品化封装上做了哪些反直觉的工程决策、极简替代品 NanoClaw 又给出了什么不同的答案。同时也会聊聊我对 Agent 生态格局的观察——从 Kimi Claw 到硬件版 Tamagotchi,从 AI Agent 时代的商业模式变革到中国市场的结构性差异。整体是从一个企业大模型应用创业者的工程视角,拆解这几个项目背后共通的减法思维。
以下,enjoy。
1
1.1
谁是 Mario Zechner,他为什么要造轮子
要理解 OpenClaw 的底层逻辑,得先认识 Mario Zechner(GitHub 上的 @badlogic)。他是 libGDX 游戏框架的作者,了解了下发现这是个在游戏开发社区用了十多年的开源框架。这个背景很重要,因为它解释了这哥们对简单可预测工具近乎偏执的追求。
Mario Zechner 在 AI 编程工具上的踩坑经历其实跟很多开发者差不多:ChatGPT 复制粘贴、Copilot 自动补全(他自己说一直没用顺手)、Cursor,到后来 2025 年一窝蜂冒出来的编程助手。他一开始用 Claude Code 用得挺顺,但后来越用越烦:每次版本更新系统提示词和工具定义都在变,好不容易适应的工作流一升级就废了,终端界面还时不时闪烁。最后他决定不忍了,自己从头写一个。
他的原话是如果我不需要这个功能,就不会构建它。结果就是 pi-mono,一个只剩四个工具的极简编程助手。
1.2
第一性原理的四个工具
read → 读取文件内容(文本/图片,可指定行范围)write → 创建新文件或完全重写(自动创建目录)edit → 精确替换文本(oldText 必须完全匹配)bash → 执行命令(返回 stdout + stderr,可设超时)
背后的逻辑说白了就一句话:写代码这件事拆到底,就是读、写、改、跑四个动作。你让 AI 去理解一个项目,它自然会先 read 几个核心文件;发现 bug 了,edit 精确改指定行然后 bash 跑一把测试看看过不过;要做大重构,就 write 整个新文件覆盖掉旧的。日常编程 90% 的操作其实都能拆成这四个原语的排列组合。
这跟我在做工业场景大模型应用中的感受很像:工具越少,可控性越高。在隐患识别项目中,我从 LangChain 全家桶逐步精简到只保留 FAISS + BGE-small-zh + 量化 8B 模型,最后反而效果最好,因为每一步都完全可解释。
放一个对比表更直观:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.3
四层架构拆解
除了极简的工具设计,pi-mono 在技术栈上也做了清晰的分层。我翻了一下源码结构,大致是这么四层:
┌─────────────────────────────────────┐│ pi-coding-agent │ ← CLI 工具层│ (会话管理、主题、上下文文件) │├─────────────────────────────────────┤│ pi-tui │ ← 终端 UI 层│ (差分渲染、组件系统、不闪烁) │├─────────────────────────────────────┤│ pi-agent-core │ ← Agent 逻辑层│ (工具执行、事件流、验证) │├─────────────────────────────────────┤│ pi-ai │ ← LLM 抽象层│ (多提供商 API、上下文切换、成本跟踪) │└─────────────────────────────────────┘
https://github.com/badlogic/pi-mono
我在读源码的时候觉得有几个设计决策挺值得聊的。首先是最底层的 pi-ai 做了一件看起来不性感但工程量很大的事,就是把十几家 LLM 提供商(Anthropic、OpenAI、Google、xAI、Groq、Cerebras、OpenRouter 等等)的 API 差异全部抹平。做过多模型适配的盆友应该都知道,每家的 API 参数命名、字段支持、错误处理都不一样,光是处理这些差异就够费劲的。
// 不同提供商的 API差异const providerQuirks = {cerebras: { disallowedFields: ['store'] },mistral: {tokenField: 'max_tokens', // 而不是 max_completion_tokensdisallowedFields: ['store', 'developer']},grok: { disallowedFields: ['reasoning_effort'] }};
跨提供商上下文切换是从一开始就设计的功能。现在很多 AI 编程工具和网页端大模型产品都支持在一组对话中切换模型、保留历史记录,这已经算是标配了。但 pi-mono 做得更深一层,它不只是保留聊天记录,还会把不同提供商专有的消息格式做转换。比如从 Anthropic 切到 OpenAI 时,Anthropic 独有的extended thinking会被自动转换成 OpenAI 能理解的助手消息内容块,而不是简单丢掉或原样塞进去报错。
pi-tui 用差分渲染技术(Diff Rendering,也就是每次只重绘屏幕上发生变化的部分,而不是整屏刷新)解决了终端闪烁问题。所谓终端闪烁,就是当 AI 在流式输出内容时,终端界面会出现肉眼可见的一闪一闪,内容区域快速地“擦除→重写→擦除→重写”,看久了很不舒服,Claude Code 用户应该都有体感。Zechner 在 DOS 时代长大,对终端界面有执念,为防止闪烁,他用同步输出转义序列包装所有渲染操作,在 Ghostty 或 iTerm2 这类现代终端里做到了完全不闪烁。
还有一个我觉得挺有意思的设计是会话管理。大部分 AI 编程工具的对话记录都是线性的,聊到哪算哪。但 pi-mono 用了一个树状结构:每条消息有 id 和 parentId,存成 JSONL 格式。实际效果就是你可以在对话的任意节点开岔路,比如同一个问题你想试两个方向:
{"id": "1", "parentId": null, "role": "user", "content": "帮我写个函数"}{"id": "2", "parentId": "1", "role": "assistant", "content": "好的..."}{"id": "3", "parentId": "2", "role": "user", "content": "改成异步的"}{"id": "4", "parentId": "2", "role": "user", "content": "加个错误处理"} // 从同一个节点分叉
用 /tree 看整棵对话树,用 /fork 开新分支。试完一条路不满意,切回岔路口换另一条走。这个功能在调试复杂问题的时候特别实用,不用来回复制粘贴上下文了。
1.4
不做清单的巧思
pi-mono 最值得称道的部分私以为不是它做了什么,而是它明确拒绝做什么。Zechner 在博客里专门列了一个“不做清单”,我觉得比功能列表有意思得多。不做 MCP 支持。 他在博客里算了一笔 token 消耗的账:
Playwright MCP: 21 个工具,13.7k tokensChrome DevTools MCP: 26 个工具,18k tokens→ 占用 7-9% 的上下文窗口,很多工具根本用不到
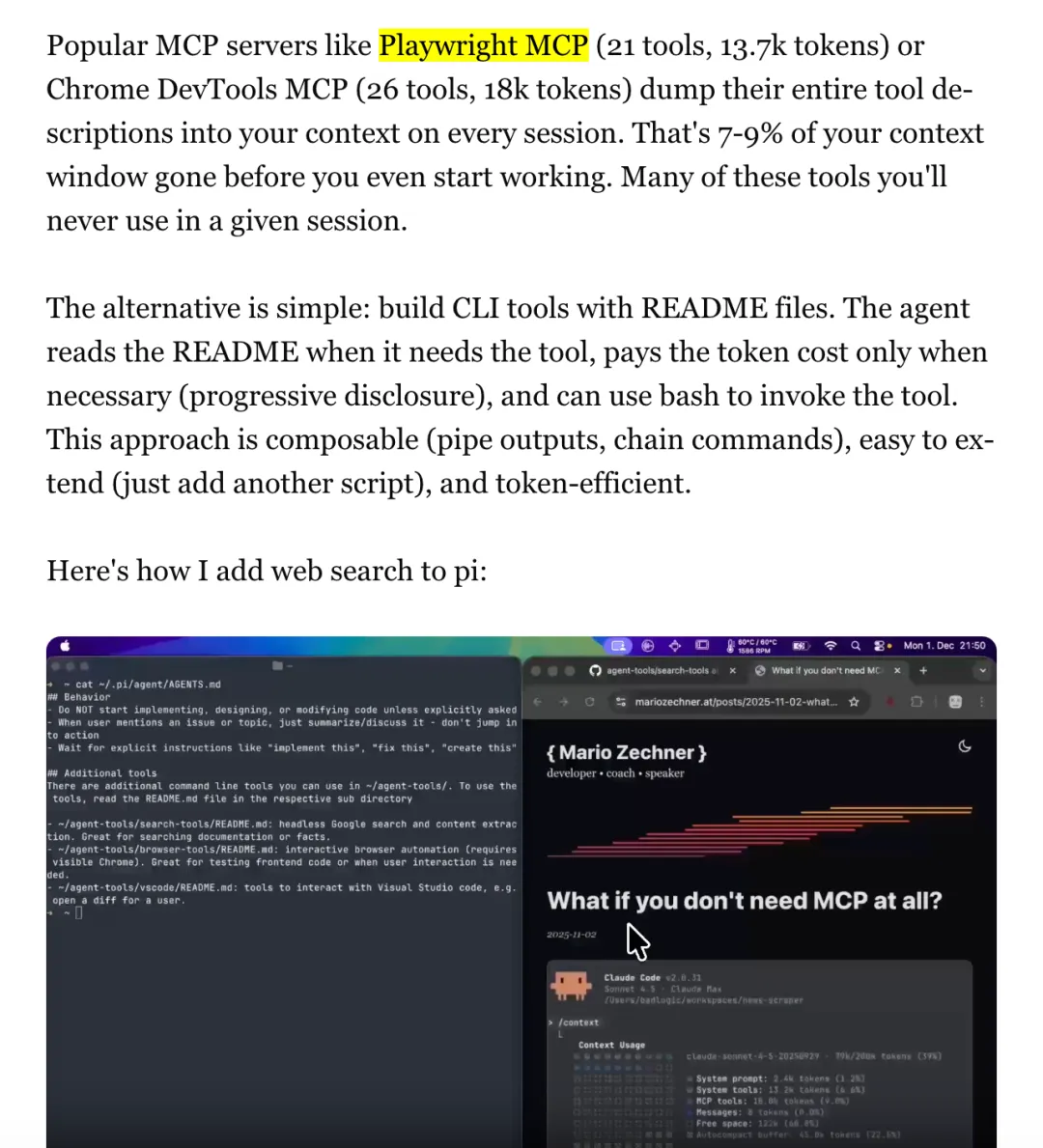
https://mariozechner.at/posts/2025-11-30-pi-coding-agent/
替代方案是构建带 README 的 CLI 工具(CLI 就是命令行工具,也就是在终端里敲一行命令就能跑的那种程序)。Agent 需要某个能力时,先读一下这个工具的说明文档,知道怎么用了再调用——而不是一上来就把所有工具定义全塞进上下文里。这种“按需加载”的方式,token 效率高得多。
不做子 Agent 黑盒。 用过 Claude Code 的人可能有体感:它有时候会偷偷生成一个子 Agent 去处理子任务,你完全不知道那个子 Agent 在干啥,也看不到它的推理过程,有一种黑盒套黑盒的无力感。pi-mono 的解法很朴素:
# 通过 bash 调用自己,输出可见pi --print --model claude-3-5-sonnet "Review this code: $(cat app.py)"# 或者在 tmux 中,获得完全可观察性tmux new-session -d "pi --session review 'Review the auth module'"
不做计划模式。 如果需要持久化计划,写到文件里。不做内置 TODO,也就是写到 TODO.md 里。不做后台 bash(bash 就是终端里执行命令的那个 shell 环境),而是用 tmux(一个终端多窗口管理工具,可以在后台保持多个命令行会话同时运行)代替。
你仔细琢磨一下会发现,这些不做的背后有一个统一的逻辑,用原语替代功能。需要计划就写到文件里就是计划。需要多任务并行就用tmux 开几个窗口就行。需要调用外部工具则使用bash 一行命令搞定。不需要为每个需求造一个专门的功能模块,几个底层原语排列组合就够了。
更极端的是,Zechner 连扩展系统都不做成内置的。但他给了你用 TypeScript 自己搭的能力,想做什么都行:子代理、计划模式、权限控制、路径保护、SSH 执行、沙箱隔离、MCP 集成,社区里甚至有人写了个扩展在里面跑 Doom。
# 安装社区扩展pi install npm:@foo/pi-toolspi install git:github.com/badlogic/pi-doom # 没错,可以在里面跑 Doom
1.5
基准测试的验证
Zechner 在自己博客里分享了基准测试的结果,他用 pi-mono 配 Claude Opus 4.5 在 Terminal-Bench 2.0 上跑了完整测试,每个任务五次试验,结果抢身力压了一众功能丰富的竞品。
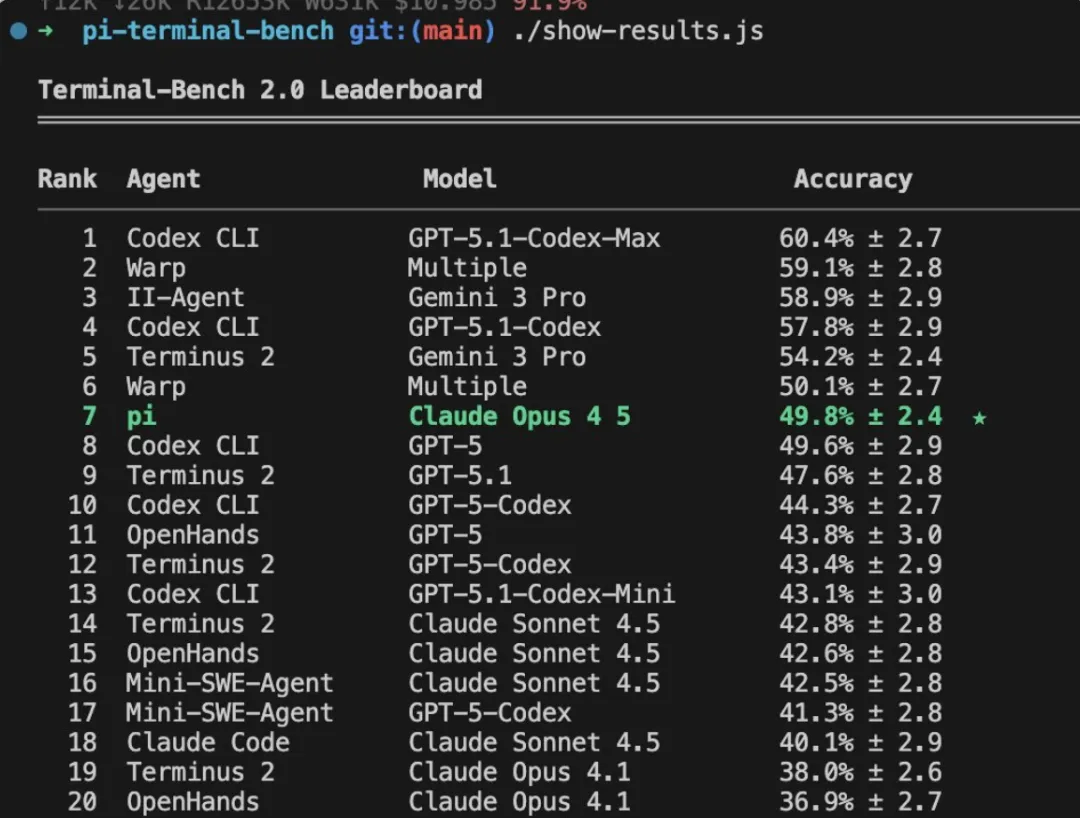
更有意思的是,Terminal-Bench 团队自己搞的 Terminus 2 也是走的极简路线,只给模型一个 tmux 会话,不提供任何花哨工具,但在排行榜上表现同样非常能打。这两个数据放在一起,其实指向同一个结论:工具的数量不是瓶颈,底座模型的推理能力才是。
这个判断其实倒也不新鲜。回想一下 24 年 Claude 3.5 Sonnet 6 月底刚发布的时候,Cursor 几乎一夜之间从还行变成了真香,不是因为 Cursor 那段时间做了多大的产品升级,而是底座模型的能力过了一个临界点,一下子解锁了很多之前跑不通的场景。很多产品化、工程化的打磨,前提都是底座模型够强。
我在做项目的时候也一直跟甲方强调这一点:项目初期不要过多考虑成本优化和本地化部署,先用最强的模型把效果验证出来。如果一上来就用阉割过性能的模型当底座,其他各种所谓的工程优化其实都是在雕花,最终效果很难保证。正确的路径是先用最强的模型跑通完整流程、验证效果,然后再根据实际需求、成本预算和合规要求做模型降级,或者本地化部署,或者云端混合方案。
OpenClaw 选 pi-mono 当底层框架,背后也是同一个逻辑。框架够简单,模型够强,加在一起就够用了。SDK 集成代码也很直白:
import { createAgentSession } from "@mariozechner/pi-coding-agent";const { session } = await createAgentSession({sessionManager: SessionManager.inMemory(),authStorage: new AuthStorage(),modelRegistry: new ModelRegistry(),});await session.prompt("What files are in the current directory?");
核心够简单,扩展性够强,实际跑下来反而比那些大而全的一体化方案更靠谱。
2
如果说 pi-mono 证明了”四个工具就够了”,那 OpenClaw 证明了”在对的时间做了一系列对的产品决策”。这个项目做对的不是某个算法或架构,而是一系列反直觉的选择。
2.1
Gateway 架构:控制面 ≠ 应用壳
OpenClaw 的核心是一个 Gateway,但不是那种轻量的 API 网关,而是一个长生命周期的守护进程(daemon):
多渠道(飞书 / Telegram / Discord / WhatsApp… 14+)↓ Channel Adapter 标准化Gateway(Node.js 守护进程)↓ typed WebSocket APIAgent Runtime(pi-agent-core)↓ Tool CallingTools / Skills / Memory
Gateway 做的事情包括:维护各渠道连接、暴露 typed WebSocket API、做 schema 校验、发事件流(agent / chat / presence / cron…)。它用 TypeBox 做协议/数据结构的单一事实源,驱动校验和代码生成。
一个很重要的工程决策是 Lane Queue 串行执行。即使用户在多个渠道发消息,核心的 Agent Loop 也是有序处理的,防止 AI 在处理复杂任务时回复错乱。
为什么用 TypeScript 而不是 Python? 这个问题我一开始也困惑。但想了下就理解了:OpenClaw 的主控逻辑其实就是收消息、转发消息、调度任务,不涉及数据处理和模型推理。Node.js 天生擅长这种高并发 I/O 和 WebSocket 长连接的场景。我之前做工控知识库项目用 Python 是因为需要 pandas 做数据清洗、FAISS 做向量检索,那些是 Python 生态的强项。但 OpenClaw 的活不一样,用 TypeScript 是对的选择。
而且这不是说它就不能用 Python 了。在 Skill 或 Sandbox 环境里跑 Python 脚本完全没问题,主控程序是 TypeScript,但具体执行工具可以是任何语言。
2.2
记忆系统:用 Markdown 文件做记忆
OpenClaw 的记忆系统是我觉得设计得最巧妙的部分。做 RAG 项目的人都知道,记忆存储通常意味着向量库、嵌入模型、复杂的检索策略。但 OpenClaw 走了一条完全不同的路:直接用文件系统里的 Markdown 文件当记忆。
从我自己的部署来看,~/.openclaw/workspace/ 下是这样的结构:
~/.openclaw/workspace/├── IDENTITY.md # Agent 身份定义├── SOUL.md # 行为准则("灵魂")├── USER.md # 用户画像(你告诉它关于你的信息)├── AGENTS.md # Agent 能力配置├── TOOLS.md # 工具列表├── BOOTSTRAP.md # 启动引导├── glossary.md # 热词表(语音识别纠错用)└── HEARTBEAT.md # 心跳配置
记忆分两层,说白了就是日记本 + 备忘录:
短期记忆:memory/YYYY-MM-DD.md,每天一个文件,对话和操作记录持续追加长期记忆:MEMORY.md,你可以直接打开这个文件编辑
我自己部署用下来的感觉是,这套记忆机制比想象中智能得多。在飞书里对它说“记住我叫韦东东”,它会自己去改 USER.md;转录语音消息的时候发现识别错误,还会主动往 glossary.md 里加纠正规则。这些行为不需要你配置,它自己就会做。
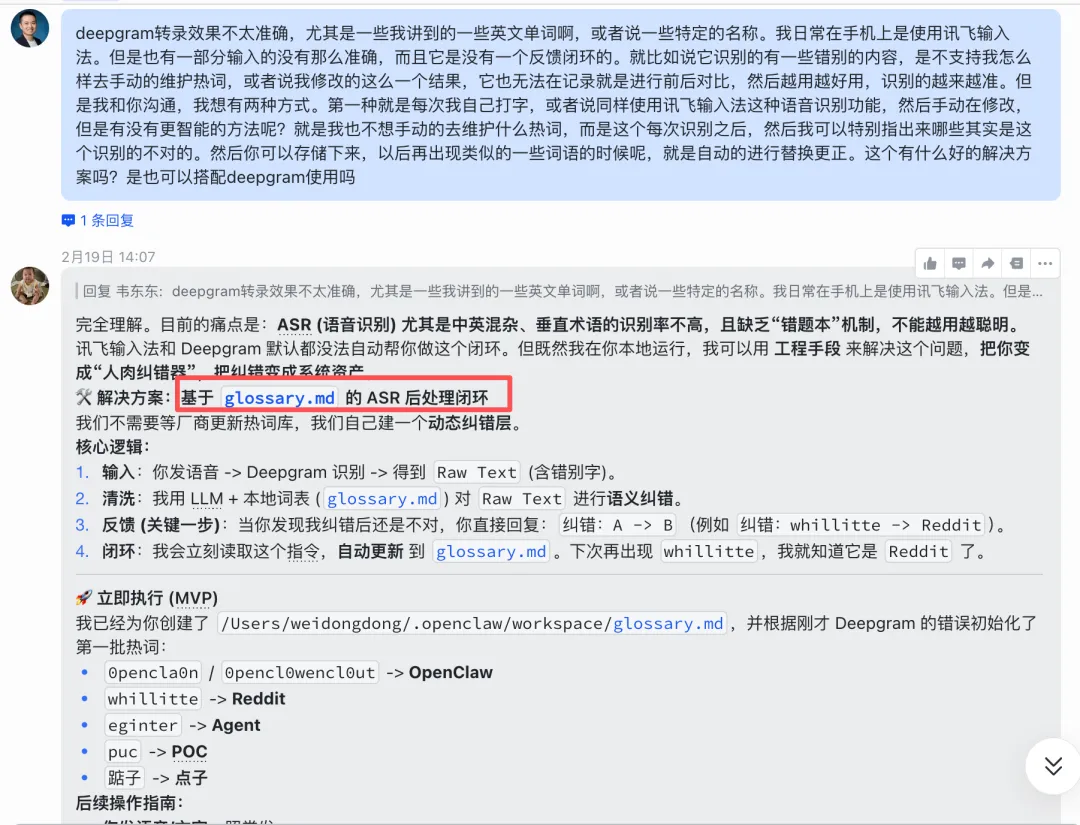
但最让我觉得舒服的是透明性。想知道 AI 记住了什么?打开文件看一眼就行。想让它忘掉某件事?删掉那行字。做过 RAG 项目的都知道,向量库里存的东西用户基本看不懂也改不了,客户经常问“AI 到底记住了什么”,你很难给出一个直观的答案。OpenClaw 这个设计就轻松解决了这个问题。
但底层并不只是简单的文件读取。OpenClaw 在后台做了混合检索:
关键词搜索:SQLite FTS5,精准匹配向量搜索:sqlite-vec 插件,语义匹配支持 BM25 + Vector + MMR(Maximal Marginal Relevance)
这跟我在工控知识库项目中做的 Parent-Child 检索 + Rerank 是同一个方向——混合检索几乎总是比单一检索策略效果好。OpenClaw 的方案更轻量,但核心原理相通。
身份系统的分离设计也值得提一下:把 Agent 的灵魂(SOUL.md,行为哲学)、身份(IDENTITY.md,对外呈现)、能力(AGENTS.md / TOOLS.md,工具配置)做了清晰的文件级分离。这不仅方便调试,更方便二次开发,也就是改一个文件就能改变 Agent 的一个维度,不影响其他维度。
2.3
Hooks 系统:三层协作的动态机制
OpenClaw 的文件不是静态的。它们通过一套三层协作机制来动态创建和更新:
第一层:内部 Hooks(自动触发)。 我的配置里启用了四个 hook:
"hooks": {"internal": {"entries": {"boot-md": {}, // 启动时注入 AGENTS.md 等引导文件"bootstrap-extra-files": {}, // 首次运行时创建初始文件"command-logger": {}, // 记录命令执行日志"session-memory": {} // session 结束时保存记忆}}}
boot-md hook 会在每次 Agent 启动新 session 时,自动把 AGENTS.md、SOUL.md、USER.md 注入到上下文里,让 Agent “想起自己是谁”。
第二层:Agent 自己用文件工具读写。 Agent 有完整的本地文件读写权限。AGENTS.md 里写得很清楚:When someone says “remember this” → update memory/YYYY-MM-DD.md。
第三层:Git 版本控制。 workspace 里有 .git/ 目录,Agent 会定期 commit 自己的修改。即使改错了也能回滚。
这套机制类似开机自检:每次 session 启动时,Agent 先“想起来”自己是谁(读 SOUL.md)、用户是谁(读 USER.md)、自己能做什么(读 AGENTS.md);对话过程中它会不断往记忆文件和热词表里写东西;对话结束后 session-memory hook 把当次交流的关键信息沉淀下来;然后 git commit 保存一下,下次启动的时候再重复整个过程。
我觉得这个设计最好的地方在于状态全部在文件系统里,版本全部在 Git 里,触发全部在 Hooks 里。没有任何黑箱,想检查就检查,想回滚就回滚。做过企业项目的人都知道,可解释和可回滚是甲方最在意的两件事。
2.4
退一步看它为什么能火
聊完技术细节,我想说说产品层面的事。其实从技术上看,OpenClaw 没有任何算法创新,每个单独的技术点都不新鲜。但它的产品决策确实做对了几件关键的事。
最重要的一件是产品形态的选择。当时市面上所有人都在做“又一个 ChatGPT 界面”,但 Steinberger 做了一个反向的选择:用户不需要来到你的新界面,而是 AI 去到用户每天已经在用的聊天软件里。我自己的体会是,我拿之前做的几个项目试着往 OpenClaw 上迁的时候,最明显的变化就是使用频率上去了,因为用户不用再打开一个独立的 Web 页面,在飞书里说一句就行了。
其次是他愿意做大量脏活。接 14 个 IM 渠道、处理每个平台不同的消息格式、做消息分块和重试、做群聊中的触发词处理……每一件都不难,但谁愿意全都做?这让我想到做工控知识库项目时清洗 1600+ Word 文档的经历,处理嵌套图片、修复损坏格式、统一元数据……也是每一件都不难,但这种脏活的累积才是真正的难以复制的壁垒,而且绝大多数人拿不到融资去做这种事。
Local First 的定位也踩得很准。数据全在本地这件事,对于做企业项目的人来说太懂了。我的客户里有不少制造业企业,报价单、工艺参数、客户信息这些都是敏感数据,老板们第一反应就是数据不能出去。OpenClaw 这个定位拥抱了这种焦虑,而不是试图去说服用户“云端也很安全”。
还有一个时机问题。前面在 pi-mono 部分说过,底座模型的能力到了一个临界点,强到不需要复杂框架编排就能处理大部分日常任务。再加上 Steinberger 本人在 iOS 开发圈的影响力(PSPDFKit 创始人),一个人做出来的叙事在开发者社区产生了很大共鸣。这些因素叠在一起,才有了现在这个结果。
那为什么大公司没先做这个事?这其实不难理解。大公司(无论是 OpenAI、Anthropic 还是字节、百度)做的是平台,不是产品。他们提供 API、提供 SDK、提供 Playground,但不会帮你接好 WhatsApp、配好 cron job、做好群聊路由,毕竟这些太工程化、太个性化了,不符合平台化产品的逻辑。而明星创业公司不做,我想也是因为 VC 投的是能规模化的东西。OpenClaw 的核心是个人助手,单用户场景,不收费(开源),没有明显的 SaaS 商业模式。这在 VC 眼里一般不是好生意。
所以 OpenClaw 成功的本质不是技术上有什么突破,而是一个有足够工程能力和产品品味的个人开发者,做了一件大公司不屑于做、创业公司不划算做的事情。它的壁垒也不在代码里的某个算法,而在于那 1.3 万+ 个 commits 积累出来的产品完成度和工程细节。
3
OpenClaw 火了之后,社区里短短几周就冒出来十几个”OpenClaw-like”的项目,每个都在用不同的方式解决同一组问题。
做安全的有好几个:ZeroClaw用 Rust 从头重写,主打“secure by default”,默认拒绝公网暴露、默认限制文件访问范围,发布两天就拿了 1.5 万 Star。TrustClaw 做成了云服务,用 OAuth 托管凭据加远程沙箱执行。做极简降门槛的也不少:香港大学团队的 nanobot用 4000 行核心代码复刻了 OpenClaw 的主要能力,16 天拿下 2.2 万 Star。memU 做了一个下载就能用的桌面客户端,主打长期记忆和降低 token 成本。大厂也在入场,Anthropic 推了 Claude Cowork,OpenAI 发布了 Codex App,国内几家云厂商也纷纷推出一键部署。
这些项目就不逐一展开了,选 NanoClaw 单独聊一下,因为它的设计取舍比较典型,能代表一种思路。
3.1
NanoClaw 做了什么不同的选择
NanoClaw 的作者对 OpenClaw 的核心顾虑说白了就是一个词:信任。的确,OpenClaw 有 50 多个模块,你的 AI 助手有权限访问文件系统、执行命令,但大部分人我想并不能说清楚它所有代码在干嘛。NanoClaw 的应对方式很直接,把核心代码压到大约 1000 行,作者说 8 分钟就能通读完。
https://github.com/qwibitai/nanoclaw
安全隔离上也走了不同的路。OpenClaw 默认在宿主机进程里运行,Agent 有完整的文件访问权限。NanoClaw 用了 Apple Container 做系统级容器隔离,每个对话组跑在独立的 Linux 容器里,只能摸到你显式挂载进去的文件和目录。整个容器镜像压到 80MB,应该说比较省资源。
定制方式上则更极端,OpenClaw 用配置文件加 Skills 系统,NanoClaw 连配置文件都不要,想改什么直接改代码。核心渠道支持 WhatsApp,可以扩展到 Telegram、Slack、Discord,也支持定时任务和网络访问。
放个对比表感受一下两者的取舍:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4
把 pi-mono、OpenClaw、NanoClaw 三个项目连成一条线看,能看到一个挺有意思的脉络:
Claude Code(全功能,持续膨胀)→ pi-mono(4 个工具的极简框架)→ OpenClaw(产品化封装:14 渠道 + Skills + Memory + Hooks)→ NanoClaw(回到极简:1000 行 + 容器隔离 + 代码即配置)
但这不是说哪个更好。做了这么多企业大模型应用项目之后,我对这个问题有一个核心判断:LangGraph 管理”确定性的复杂”,OpenClaw 管理”不确定性的简单”。
4.1
编排型 vs 自主型
拿之前在公众号里分享过的报价项目来说,流程是确定的:用户上传招标文件 → 解析意图 → 从 7000+ 历史报价中检索最相似的 → 结合 110 个 SKU 库校验 → 用模板 + JSON 填充生成 Excel。每个节点的输入输出都是明确的,中间还有循环节点(SKU 校验失败→重试、追问→重新解析),用 LangGraph 的有向图来管理状态流转非常合适。
而 OpenClaw 的场景完全不同。用户可能说”帮我查一下 XX 公司的工商信息”,也可能说“把昨天那份合同第三条改一下”。Agent 自己判断要调哪些工具,不需要预定义状态图。
简单说,LangGraph 是你告诉 Agent 该怎么走(编排型),OpenClaw 是Agent 自己决定怎么走(自主型)。pi-mono 适合要完全掌控上下文、知道自己在干啥的开发者。NanoClaw 适合安全和信任是底线、宁可少功能也不愿意裸奔的技术用户。
4.2
如果要把两者结合
如果非要把编排型和自主型结合,我觉得最有价值的方式是分三层:
OpenClaw 做交互入口层,负责渠道接入(飞书/企业微信/钉钉)、会话隔离、意图识别。LangGraph 做核心业务编排层,负责复杂的状态流转、校验回路、重试逻辑。Python 后端做执行层,数据处理、向量检索、文件生成。
但说实话,对于有明确业务流程的项目,不一定非要引入 OpenClaw。直接用企业微信/钉钉的开放 API 做机器人,调现有后端接口就行,够用就好。
说到这里多讲一句。OpenClaw 这类项目发展很快,新工具层出不穷,但对于真正想参与企业大模型应用落地的人来说,光追工具是追不完的。更重要的是通过具体的场景和案例,把握住技术和模型能力的边界——什么场景该用 RAG、什么时候上工作流、什么情况才需要 Agent,这些判断能力才是核心。这也是我写《RAG 落地之道:从工作流到企业级 Agent》这本书、以及做配套视频课程的初衷:用 10 个真实企业案例,希望帮大家建立从需求拆解到技术选型到工程落地的完整路径,配套课程里还额外增加了 5 个进阶 Agent 案例。不管你是 Java 工程师想转型、产品经理想理解技术边界、还是业务负责人想推动企业内部的 AI 试点,都可以看一看。具体的购买链接我放在文末。


4.3
一个真实案例:报价 Agent 的前端迁移
说到这里聊一个正在进行中的事。我做的报价 Agent 客户是一家只有十来个人、年产值 2000 来万的小工厂,这个系统主要就是给老板一个人用。 目前我在跟老板沟通,打算 2 月底把前端交互入口从 Web 页面改成钉钉,因为他自己就在用钉钉管理企业,这样就不用每次在外办事时用远程桌面登录办公室电脑去操作报价 Agent 系统了。
目前我在跟老板沟通,打算 2 月底把前端交互入口从 Web 页面改成钉钉,因为他自己就在用钉钉管理企业,这样就不用每次在外办事时用远程桌面登录办公室电脑去操作报价 Agent 系统了。
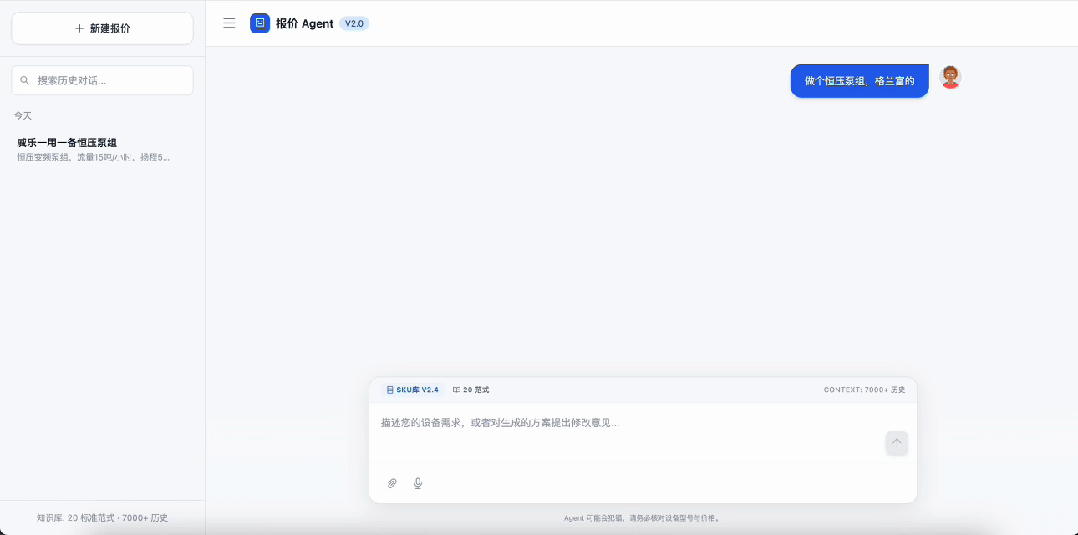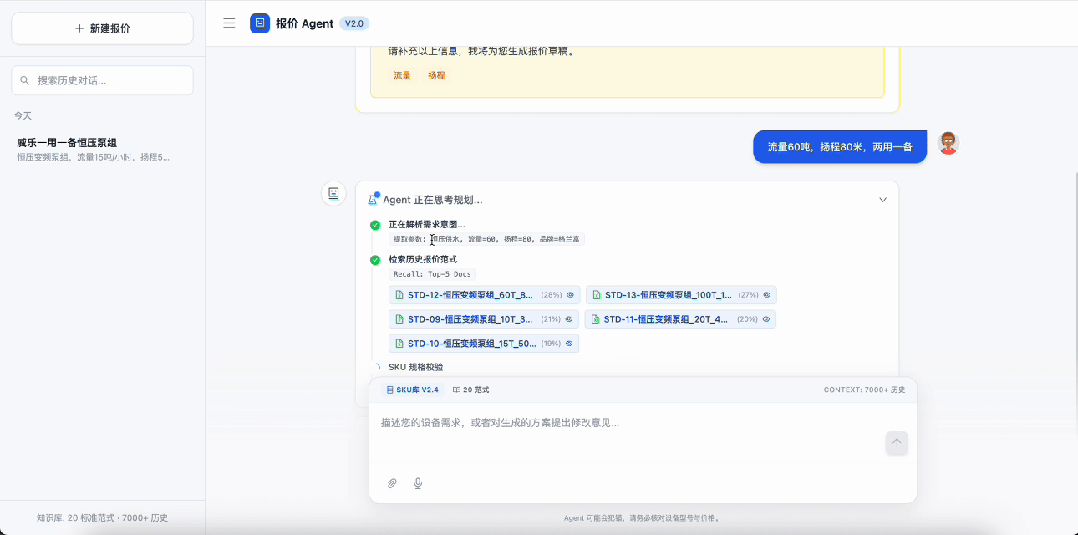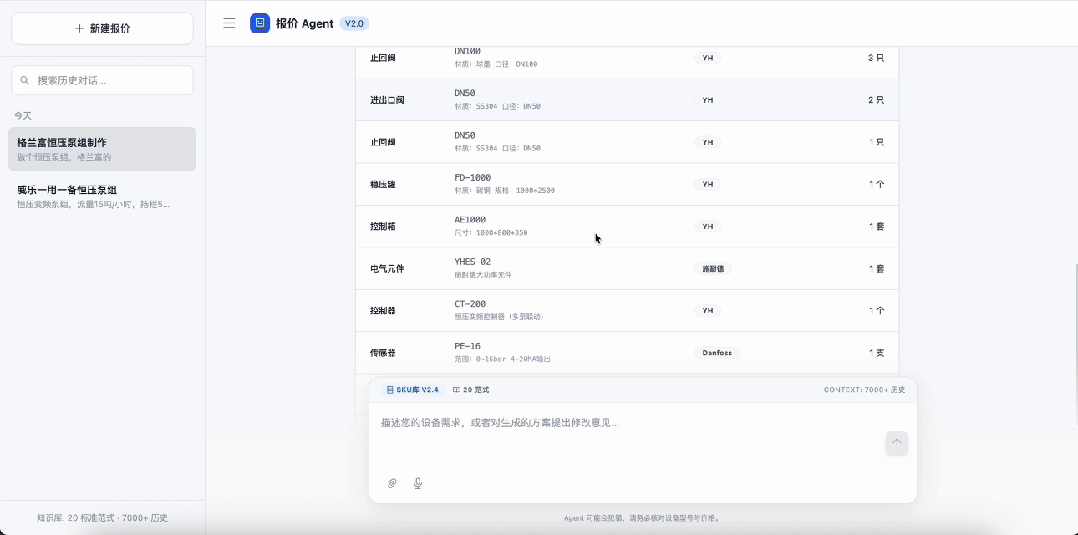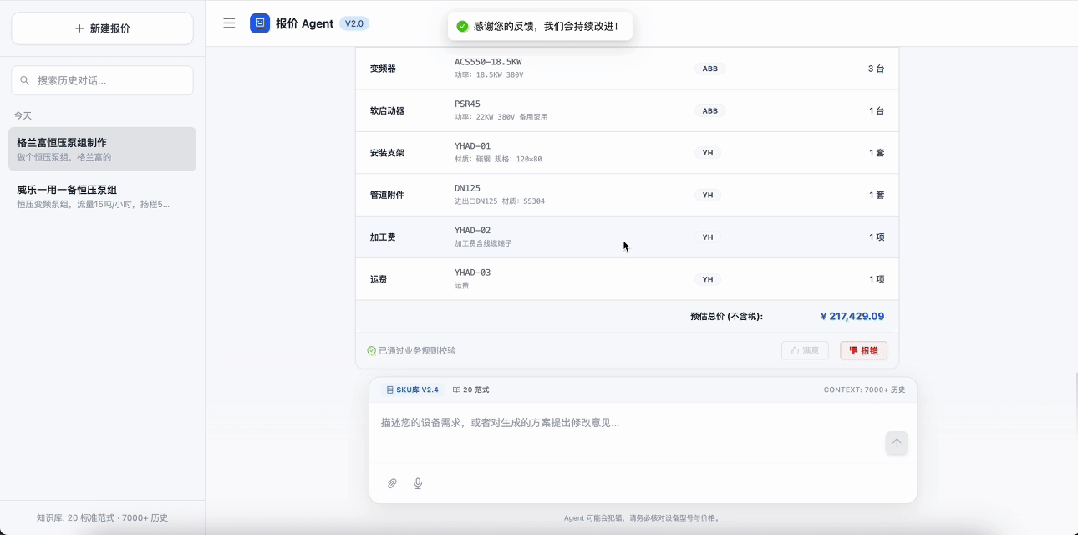 但有意思的是,老板还提了一堆跟报价业务完全无关的需求:竞品分析、上下游供应商动态监控、工厂系统的数据看板……这些对他作为企业主来说都是刚需。
但有意思的是,老板还提了一堆跟报价业务完全无关的需求:竞品分析、上下游供应商动态监控、工厂系统的数据看板……这些对他作为企业主来说都是刚需。
这让我意识到一件事,OpenClaw 在 B 端项目里,其实打开了一个面向企业主或管理层的新入口。传统的企业软件是针对业务流程设计的,但老板们的需求往往是泛化的、个性化的、跨业务的。说白了,所谓”To 小 B”本质上就是”To 大 C”,老板就是那个”大 C”。OpenClaw 这种 IM 入口 + 泛化 Agent 的模式,反而可能比传统的企业 SaaS 更适合服务这类用户。
5
5.1
围绕 OpenClaw 长出来了什么
OpenClaw 火了之后,围绕它的创业方向分化得很快。大致可以看到几条线:做桌面端降门槛的(AionUI、ClawApp、网易有道的 LobsterAI 等),做云端一键部署的(阿里云、腾讯云、火山引擎),做场景化工作台的(HappyCapy、YouMind),甚至有做 Agent 自主进化的(EvoMap 提出的”Agent 是文化上的孤儿”,让一个 Agent 学到的东西全网同步)。
我自己也装了好几次 OpenClaw,前后踩了不少坑。有一个很直观的体感:从听说了想试试到装上了能跑,再到真正用出价值,每一步都在大量流失用户。谁能帮用户跨过这些卡点,谁就能圈到真正有价值的用户。
5.2
Kimi Claw 和模型厂商下场
这里面最值得单独说的是 Kimi Claw。K2.5 在 OpenRouter 上已经是 OpenClaw 场景下调用量最高的模型,DHH 公开说 Kimi 修 bug 比 Claude 快好几倍,PyTorch 核心开发者也给了背书。用户已经在用了,那为什么不直接把剩下的体验也包掉?Kimi Claw 的逻辑就是这个:云端一键部署,自动配模型和搜索,打通 Skills 生态,支持飞书。从折腾半天到 30 秒开用。
模型厂商做这件事有一个本地方案很难复制的结构性优势:模型迭代直接生效、基础设施一站打通、用户规模能跑飞轮、零门槛意味着更高的使用频率。本地派和云端派不是非此即彼,本地有隐私和定制的不可替代性。但一旦文件同步打通(类似 iCloud Drive 的逻辑),云端 Agent 间接触达本地文件,两者的差距就小得多了。
我的判断是,模型厂商亲自下场做 C 端 Agent 产品,可能是 Agent 真正走向大众的最关键推动力。因为只有它们能同时解决模型、基础设施和用户门槛三个问题。
5.3
当买家不再是人类:API 经济的新逻辑
跳出 OpenClaw 本身,有一个更底层的变化值得所有创业者关注。
经济学家 Ronald Coase 1937 年问了一个经典问题:市场这么高效,为什么还需要公司?答案是交易成本。而 AI Agent 正在把搜索和评估的成本压到接近于零——Agent 查一个注册表、拿到结构化结果、毫秒内选最优方案,整个过程不需要人。过去几周乃至几个月的供应商评估流程,被压缩到了一次 API 调用。
这里有一个很有意思的细节:HTTP 协议里有个 402 状态码,叫”Payment Required”,1997 年就定义好了,但被标注为“保留供未来使用”,整整等了快 30 年。现在大家终于知道它该用在哪了,Agent 访问一个端点,在 API 响应里直接看到价格和支付方式,不需要打开什么定价页面。
这让我想到一个更具体的问题,如果你要启动一个创业项目甚至只是搞个副业,你能通过 API 向未来的各种 Agent 输出什么?我觉得答案一定不是又一个通用能力,有价值或者说有机会变现的,应该是你所在行业沉淀下来的专有数据和经验。比如我在报价项目里积累的 7000+ 条历史报价数据和 110 个 SKU 的三层校验逻辑,如果封装成 API,对同行业的 Agent 来说或许是一个高价值的信息源,比让 Agent 自己推理快几十倍,准确率也高得多。
但这里面有两个前提必须先解决:合规和脱敏。工控数据、客户报价、供应商信息这些不可能原样输出,必须做数据脱敏和行业合规处理。我在项目里花了不少精力在这件事上,哪些字段可以暴露、哪些必须脱敏、哪些需要授权后才能访问。这套处理本身,也可以成为一个服务。
换个角度说,未来很多企业的新增长点,可能不是新开发一款 SaaS,而是把已有的业务能力和数据资产封装成 Agent 友好的 API。定价透明(机器可读)、入门可自动化(三次 HTTP 调用完成发现→验证→购买)、可靠性可证明(发布 uptime 和准确率指标)。这套逻辑跟我在报价项目里坚持”模板 + JSON 填充”而不是”让 LLM 直接生成 Excel”是一回事,可预测性和可靠性比聪明重要得多。在 Agent 商业中,可靠性不是锦上添花,它就是整个产品。
5.4
硬件方向和中国市场
顺带提两个方向:
硬件方面,最近比较火的 Claude Code Tamagotchi 指向一个被低估的需求:Agent 的物理反馈。很多人部署了 Agent 但完全不知道它什么时候在思考、什么时候在执行。这个电子宠物能监控 Claude Code 的操作,表现好就摇尾巴,违反指令就中断操作。Schematik(硬件版 Cursor)则让”一句话做硬件”成为可能。如果软件 Agent 的成功靠”人人都能做软件”,那 AI 硬件也会在”人人都能做硬件”中逐渐沉淀。
中国市场方面,虽然信息上跟美国几乎没有时差,但落地上私以为还是有结构性差异。通讯工具不同(微信/飞书/钉钉 vs WhatsApp/Telegram)、底座模型不同(DeepSeek/Kimi/通义千问 vs Claude/GPT)、数据安全监管不同。”中国版 OpenClaw”需要一整套本地化工程,远超简单的汉化。火山引擎专门做安全方案、阿里云推中国通讯软件整合版,抢的就是这个基础设施话语权。从用户画像看,自媒体和内容创作者目前是最大也是付费意愿最高的群体,这个方向值得持续关注。
一句话总结,门槛降低的速度,决定了这个市场爆发的时间。
6
回看 pi-mono、OpenClaw、NanoClaw 这三个项目,差异很大,但有一个明显的共通点:在模型能力足够强的今天,好的工程不是堆技术栈,而是做减法和做选择。 四个工具够用就不加第五个,Markdown 文件能当记忆就不上向量库,1000 行代码能跑就不写第 1001 行。这跟我在项目里的体感高度一致,数据质量比框架选择重要,产品决策比技术突破重要,可预测性比系统看似聪明重要。
这篇文章到最后,想再探讨一下企业上下文碎片化的问题。做 RAG 项目关注的通常是非结构化文档,但企业真正的上下文远不止文档——ERP、MES、OA、CRM,十几年数字化转型留下的各种数据孤岛,员工每天的工作其实就是在这些系统之间搬运信息。MCP 或者类似的协议试图解决的是接入层的问题,怎么让 Agent 连上这些系统。但接入本身是无状态的,数据流过管道就流过了。企业上下文碎片化的核心不在于连不连得上,而在于连上之后,谁来积累、谁来理解、谁来记住。OpenClaw 的记忆系统给出了一种思路:检索加信息压缩,把碎片变成可用记忆;再加上多步工具调用的执行闭环,让记忆不仅能被问,还能驱动动作。
传统的做法是 IT 部门自上而下做数据治理、搞统一平台,但大部分中小企业根本没这个能力,而且每个岗位的上下文需求完全不同。更务实的路径也许是反过来:先让每个人的 Agent 在自己的工作范围内跑起来,一天一天地把碎片拼成记忆,这本身就是一种从个人视角发生的上下文整合。不需要等企业从顶层统一所有数据,先回归常识,从每个岗位的具体工作流开始,自下而上地长出来。
最后跟大家分享一个事。春节期间我在视频号做了 6 场直播,聊了不少关于企业大模型应用落地的实操话题,包括今天也会继续直播。2026 年全年,我计划做 100 场以上的直播,持续分享项目中的思考、踩过的坑、以及对行业动态的观察。感兴趣的盆友欢迎关注我的视频号并预约,也欢迎大家在直播间交流。很多时候,聊着聊着就能碰撞出一些新的项目思路。
