 夜雨聆风
夜雨聆风





这份277页的PDF涵盖了LLM从理论基础到训练机制再到对齐与优化!
在大模型时代,很多人都在问一个问题:到底有没有一份系统资料,能把大语言模型从底层逻辑到工程实战讲清楚?
最近看到一份 277 页的 PDF,内容结构非常完整。
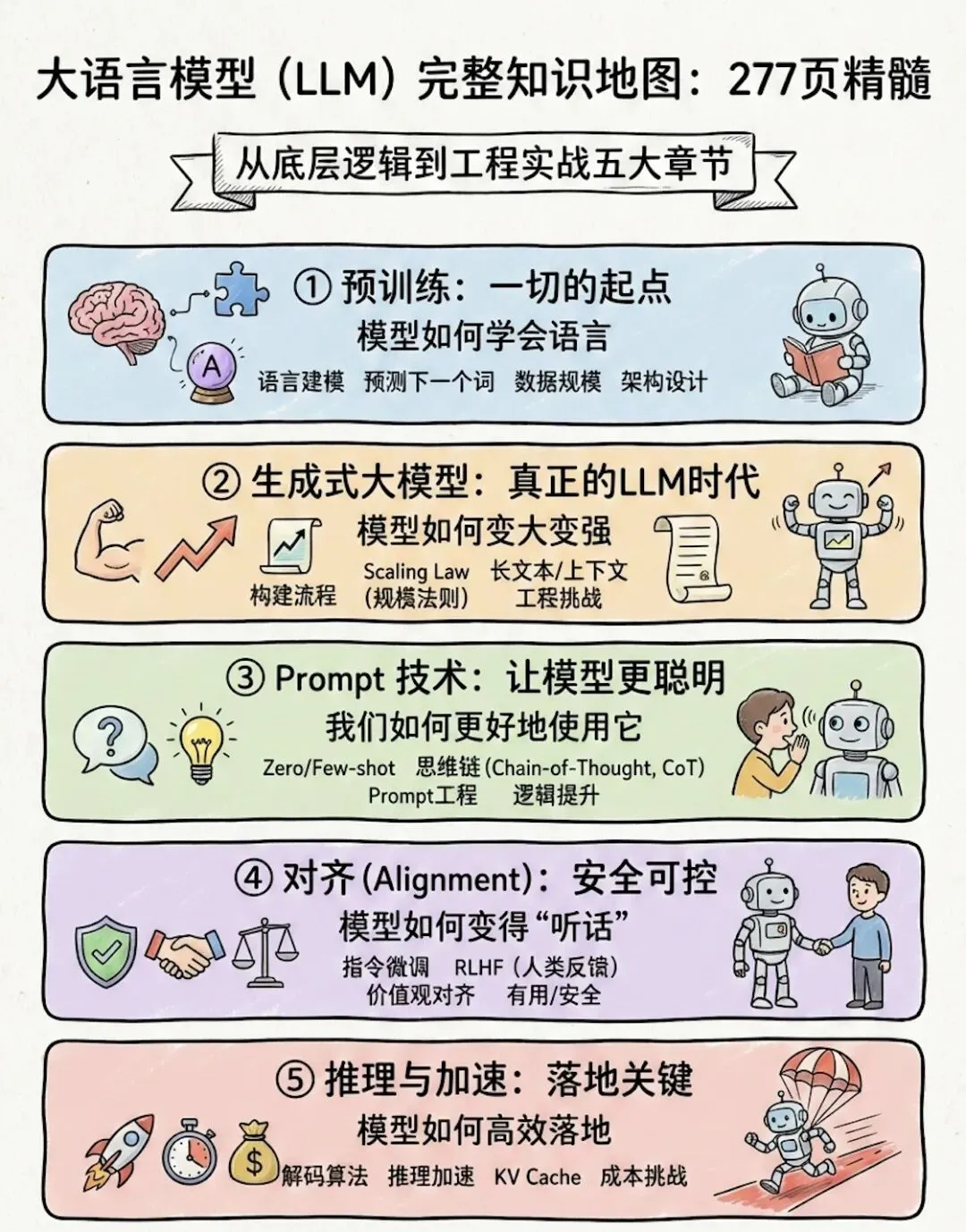
简单来说,一共包含5章:
-
预训练 —— 模型如何学会语言 -
生成模型 —— 模型如何变强 -
Prompt —— 我们如何更好地使用它 -
对齐 —— 模型如何变得安全可控 -
推理 —— 模型如何高效落地
它覆盖了:理论基础、训练机制、应用方法、安全对齐和工程优化。
对于想转型做大模型开发的人、做 AI 产品的产品经理、想理解大模型底层逻辑的工程师、以及正在做 AI 创业的人,这5章就是完整的大模型知识地图。
如果你想真正吃透大语言模型(LLM),这5章几乎覆盖了从“怎么训练”到“怎么推理”的全链路知识。
1. 预训练:一切的起点
第1章讲的是 Pre-training(预训练)。

很多人天天在用大模型,但对“预训练”其实理解得并不深。事实上:预训练,是大语言模型能力的根基。
这一部分主要讲了:
-
常见预训练目标(自回归、掩码语言模型等) -
语言建模的基本思想 -
主流模型架构(Transformer 等) -
训练语料的构建方式
如果你理解了这一章,你会明白:
-
为什么模型可以“预测下一个词” -
为什么数据规模决定模型上限 -
为什么架构设计影响模型表达能力
预训练解决的是:模型如何学会语言本身。
2. 生成式大模型:真正的 LLM 时代
第2章开始进入核心——生成式模型。

我们今天说的 GPT、Claude 等,本质上都是生成式语言模型。
这一章会讲:
-
生成模型的构建流程 -
从数据到训练到评估的完整路径 -
如何进行大规模训练(Scaling Law) -
如何处理长文本(长上下文问题)
这一章的重点在于:模型如何“变大”且不崩溃?
你会看到:
-
模型参数如何扩展 -
数据规模如何匹配 -
长文本训练的技术难点
这一部分非常适合理解“大模型工程”。
3. Prompt 技术:让模型更聪明
第3章讲的是 Prompting 方法。

这是应用层最关键的一部分。
包括:
-
Zero-shot / Few-shot -
Chain-of-Thought(思维链) -
自动 Prompt 设计 -
结构化 Prompt 技巧
如果说前两章解决“模型怎么学”,
这一章解决的是:我们如何更好地“使用”模型?
尤其是 Chain-of-Thought 推理的出现,让模型的逻辑能力大幅提升。
很多人只会写简单提示词,但真正高级的 Prompt 设计,其实是一门工程学。
4. 对齐(Alignment):让模型更安全可控
第4章讲的是 Alignment(对齐)。

这部分是工业界的核心秘密。
主要包括:
-
Instruction Fine-Tuning(指令微调) -
基于人类反馈的对齐方法(RLHF) -
模型价值观对齐问题
很多人会问:为什么模型会“听话”?
答案就在这里。
预训练让模型学会语言,
对齐训练让模型学会“做人”。
这一步决定了模型是否:有用、可控、安全
5. 推理与加速:真正落地的关键
第5章讲的是 Inference(推理)。

很多人只关注训练,其实在实际部署中:推理成本才是最大的挑战。
这一章涉及:
-
解码算法(Greedy / Beam Search 等) -
推理加速方法 -
KV Cache -
Inference-time Scaling 问题
你会理解:
-
为什么生成速度会变慢 -
为什么上下文越长越贵 -
为什么推理优化是商业化关键
这一章非常适合做工程落地的人。
公众号回复LLM,领取原版高清PDF文件。
大厂算法工程师|写作八年累计数百万字出版《跟我一起学机器学习》|《跟我一起学深度学习》|《一本書晉升深度學習世界級大師》,深谙AI算法入门之道!订阅 知识库两个月轻松入门AI!

往期精选推荐
[1] 10大经典机器学习算法分类与总结
[2] 记住!CNN卷积操作无非也就这4种情况!
[3] 随机森林是如何进行特征重要性评估的?
[4] 为什么大模型蒸馏一定要用软标签?
[5] 全面对比贝叶斯三大算法异同!附实验结果!
[6] DistilBERT在多损失函数设计上做了哪些创新?
[7] 为什么RBF核函数能将特征映射到无穷维?
点击下图购买作者编著新书


