 夜雨聆风
夜雨聆风





用Claude秒读4000+份PDF:银登中心不良贷款数据的首次系统化挖掘
一、一个被忽略的数据富矿
银登中心(银行业信贷资产登记流转中心)是银保监会批准设立的全国性不良贷款转让业务平台。不良贷款转让虽然也可以通过ABS等方式进行(且Wind等数据商已有较好的覆盖),但银登中心的逐笔公告数据至今无人系统化整理。
自2023年不良贷款转让业务正式扩容以来,银登中心已累计发布超过4000份个人不良贷款转让公告,涵盖了国有大行、股份制银行、城商行、农商行和消费金融公司等各类金融机构。每一份公告都以PDF附件形式挂在网站上,详细列明了转让资产包的关键信息:未偿本金总额、资产笔数、借款人户数、逾期天数、五级分类、担保方式等十余个字段。
银登中心官网(https://www.yindeng.com.cn/index.html)
如果系统化整理,这些数据将是研究中国个人不良贷款转让市场最直接、最底层的一手信息源。
然而,至今几乎没有人做过这件事。这在AI时代之前,几乎是一个不可能完成的任务。4000多份PDF,要从中做到可靠的结构化提取,需要非常专业的开发支持,绝非安排实习生去”洗”数据就能解决的问题,人力去做相当于一个团队都耗在单一数据收集。而对于金融数据商而言,这个数据的受众面实在太窄,主要是部分投研人员,可能还有一些AMC从业者,那专门投入资源去做,商业上并不划算。
所以,这个数据一直是空白的。
更关键的是,银登中心自身也已停止公开发布不良贷款转让业务的汇总统计数据。这意味着,如果不从公告层面逐一提取,这些信息实际对于非会员单位处于一种”公开但不可用”的状态。
二、几小时做完传统几周的工作
整个流程可以概括为四步:自动爬取网页公告列表 → 批量下载PDF附件 → 结构化解析表格数据 → 输出标准化Excel。
技术上使用Python编写,结合Claude AI辅助开发。爬虫自动遍历银登中心网站全部分页,提取公告标题、日期和PDF下载链接;下载器以多线程并发获取全部PDF文件;解析器使用PDF表格识别库自动提取每份公告中的16个关键字段。对于少数格式特殊的PDF(约5%),通过正则表达式和AI大模型作为兜底方案,确保最大程度覆盖。全程只使用了少量的自然语言进行交互,例如启动项目:
从网站https://www.yindeng.com.cn/xxpl/xxpl_bldkzr/bldkzr_zrgg/提取PDF并且进行解析,获取关键字段,如未尝本金我们先使用10份进行测试
整个过程——从编写代码到完成4000+份PDF的全量下载和解析——耗时仅一个下午。传统人工方式完成同样的工作,保守估计需要2-3周。更重要的是,系统支持增量更新:每次运行只需几分钟即可获取最新数据,真正实现了”一次投入,持续产出”。
最终产出两个完整数据集:• 转让公告数据:2200+条有效记录,覆盖2023年1月至今的全部个人不良贷款转让公告• 转让结果数据:1300+条有效记录,包含转让完成后的受让方和成交信息
三、数据发现一:市场全景
首先来看市场整体规模的变化。
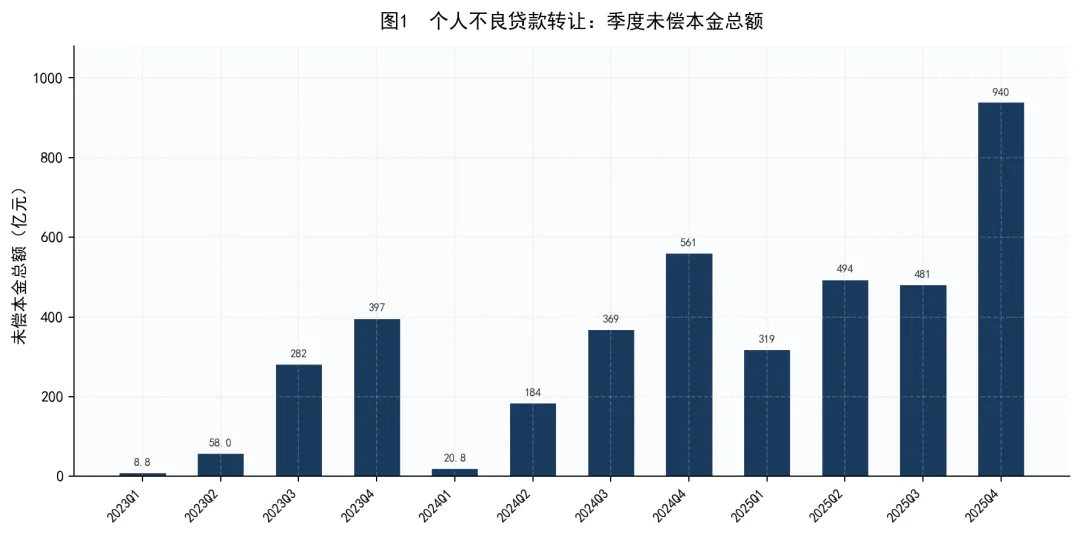
数据来源:银登中心转让公告,经结构化提取汇总。注:季度归属以初次公告日为准,与银登中心业务统计数据可能存在出入,下同。
从季度未偿本金总额来看,个人不良贷款转让市场在过去三年间呈现出显著的扩容态势。2023年第一季度,全市场转让公告涉及的未偿本金仅8.85亿元——这是不良贷款批量转让业务试点初期的水平。到2025年第四季度,这一数字已跃升至939.51亿元,增长超过100倍。
需要说明的是,这里的数据反映的是”挂牌出让规模”而非”最终成交规模”。但作为衡量市场活跃度的指标,趋势信号是非常明确的:越来越多的金融机构正在将个人不良贷款转让作为常规资产处置手段。
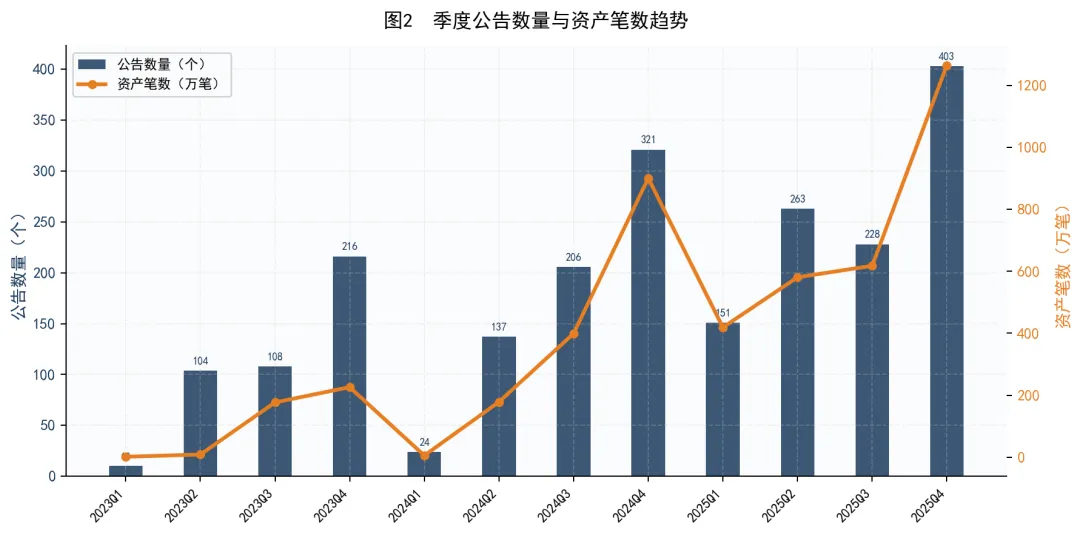
数据来源:银登中心转让公告,经结构化提取汇总
将公告数量和资产笔数放在一起看,可以发现另一个有趣的趋势:
-
公告数量从2023Q1的10个增长到2025Q4的403个,反映出参与机构和项目数量在快速扩容 -
资产笔数从1.3万笔跃升至1265万笔,增长近千倍
两者增速的差异说明:不仅参与的机构更多了,单个资产包的规模也在显著扩大。这反映出银行对不良贷款批量转让模式的接受度正在提高,转让标的正从早期的”试水型小包”向”常规化大包”转变。
另一个值得关注的现象是季度间的波动。每年第一季度通常是低点(如2024Q1仅20.81亿元),第三、四季度则是高点。这与银行年末加速不良资产出清的行业惯例一致——金融机构倾向于在年末集中处置不良资产,以优化年度报表指标。
四、数据发现二:机构分化图谱
接下来,将视角从市场整体转向具体机构——这也是本文数据最核心的价值所在。
银登中心自身发布过的业务统计数据,也仅停留在市场汇总层面,从未披露过单家机构的转让数据。而我们这次直接从4000多份公告中穿透到了机构层,逐一识别出每家机构、每个季度的转让规模——这是此前从未有过的数据维度。
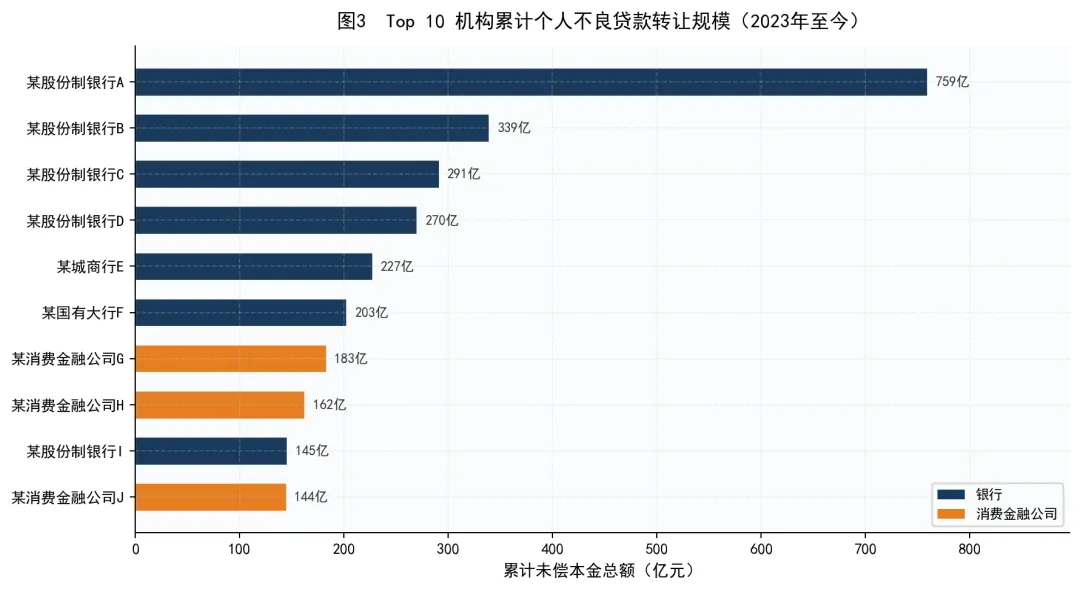
数据来源:银登中心转让公告。橙色为消费金融公司,深蓝色为银行。
从累计转让规模来看,机构之间的分化非常明显。某股份制银行A以759亿元的累计未偿本金遥遥领先,几乎是第二名某股份制银行B(339亿元)的两倍多。
排名前十的机构中,有五家是股份制银行,两家是城商行,两家是国有大行,一家是消费金融公司。这个分布本身就很有信息量——股份制银行是个人不良贷款转让最积极的参与者,而国有大行虽然不良贷款余额庞大,但通过银登中心转让的规模相对有限,这可能与国有大行自身拥有更多内部处置渠道有关。
值得特别关注的是消费金融公司的崛起。图中以橙色标注的机构即为消费金融公司,它们正在成为不良贷款转让市场的重要供给力量。
我们挑选排名前两位的机构,分别观察它们的季度转让节奏。
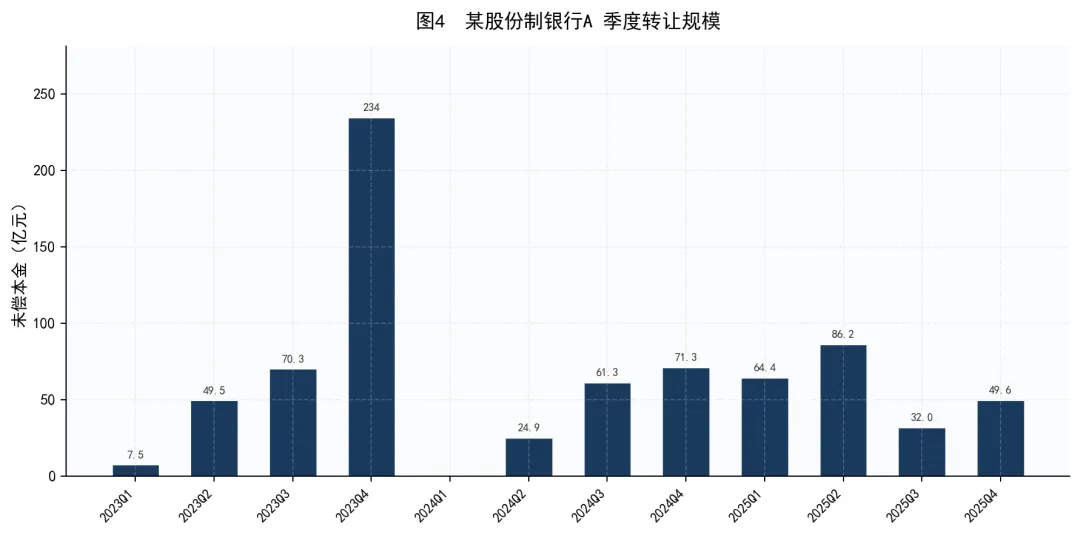
数据来源:银登中心转让公告,按初次公告日归属季度
某股份制银行A是最早的大规模参与者,也是累计转让规模最大的单一机构。从季度节奏来看,2023年下半年开始显著放量,Q4单季度更是达到234亿元的峰值。但紧接着2024Q1断崖式归零,此后逐步恢复至50-80亿元区间。这种”脉冲式启动—急停—常态化”的节奏,可能与内部额度审批、资产质量集中暴露等因素有关。
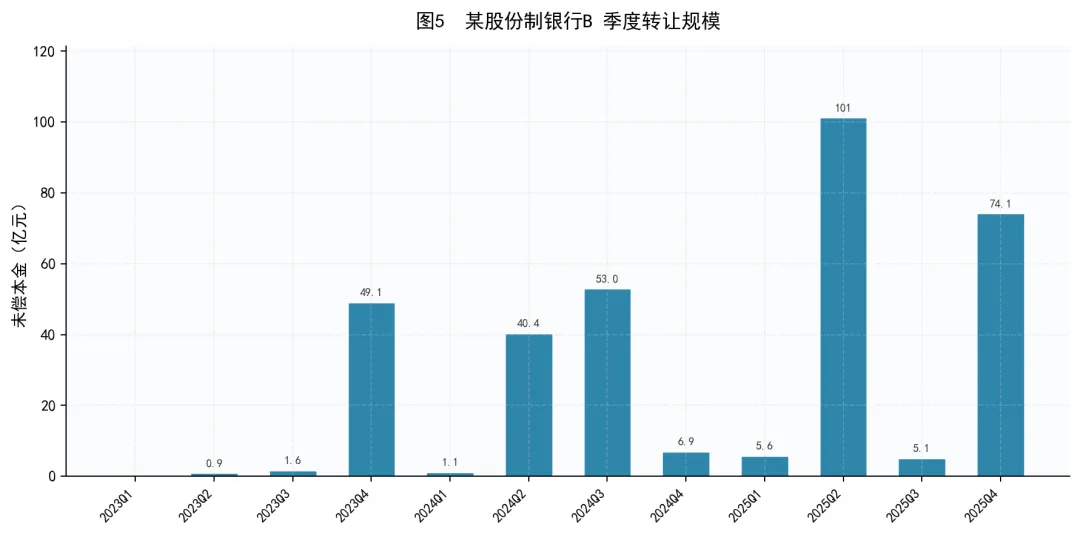
数据来源:银登中心转让公告,按初次公告日归属季度
某股份制银行B则呈现典型的脉冲式出清模式:转让规模在0-5亿元和40-100亿元之间剧烈波动,每隔几个季度集中出货一次,幅度差异极大。2025Q2单季度达到101亿元的历史高点,而紧邻的Q3仅有5亿元。这种节奏表明该机构可能采取了”攒批集中转让”的策略,而非持续出清。
这些差异反映了各机构在不良资产处置策略、内部审批流程以及资产质量管理节奏方面的不同选择。对于关注特定机构的投研人员而言,这种季度级别的转让时序数据,是此前无法获取的新维度信息。
五、数据发现三:消费金融公司专题
消费金融公司是近年来不良贷款转让市场最值得关注的新力量。我们选取三家转让规模最大的消费金融公司,单独观察它们的季度转让节奏。
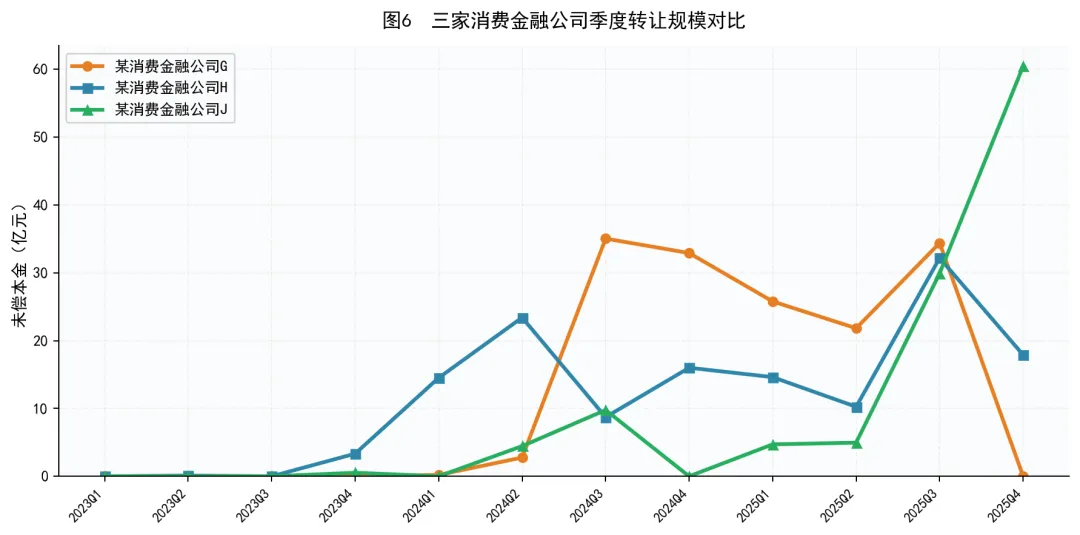
数据来源:银登中心转让公告
三家公司的转让节奏迥异:
- 某消费金融公司G
从2024年第二季度开始参与转让,此后在20-35亿元区间维持稳定的季度转让规模,表现出常态化处置的特征 - 某消费金融公司H
参与最早(2023年第二季度即有小规模尝试),此后保持每季度10-30亿元的转让频率,呈现稳健波动型 - 某消费金融公司J
起步较晚但增速惊人,从2024年的个位数迅速攀升,2025年第四季度单季度转让规模达到60.46亿元,为三家之最,呈现典型的后来居上态势
作为一个数据观察,不良贷款转让行为本身可以作为研判金融机构资产质量变化的前瞻性指标之一。当某家机构的转让规模突然放大时,往往值得关注其背后的业务发展和资产质量动因。
需要强调的是,不良贷款转让是正常的资产处置行为,转让规模大不等于资产质量差。部分机构可能是主动加速出清以优化资产负债表,而非被动应对不良攀升。我们仅呈现数据事实,不做信用层面的评价。
六、结语:研究边界的拓展
回过头来看,这个项目真正的起点既不是代码也不是AI,而是一个具体的问题:各家机构的不良贷款转让情况究竟是什么样的?有了这个问题,工具和方法只是手段,而手段在今天已经不是瓶颈了。
这或许是AI时代做研究最深刻的变化。当数据的获取和处理不再构成壁垒,真正稀缺的东西就浮出水面了——你到底想研究什么?说实话,我自己也常常陷入这种困境:手握越来越强的工具,却不确定该拿它们去解决什么问题。工具越强大,”找到正确的问题”反而变得越重要。
类似银登中心这样”一直在那里但没人整理”的数据,在金融研究中其实随处可见——裁判文书、产权交易所挂牌信息、监管处罚公告——方法是通用的,但前提永远是:你得先知道自己在找什么,为什么要找这些数据,他们用来说明什么问题?这篇文章算是一个样本。如果它能让你想到自己领域里类似的数据富矿,那它的价值就不止于不良贷款本身了。
另外由于数据可能用于内部深度报告,这篇暂时先不发布数据集。
数据说明:本文所有数据均来源于银登中心(yindeng.com.cn)公开发布的个人不良贷款转让公告,经自动化程序结构化提取汇总。文中所有机构名称均做化名处理。季度归属以公告初次发布日期为准。免责声明:本文仅做数据展示和客观分析,不构成任何投资建议,亦不对任何机构做信用评价。
