 夜雨聆风
夜雨聆风





R绘图 | 解决pdf保存时中文字体乱码问题
点击蓝字 关注我们
(本文字数:2622字 阅读时间:10分钟)

背景介绍
年前写项目报告写的头疼,特别是以往论文发表都是英文图片,但是项目报告要求中文字体,保存时常常出错。年后有空了就想着在这个方向学习一下。
其实,R内置的字体是PostScript字体,但是这其中包含的字体有限,特别是不包含中文字体。在绘制图片并保存为pdf文件,会出现乱码,导致保存的图片出现问题。本文简要介绍如何正确保存含中文字体的图片为pdf,期望能借此机会和大家一起学习一下~

R内置的有什么字体
R内置的字体是PostScript字体,其具体包含什么字体可以用下面的代码看:
names(pdfFonts())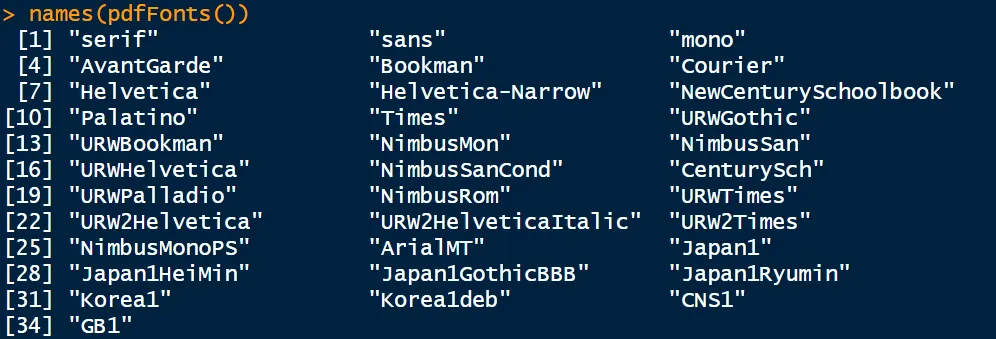
(可能不同人的结果不太一样哈,不过我的电脑出来是这样的)
其实系统内包含的字体有很多,大家在word中可以看到丰富的中文字体,比如黑体、仿宋、宋体等等,这些R是不包含的,所以在保存图片时无法使用这些字体,会显示出代码。
绘制的图片保存为pdf常见的有两个函数,如下:
pdf() #属于R基础包,无需额外安装ggsave() #属于ggplot2包
下面我们绘制一个图片,通过对不不同的保存方法,尝试将包含中文字体的图片保存为正常的pdf文件,来解答一下哪种方式最为简便且有效。

不同方式保存为正常的pdf
我们首先生成一组数据,并用此数据绘制图片,代码如下:
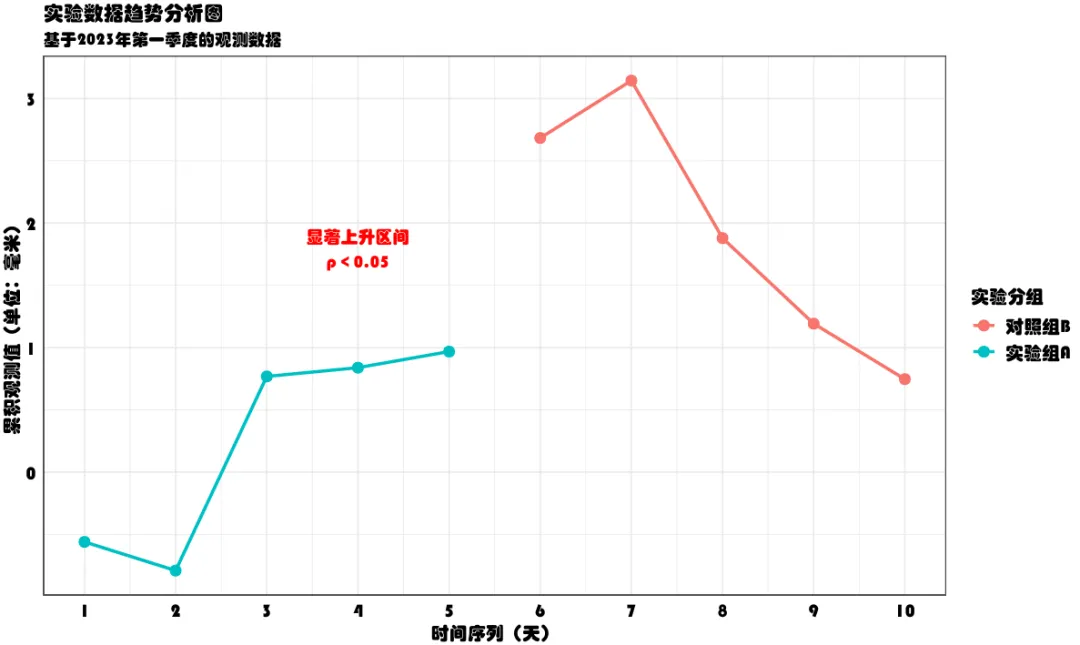
# 加载必要的包library(ggplot2)# 创建示例数据set.seed(123)data <- data.frame(x = 1:10,y = cumsum(rnorm(10)),group = rep(c("实验组A", "对照组B"), each = 5))# 创建一个包含多种中文位置的复杂图形p <- ggplot(data, aes(x = x, y = y, color = group)) +geom_line(size = 1) +geom_point(size = 3) +# 1. 图表主标题(最常用的中文位置)labs(title = "实验数据趋势分析图",subtitle = "基于2023年第一季度的观测数据",# 2. 坐标轴标签x = "时间序列(天)",y = "累积观测值(单位:毫米)",# 3. 图例标题color = "实验分组") +# 4. 图例项(已在数据中:实验组A/对照组B)# 5. 文本标注annotate("text", x = 4, y = 1.8,label = "显著上升区间\np < 0.05",size = 4, color = "red") +# 6. 刻度标签(如果x轴是中文的话)scale_x_continuous(breaks = 1:10) +# 主题设置theme_minimal() +theme(axis.line = element_line(colour = 'gray30'),legend.position = "right",axis.text.x = element_text(color="black", size =12, vjust = 1),axis.text.y = element_text(color="black", size =12, hjust = 1),axis.title.x = element_text(color="black", size=12),axis.title.y = element_text(color="black", size=12),legend.title = element_text(color="black", size=12),legend.text = element_text(color="black", size=12),panel.border = element_rect(fill=NA,color="gray30", size=0.5, linetype="solid"))# 显示图形print(p)
绘制出的图片如下,可以看出图片的标题、x轴和y轴的轴标题、图例以及坐标轴内均包含中文文字,这是适合进一步探究如何将含中文字体的图片保存为pdf的。
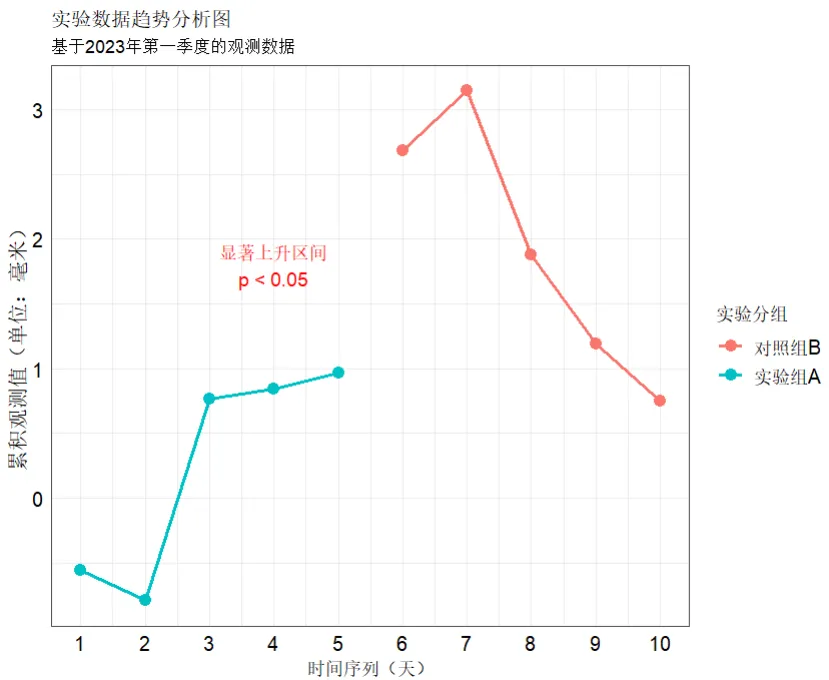
下面我们开始讨论用不同的方法将图片保存为pdf:
方法1:最基础的保存方法
pdf函数是R内置的函数,可以直接将绘制的图片保存为pdf格式,其函数如下:
pdf("test1_basic.pdf", width = 10, height = 6)print(p)dev.off()
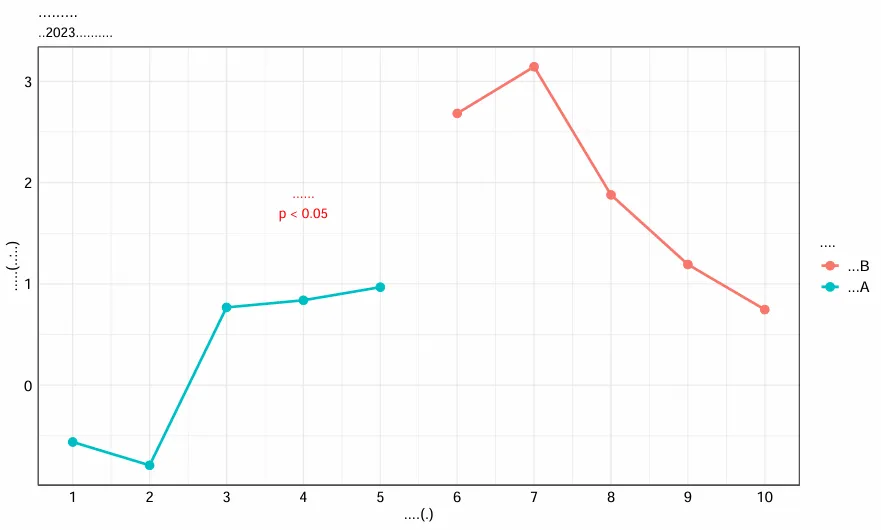
可以看出简单地用pdf函数保存图片时,中文字体都会用“.”替换掉,因此不能这样保存。
方法2:采用Windows系统常用中文字体
上面是pdf函数的简单设置,该函数其实还能够直接设置保存时使用的字体。我在查看R内置的字体后,发现GB1还是适合中文字体的,可以正常输出,具体如下:
#查看Windows系统中R可用的字体,填入pdf函数参数names(pdfFonts())#根据此前的结果,我选择最可能适用于中文字体的GB1(国标1)pdf("test2_chinese_font.pdf", width = 10, height = 6,family = "GB1") # 根据可用字体选择其中之一print(p)dev.off()
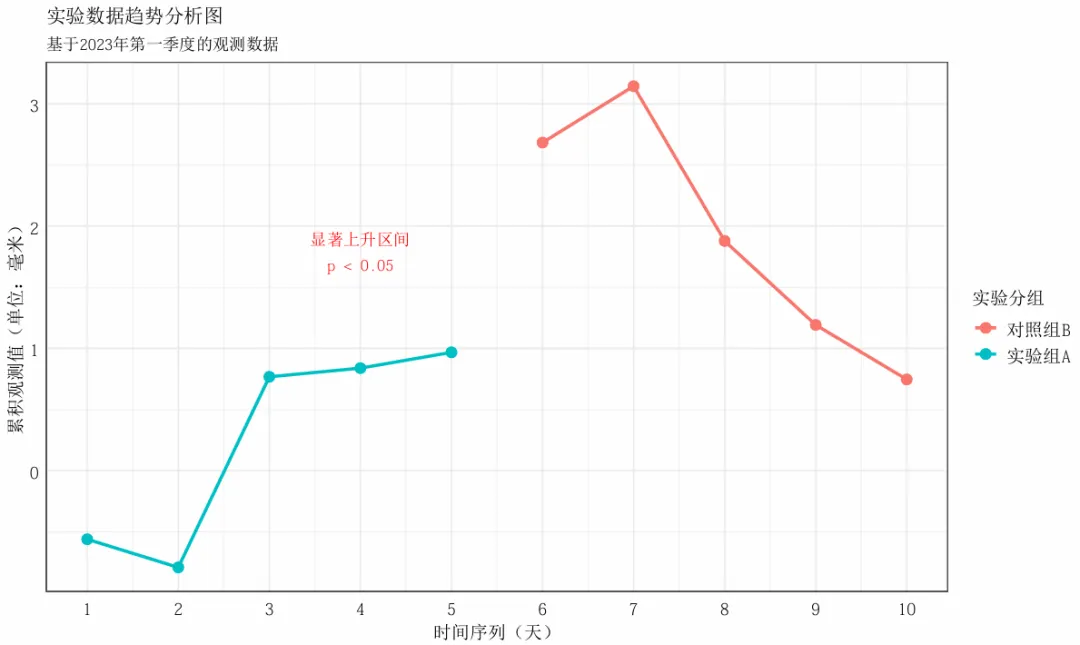
可以看出,采用GB1的字体可以正常保存为pdf文件,是适合中文字体的。
方法3:直接使用Cairo设备
Cairo设备是R基于Cairo图形库的一系列图形输出设备,用来替代R的基础图形设备,能够提供了高质量的2D渲染能力。简单来说,它是一个更现代、功能更强大的图形引擎。
Cairo_pdf函数可以直接使用系统内已经安装的中文字体,我们在下面的代码中尝试使用“黑体”。如果能够成功保存,这样可以在图片中看出和之前不同的。
cairo_pdf("test3_cairo.pdf", width = 10, height = 6,family = "SimHei") # 指定系统内存在的中文字体即可print(p)dev.off()
我们用上面的代码,绘制图片如下:
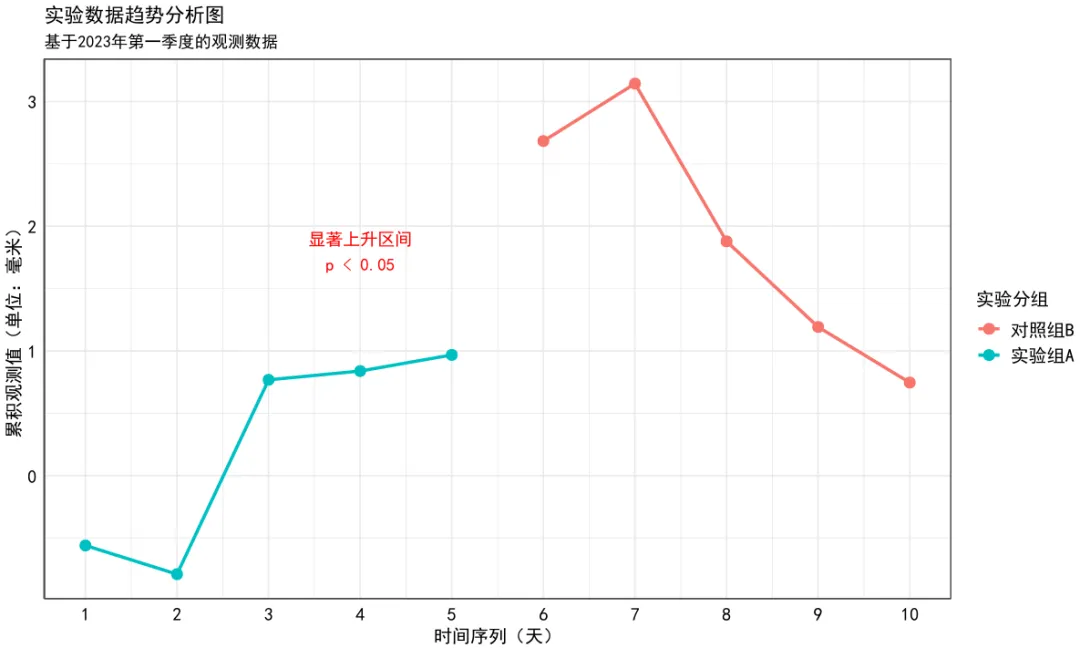
可以看出,这样的话已经能够用黑体保存为pdf文件了。
方法4:ggsave也可调用cairo设备
ggsave("test4_ggsave_cairo.pdf", p, width = 10, height = 6,device = cairo_pdf, # 默认使用pdf(),不是cairo_pdf()family = "STSong")
ggsave函数中可以通过device参数设置调用的设备。如果不设置这一参数,默认的是使用pdf函数设置,只能调用R内置的字体。但是如果设置device参数为cairo_pdf,这时使用的是cairo设备,可以调用系统内已经安装的中文字体。我们在这里调用了宋体,得到的结果如下:
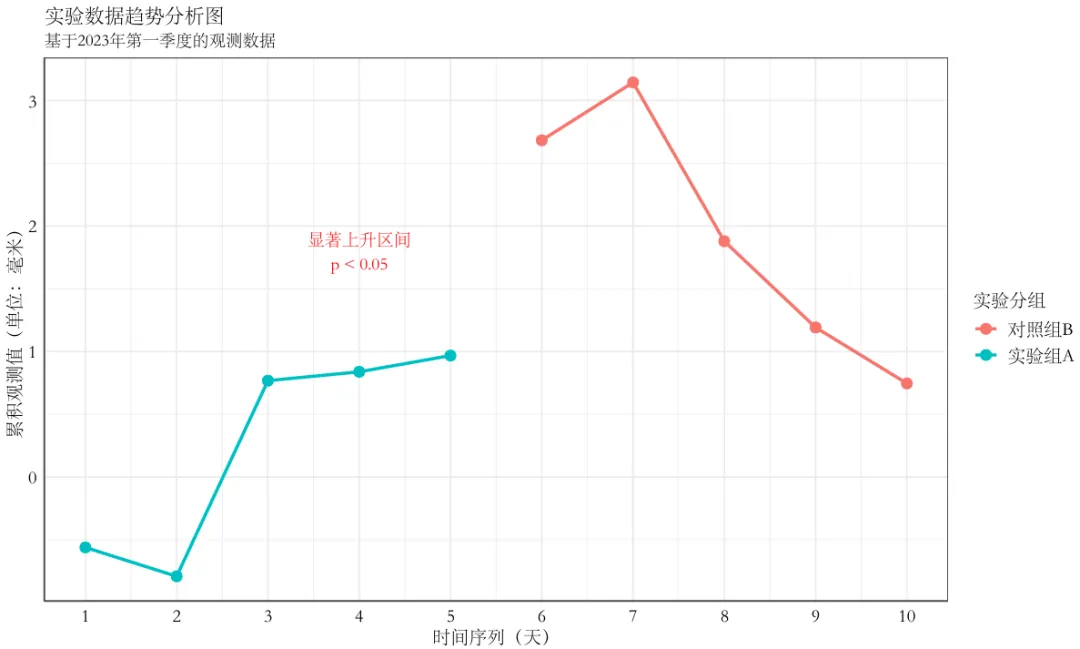
可以看到也能够正常保存含有中文字体的图片。
方法5:showtext包
showtext包是专门开发用于解决R语言字体问题,尤其是中文字体。无论是电脑里安装的黑体、宋体,还是从网上下载的 artistic 字体,甚至Google Fonts上的在线字体,showtext都能让你在R中直接调用,并且能够确保图形在任何电脑上打开时都能原样显示,不再出现乱码或字体缺失的问题。
showtext包不是简单地在PDF文件中“描述”文字信息,而是把每个文字的轮廓转换成图形中的多边形(矢量图)或图片(位图)。这意味着,你把做好的PDF发给别人,即使对方的电脑里没有安装你使用的字体,对方打开文件时看到的文字样子也和你看到的的一模一样,绝不会变成乱码或默认字体。
在R中使用showtext包通常需要四/三步:
1、加载并添加系统字体:font_add(“myFont”, “simhei.ttf”) 函数中需要知道字体文件所在的路径和名字,一般路径在“C:/Windows/Fonts/”下,特别是在Fonts的文件下(或者也可以使用Google在线字体:font_add_google (“Noto Sans SC”, “myFont”),这样无需查找本地字体文件)。
2、开启全局开关:运行 showtext_auto()使得R里的所有图形设备的文字绘制工作都交给showtext来处理。
3、正常绘图并保存:之后就可以像平常一样使用ggplot2或基础绘图系统画图,并在需要指定字体的地方(如family = “myFont”)使用你第一步添加的字体名称。最后用ggsave()或pdf()保存即可,一切都会正常工作。
4、停止使用showtext(可选):运行showtext_ auto(FALSE),暂停该功能。
# 安装并加载showtext#install.packages("showtext")library(showtext)# 第一步:添加中文字体,需要知道字体文件的路径和名字font_add("SimSun", "C:/Windows/Fonts/SimSun.ttc")# 第二步:启用showtextshowtext_auto()#第三步:绘制指定字体的图片并保存pdf("test5_showtext.pdf", width = 10, height = 6)p <- ggplot(data, aes(x = x, y = y, color = group)) +geom_line(size = 1) +geom_point(size = 3) +# 1. 图表主标题(最常用的中文位置)labs(title = "实验数据趋势分析图",subtitle = "基于2023年第一季度的观测数据",# 2. 坐标轴标签x = "时间序列(天)",y = "累积观测值(单位:毫米)",# 3. 图例标题color = "实验分组") +# 4. 图例项(已在数据中:实验组A/对照组B)# 5. 文本标注annotate("text", x = 4, y = 1.8,label = "显著上升区间\np < 0.05",size = 4, color = "red") +# 6. 刻度标签(如果x轴是中文的话)scale_x_continuous(breaks = 1:10) +# 主题设置,在这里对字体进行设置theme_minimal() +theme(axis.line = element_line(colour = 'gray30'),legend.position = "right",axis.text.x = element_text(color="black", size =12, vjust = 1),axis.text.y = element_text(color="black", size =12, hjust = 1),axis.title.x = element_text(color="black", size=12,family = "SimSun"),axis.title.y = element_text(color="black", size=12,family = "SimSun"),legend.title = element_text(color="black", size=12,family = "SimSun"),legend.text = element_text(color="black", size=12,family = "SimSun"),panel.border = element_rect(fill=NA,color="gray30", size=0.5, linetype="solid"))print(p)dev.off()# 第四步:关闭showtextshowtext_auto(FALSE)
我们在绘制上述图形时,将图例标题和内容的字体设置为了宋体,另外将x和y轴的轴标题的字体也设置为了宋体,这样也能更清晰的看出与此前图片的区别。绘制出的图片如下,可以看出同样能够实现对字体的控制:
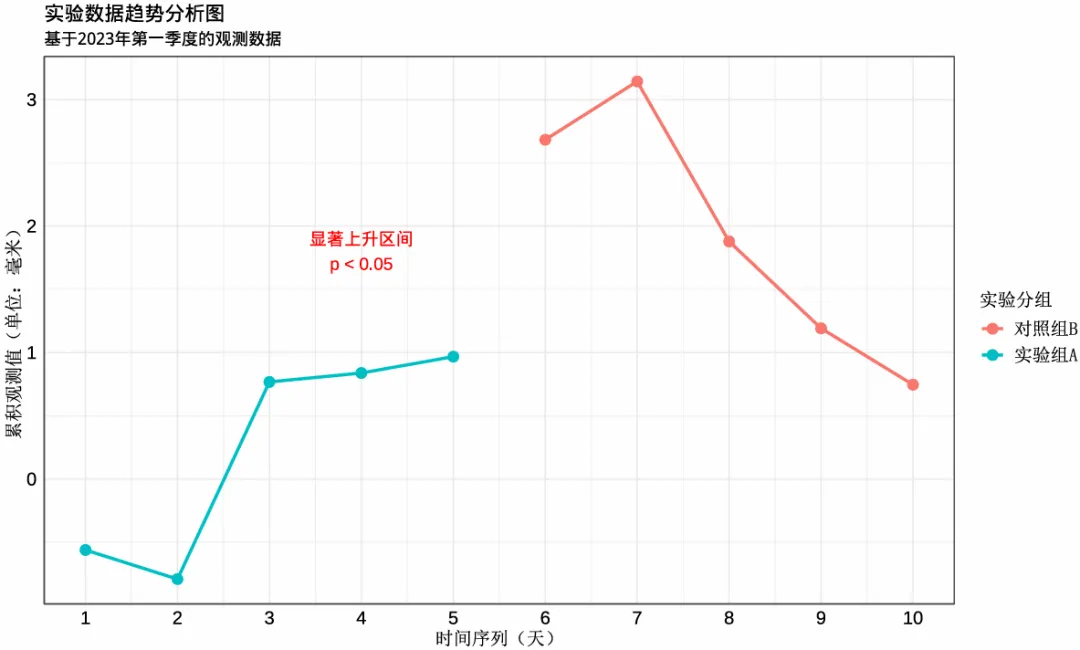
方法5.5:使用extrafont包
该方法称之为5.5是因为这个包对于中文字体其实并不友好,当真正调用中文字体时仍然会出现报错,最终还是需要依赖cairo设备保存。
但之所以介绍这个包,是因为尽管extrafont包和showtext包的功能相似,但也各有特点。extrafont包的思路是把系统字体注册到R中,让R能识别和使用它们,最终生成的PDF仍然依赖于字体的嵌入,如果嵌入失败,在其他电脑上查看还是可能出问题。extrafont包的优势就在于,当我们后期想要借助Adobe Illustrator等软件对图片进行进一步修改润色时,可能会更加友好。而showtext不依赖于字体的嵌入,跨平台兼容性更好,使用起来更简单、更现代,但是当我们想要后期编辑时,只能以图片的形式处理文字。
# 安装并加载extrafont#install.packages("extrafont")library(extrafont)#安装Ghostscript(下载地址:https://www.ghostscript.com/download/gsdnld.html)#设置Ghostscript路径(Windows版)Sys.setenv(R_GSCMD = "D:/GPL/gs10.06.0/bin/gswin64c.exe")# 验证是否设置成功tools::find_gs_cmd() # 应该返回上面设置的路径#导入系统字体(只需运行一次)font_import() #需要5-10分钟#如果只想导入特定字体,可使用pattern参数# font_import(pattern = "sim|msyh") # 只导入中文字体fonts() # 列出所有已导入字体#将导入的字体注册到R的PDF/PostScript设备中,让R知道这些字体可用loadfonts()#查看可用中文字体fonts()[grep("hu|hei|song|kai|yahei", fonts(), ignore.case = TRUE)]#使用extrafont导入的字体pdf("test6_extrafont.pdf", width = 10, height = 6,family = "STHupo") # 使用font_import()后识别的字体名p <- ggplot(data, aes(x = x, y = y, color = group)) +geom_line(size = 1) +geom_point(size = 3) +labs(title = "实验数据趋势分析图",subtitle = "基于2023年第一季度的观测数据",x = "时间序列(天)",y = "累积观测值(单位:毫米)",color = "实验分组") +annotate("text", x = 4, y = 1.8,label = "显著上升区间\np < 0.05",size = 4, color = "red") +scale_x_continuous(breaks = 1:10) +# 主题设置theme_minimal() +theme(axis.line = element_line(colour = 'gray30'),legend.position = "right",axis.text.x = element_text(color="black", size =12, vjust = 1),axis.text.y = element_text(color="black", size =12, hjust = 1),axis.title.x = element_text(color="black", size=12),axis.title.y = element_text(color="black", size=12),legend.title = element_text(color="black", size=12),legend.text = element_text(color="black", size=12),panel.border = element_rect(fill=NA,color="gray30", size=0.5, linetype="solid"))print(p)dev.off()
可以看到保存的字体已经变了,是琥珀体了,但是字体全部杂糅的一起了,还是存在问题(有大佬知道如何解决欢迎评论区分享,谢谢)
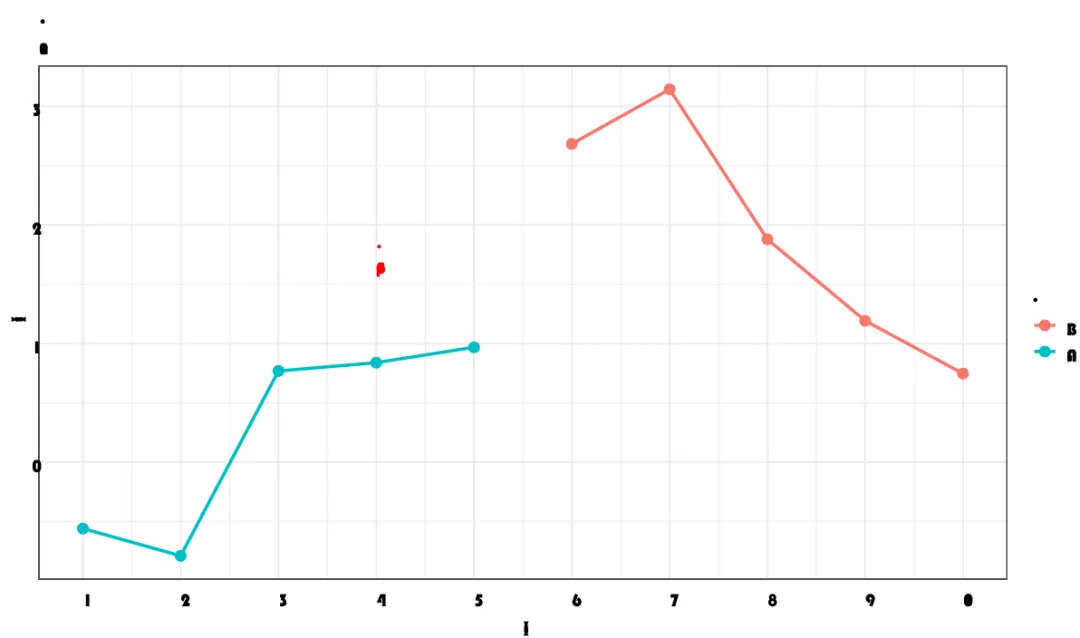
#最终还是妥协了,用ggsave保存ggsave("test6_ggsave_cairo.pdf", p, width = 10, height = 6,device = cairo_pdf, family = "STHupo")
如果用ggsave加cairo设备之后就能够正常保存了,结果如下:

最终选择
整体来看,最简便的方法还是直接使用方法四最为简便,仅需使用ggsave函数并设置设备为“cairo_pdf”以及具体需要用到的字体(如下)。
ggsave("test4_ggsave_cairo.pdf", p, width = 10, height = 6,device = cairo_pdf, # 默认使用pdf(),不是cairo_pdf()family = "STSong")
