 夜雨聆风
夜雨聆风





OpenClaw源码解读之记忆系统

OpenClaw 的记忆系统为 Agent 提供跨会话的长期知识检索能力。它本质上是一个嵌入式 RAG 引擎——将 Markdown 笔记和历史会话分块、向量化后存入 SQLite,查询时同时走向量搜索和全文搜索,最终用加权融合产出排序结果。整个系统不依赖任何外部向量数据库,单个 SQLite 文件即可运行。
一、数据模型:五张表撑起全部状态
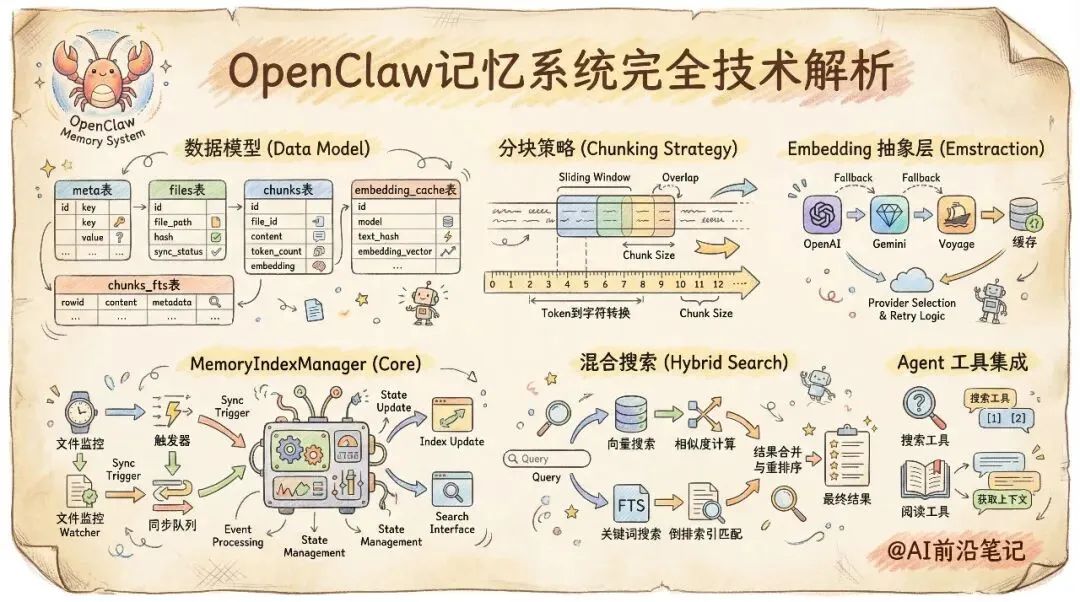
`ensureMemoryIndexSchema` 负责建表,数据库中共有五张关键表:
// src/memory/memory-schema.tsparams.db.exec(`CREATE TABLE IF NOT EXISTS meta (key TEXT PRIMARY KEY, value TEXT NOT NULL);CREATE TABLE IF NOT EXISTS files (path TEXT PRIMARY KEY, source TEXT NOT NULL DEFAULT 'memory',hash TEXT NOT NULL, mtime INTEGER NOT NULL, size INTEGER NOT NULL);CREATE TABLE IF NOT EXISTS chunks (id TEXT PRIMARY KEY, path TEXT NOT NULL, source TEXT NOT NULL DEFAULT 'memory',start_line INTEGER NOT NULL, end_line INTEGER NOT NULL,hash TEXT NOT NULL, model TEXT NOT NULL,text TEXT NOT NULL, embedding TEXT NOT NULL, updated_at INTEGER NOT NULL);`);
-
meta:键值存储,记录当前使用的 embedding model、维度等元信息
-
files:已索引文件的路径、hash、修改时间,用于增量同步时判断文件是否变更
-
chunks:文本块,存储原文、行号范围和 embedding 向量(JSON 序列化的 `number[]`)
-
embedding_cache:embedding 缓存表,主键为 `(provider, model, provider_key, hash)`,避免对相同文本重复调用 API
-
chunks_fts:FTS5 虚拟表,用于全文搜索;**chunks_vec**:sqlite-vec 虚拟表,用于向量近邻搜索
FTS5 和 sqlite-vec 都是 SQLite 扩展,可能在某些环境下不可用。代码对此做了优雅降级——如果 FTS5 创建失败,`ftsAvailable` 设为 `false`,搜索时跳过关键词通道;如果 sqlite-vec 不可用,向量搜索退化为内存中的 `cosineSimilarity` 暴力扫描。
二、分块策略:带重叠的滑动窗口
文件被读取后需要切分为适合 embedding 的文本块。`chunkMarkdown` 实现了一个基于字符数的滑动窗口分块器:
// src/memory/internal.tsexport function chunkMarkdown(content: string,chunking: { tokens: number; overlap: number },): MemoryChunk[] {const maxChars = Math.max(32, chunking.tokens * 4);const overlapChars = Math.max(0, chunking.overlap * 4);// ... 逐行累积,超过 maxChars 时 flush 并保留尾部 overlap}
`tokens * 4` 是一个粗略的 token-to-char 换算(英文约 1 token ≈ 4 chars)。当一个块的字符数超过上限时,先 flush 当前块,然后用 `carryOverlap` 从块尾部保留一定字符量作为下一块的开头,确保块与块之间有语义上的重叠,不会因为硬切断而丢失上下文。
对于会话文件(JSONL 格式),`buildSessionEntry` 先将 JSON 行解析为 user/assistant 消息对的纯文本,再交给分块器处理。分块后通过 `remapChunkLines` 将内容行号映射回原始 JSONL 文件行号,保证引用定位的准确性。
三、Embedding 抽象层与多 Provider 支持
`EmbeddingProvider` 接口只有两个方法——`embedQuery` 和 `embedBatch`:
// src/memory/embeddings.tsexport type EmbeddingProvider = {id: string;model: string;maxInputTokens?: number;embedQuery: (text: string) => Promise<number[]>;embedBatch: (texts: string[]) => Promise<number[][]>;};
`createEmbeddingProvider` 根据配置选择具体实现(OpenAI、Gemini、Voyage、本地模型),并内置了 fallback 策略:如果首选 provider 初始化失败(例如缺少 API key),自动切换到备选 provider。所有返回的向量都经过 `sanitizeAndNormalizeEmbedding` 做 L2 归一化,确保余弦距离计算的一致性。
每个 provider 还支持 **Batch API**——通过 `batch-openai.ts`、`batch-gemini.ts`、`batch-voyage.ts` 提交大批量 embedding 请求。Batch API 是异步的:提交任务后轮询状态直到完成,适合首次索引大量文件的场景。如果 batch 失败,系统自动回退到逐条请求。
四、MemoryIndexManager:核心编排器
`MemoryIndexManager` 是整个系统的中枢,通过静态方法 `get` 获取实例(带实例级缓存):
// src/memory/manager.tsstatic async get(params: { cfg, agentId }): Promise<MemoryIndexManager | null> {const settings = resolveMemorySearchConfig(cfg, agentId);if (!settings) return null;const key = `${agentId}:${workspaceDir}:${JSON.stringify(settings)}`;const existing = INDEX_CACHE.get(key);if (existing) return existing;const providerResult = await createEmbeddingProvider({ ... });const manager = new MemoryIndexManager({ ... });INDEX_CACHE.set(key, manager);return manager;}
构造时完成四件事:打开 SQLite 数据库、建表、启动文件监听器(chokidar)和会话事件监听器。chokidar 监控工作区的 `memory/` 目录和额外配置路径,文件变更时标记 `dirty = true`;会话监听器通过 `onSessionTranscriptUpdate` 订阅 transcript 写入事件,追踪 `sessionsDirtyFiles`。
同步由多种触发条件驱动:文件变更防抖、定时轮询(`ensureIntervalSync`)、搜索前检查(`sync.onSearch`)、会话开始时预热(`warmSession`)。所有触发最终汇聚到 `sync()` 方法,它内部通过 `this.syncing` Promise 实现去重——如果已有同步在进行,直接复用其 Promise,避免并发索引。
五、混合搜索:向量 + 关键词融合
搜索是记忆系统的核心输出。`search` 方法同时发起两路查询:
向量搜索(`searchVector`)将查询文本 embedding 后,通过 sqlite-vec 的 `vec_distance_cosine` 做近邻查找:
SELECT c.id, c.path, c.start_line, c.end_line, c.text, c.source,vec_distance_cosine(v.embedding, ?) AS distFROM chunks_vec v JOIN chunks c ON c.id = v.idWHERE c.model = ? ORDER BY dist ASC LIMIT ?
得分为 `1 – dist`(距离越小,相似度越高)。如果 sqlite-vec 不可用,退化为加载全部 chunks 到内存做 `cosineSimilarity` 暴力计算。
关键词搜索(`searchKeyword`)通过 FTS5 做全文匹配。`buildFtsQuery` 将用户查询拆分为 token 后用 `AND` 连接,`bm25RankToScore` 将 BM25 排名转为 0-1 分数:
// src/memory/hybrid.tsexport function bm25RankToScore(rank: number): number {return 1 / (1 + Math.max(0, rank));}
两路结果在 `mergeHybridResults` 中融合——按 chunk ID 做 union,对同一个 chunk 的向量分数和关键词分数做加权求和:
const score = vectorWeight * entry.vectorScore + textWeight * entry.textScore;默认权重通常为向量 0.7 + 关键词 0.3,最终按融合分数降序排列,截取 `maxResults` 条、过滤 `minScore` 以下的结果返回。候选数量通过 `candidateMultiplier` 放大(默认对 `maxResults` 乘以一个系数),确保融合后有足够的高质量结果。
六、Agent 工具集成
Agent 通过两个工具访问记忆系统(`src/agents/tools/memory-tool.ts`):
-
memory_search:语义搜索,Agent 传入自然语言查询,返回匹配的文本片段和引用信息
-
memory_get:定点读取,根据路径和行号范围读取原始文件内容
这两个工具在 Agent 运行前由 `createOpenClawCodingTools` 按策略决定是否注入。搜索结果可以附带引用标记(`citations` 模式),方便 Agent 在回复中引用来源。
小结
OpenClaw 的记忆系统用一个 SQLite 文件实现了完整的 RAG 管线:Markdown/会话分块 → 多 provider embedding → 向量+全文双索引 → 加权混合搜索。增量同步、embedding 缓存和 batch API 控制了运行成本,而 sqlite-vec/FTS5 的优雅降级保证了在各种环境下都能工作。这是一个典型的”零外部依赖向量数据库”设计,所有状态自包含在本地文件中。
下面是讲解项目的基本信息:
-
项目地址:https://github.com/openclaw/openclaw
-
使用的项目分支是:main
-
commit版本是:f5160ca6becaeeb6a4dfd892fffd2130a696f766
讲解模块和顺序如下:
1. CLI 框架与进程模型
2. 配置系统
3. Gateway 核心
4. 通道与路由
5. Agent 引擎
6. 自动回复管线
7. 插件系统
8. 记忆系统(今日讲解)
9. Web 控制台
10. 原生客户端
11. 浏览器自动化
12. 运维与测试
