 夜雨聆风
夜雨聆风





MicroGPT 源码剖析(二):预训练数据处理与分词器

源码之前,了无秘密。
《STL源码剖析》 By 侯捷
MicroGPT 是 AI 大神 Andrej Karpathy 纯手搓的极简 GPT(Generative Pre-trained Transformer)实现——用 200 行纯 Python(无任何外部依赖)完成了完整的 Transformer 训练与推理流程。
-
1、MicroGPT 源码剖析(一):全局流程总览 Karpathy 200行 Python 代码实现的极简 GPT -
2、数据处理与分词器 -
3、自动微分引擎 -
4、模型架构详解 -
5、训练循环与优化器 -
6、推理与文本生成
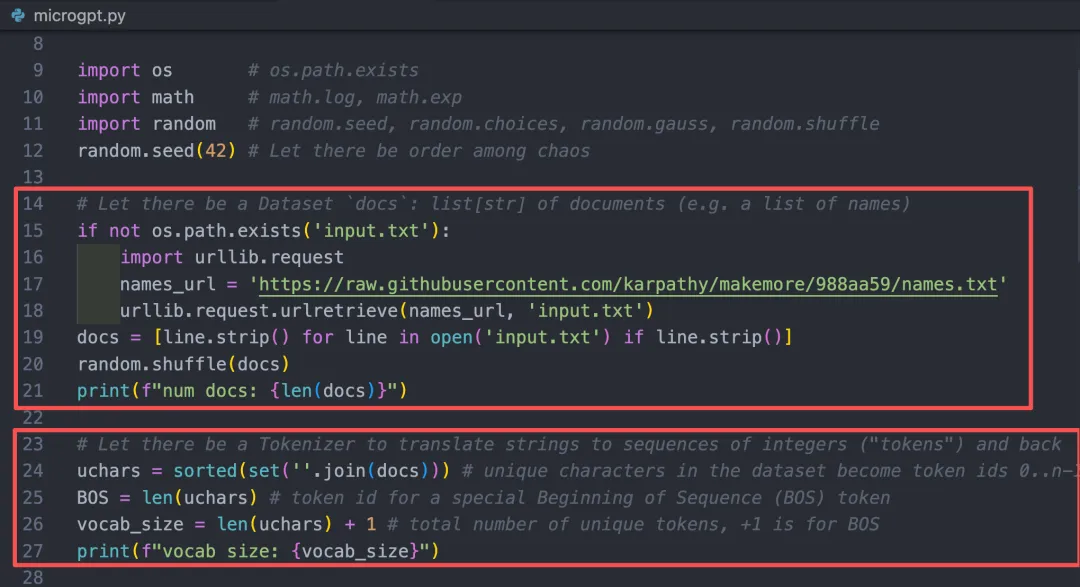
# Let there be a Dataset `docs`: list[str] of documents (e.g. a list of names)if not os.path.exists('input.txt'):import urllib.requestnames_url = 'https://raw.githubusercontent.com/karpathy/makemore/988aa59/names.txt'urllib.request.urlretrieve(names_url, 'input.txt')docs = [line.strip() for line in open('input.txt') if line.strip()]random.shuffle(docs)print(f"num docs: {len(docs)}")
源码:第23行-27行
# Let there be a Tokenizer to translate strings to sequences of integers ("tokens") and backuchars = sorted(set(''.join(docs))) # unique characters in the dataset become token ids 0..n-1BOS = len(uchars) # token id for a special Beginning of Sequence (BOS) tokenvocab_size = len(uchars) + 1 # total number of unique tokens, +1 is for BOSprint(f"vocab size: {vocab_size}")
2.1 什么是分词(Tokenization)
首先来思考一个问题:什么是分词?
由于模型不能直接理解文字,只能处理数字。分词就是把文本转换成数字序列的过程。
MicroGPT 使用最简单的分词方式——字符级分词:每个字符对应一个整数编号(这点和 ASCII 码的思路是一致的,不同的是字符级分词的编码值按排序顺序从 0 开始紧密编排,词表尽可能小 – 极简目标)。
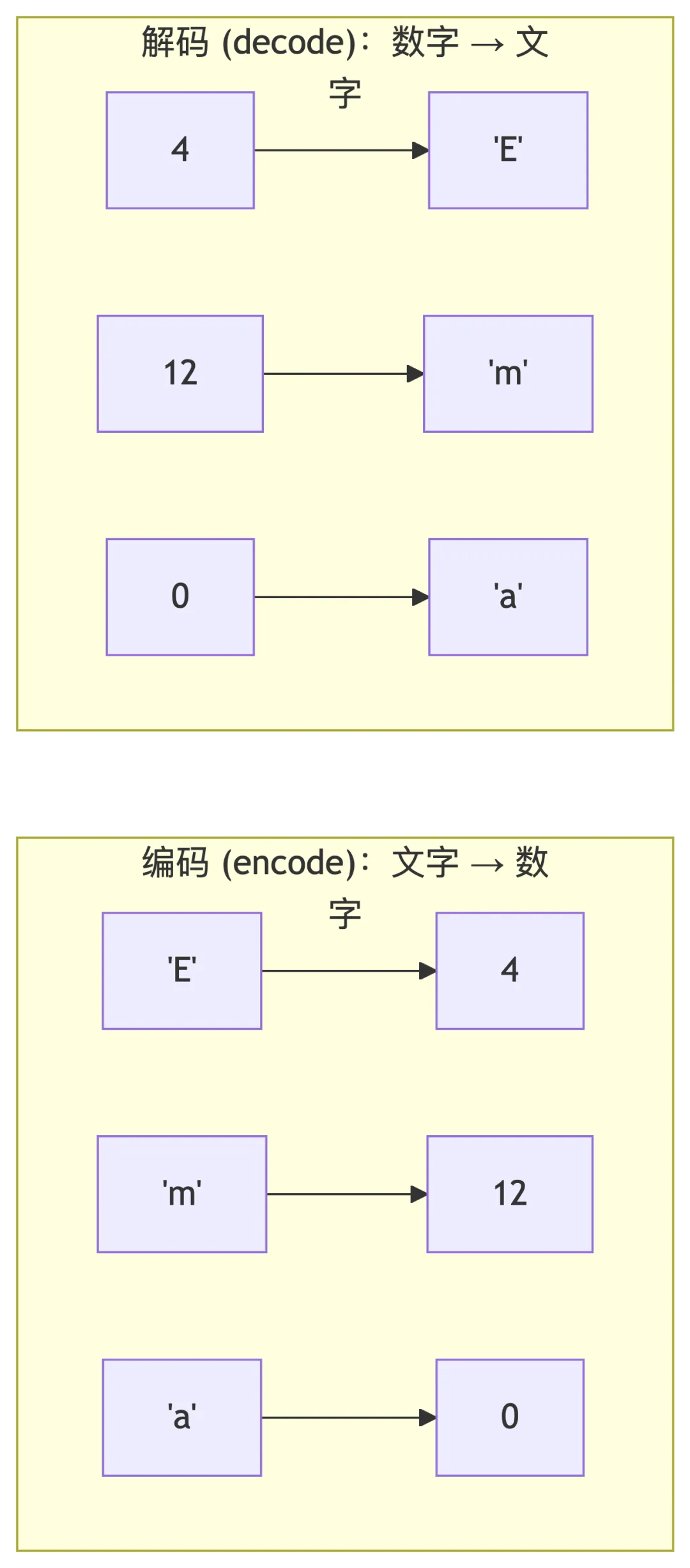
如 a 对应 0,E 对应 4(不区分大小写),26 个字母对应 0-25。
虽然 MicroGPT 的字符级分词器是最简单的分词方案。但是了解它后,理解更复杂的分词器如 BPE (Byte Pair Encoding)分词(GPT-2/3/4 使用的生产级分词方案)也会更容易:
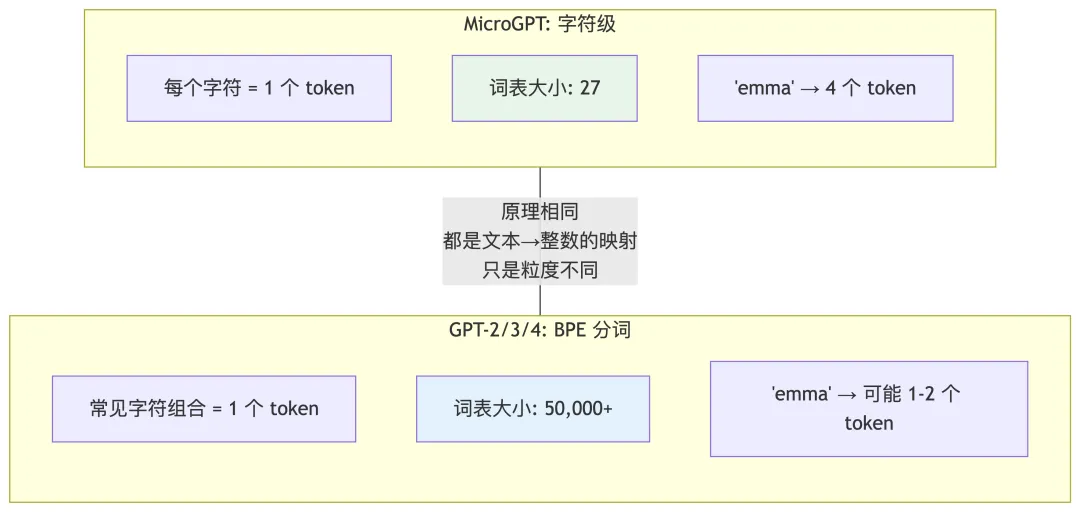
字符级分词是使用一个字符对应一个 token,如果使用一个字符串文本(即一个单词)对应一个 token 呢?那会导致词表巨大(英文单词总计有100w之多),且无法处理没见过的新词。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
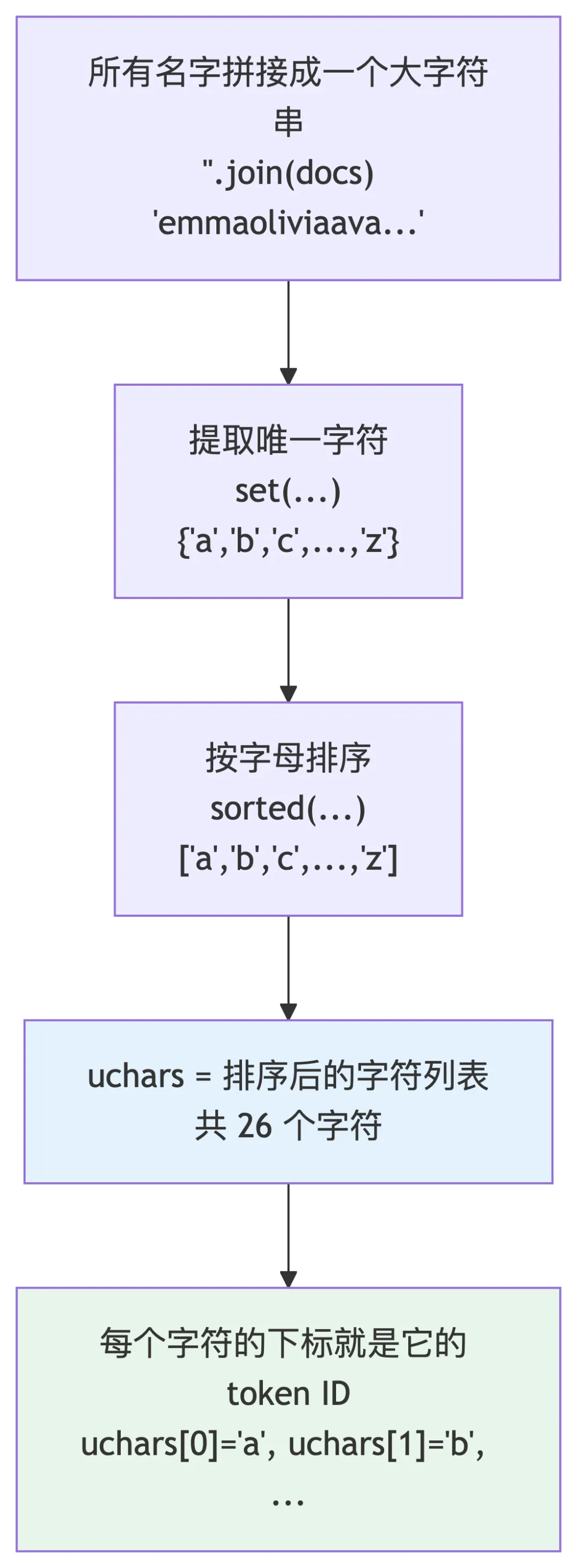
uchars = sorted(set(''.join(docs)))
BOS = len(uchars) vocab_size = len(uchars) + 1 

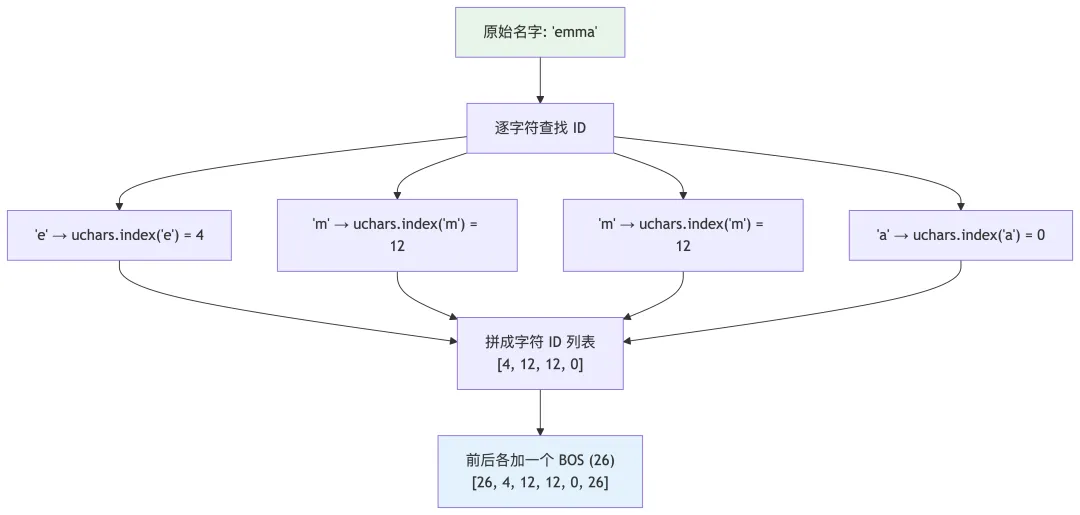

对应源码(第 157 行):
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]那么 token 在训练的时候是如何使用的呢?
模型的任务是 “Next token prediction”,即给定当前 token,预测下一个 token。

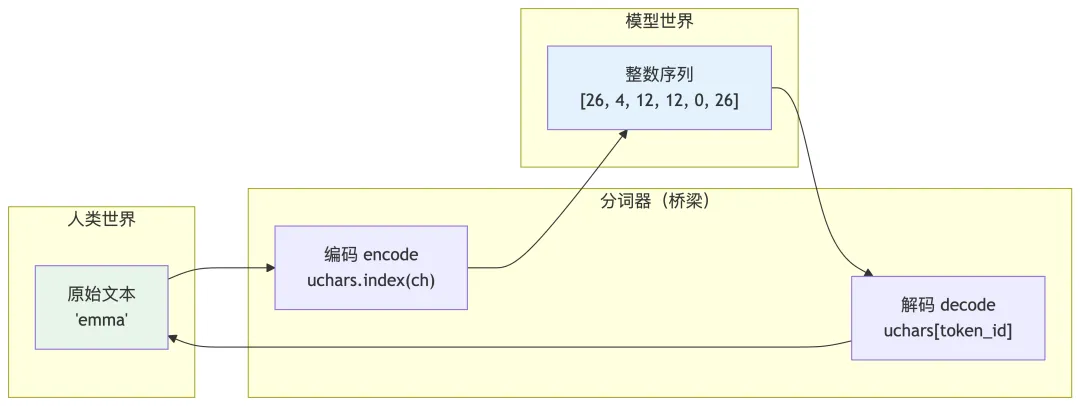
分词器(Tokenizer)本身非常简单——就是一个字符到整数的查找表。但正是这个简单的桥梁,让模型能够用纯数学运算来”理解”和”生成”文本。
本篇完。
下篇第三部分继续分析 MicroGPT的自动微分引擎逻辑,如果觉的有趣,欢迎讨论关注:)
