 夜雨聆风
夜雨聆风





让AI真正拥有长期记忆:PlugMem源码深度解析
你有没有想过,每次和 AI 聊天,它为什么总像失忆了一样,需要你一遍遍重复背景信息?明明上周你们深聊过你的工作习惯,今天它依然一片空白。这不是 AI 不够聪明,而是它没有真正意义上的长期记忆。
记忆,是 AI Agent 的最后一块拼图
2024 年以来,AI Agent(智能体)成为业界最热门的方向——让 AI 不只是”问答机器”,而是能自主完成任务的智能助手。工具调用、多步规划、环境感知,这些能力一一就位,但有一块拼图始终缺席:
跨会话的长期记忆。
现有的解决方案大多是这样的:把所有历史对话塞进一个向量数据库,用户问问题时检索相关段落,喂给 AI。听起来很合理,但实际使用中问题很明显——
-
原始对话噪声多,有效信息密度低 -
随着使用时间增长,知识不断堆积却从不演化 -
“上周你说过的话”和”上个月的错误认知”并存,AI 不知道该信哪个
最近我深读了一个研究级开源项目 PlugMem(TIMAN Group,University of Illinois),它给出了一个与众不同的答案。让我们从源码视角,看清楚这套系统是怎么想、怎么做的。
一、核心洞察:记忆不应该是”存档”,而应该是”提炼”
PlugMem 最根本的哲学与传统 RAG 截然不同:
不存储原始对话,而是提炼可复用的知识单元。
就像你读完一本书,真正留在脑海里的不是书的每一页,而是书中的”知识”、”经验”和”印象”。PlugMem 照着这个逻辑,把 Agent 的经历抽象成三种记忆类型:
情节记忆 Episodic —— "发生了什么"(原始轨迹,存磁盘按需读取)语义记忆 Semantic —— "我知道什么"(事实性知识 + 语义标签)过程记忆 Procedural —— "怎么做" (子目标 + 经验洞见)这三种分类不是随意设计的,而是对应了认知科学中人类记忆系统的分层结构。
二、Memory 类:如何把一次 Agent 会话”结构化”
一次会话的处理流程由
Memory类驱动,用法极简:# 初始化一次会话mem = Memory(goal="帮我订一家适合商务宴请的餐厅", observation=初始页面)# 每走一步,调用 appendmem.append(action="搜索'北京商务餐厅'", observation=搜索结果页面)mem.append(action="点击第一条结果", observation=餐厅详情页)# 会话结束,触发批量提炼mem.close()表面上只有三行,背后运转着一套精密的 LLM 流水线:
每一步
append都在做什么?输入:一个 (action, observation) 对 │ ├─ 推断子目标:这个动作背后的意图是什么? │ → LLM: "Agent 点击第一条结果,是为了查看餐厅详情" │ ├─ 评估奖励:这个动作对总目标有多大贡献? │ → LLM: "成功找到目标餐厅信息,贡献较大" │ ├─ 判断子目标是否切换: │ → 计算当前子目标与上一步的 Embedding 相似度 │ → 如果 < 0.75(切换了意图),把当前轨迹段存入 Episodic │ 开始积累新的轨迹段 │ └─ 更新状态摘要: → LLM 更新 Agent 的内部状态描述(类似工作记忆)关键设计:用 Embedding 相似度自动切割轨迹,而不是按固定步数分割。当 Agent 的意图发生偏转,就意味着”一件新的事情”开始了,这是更自然的情节分割方式。
close()时做了什么?对每个情节段落,并行做两件事:
提炼语义记忆:让 LLM 从每一步的 observation 中提取事实陈述,并为每条事实打上语义标签(tags) 提炼过程记忆:让 LLM 把整段轨迹总结成”目标”和”经验洞见”——下次遇到类似任务时可以直接复用
三、MemoryGraph:一张会思考、会演化的知识图谱
提炼出来的知识单元,被组织进一个精心设计的异构知识图谱:
TagNode ──────── SemanticNode ──────── EpisodicNode(标签节点) (事实节点) (情节节点) │ bro_semantic(兄弟事实) │SubgoalNode ───── ProceduralNode ──── EpisodicNode(子目标聚类) (经验节点) (情节溯源)这里每一条边都是有意义的关系:
-
Tag → Semantic:这个标签属于哪些事实 -
Semantic → Episodic:这个事实来自哪次原始经历(溯源) -
Semantic 之间的兄弟关系:同一次经历中提取的事实互为兄弟,有语境关联 -
SubgoalNode 聚类 ProceduralNode:相同类型的子目标,其所有经验都聚合在一起
写入图谱:insert() 时发生了什么?
以语义记忆的写入为例:
mg.insert(mem) # 将一次 Memory 对象的所有知识写入图谱标签的处理方式很有意思:系统不会直接用字符串精确匹配,而是用 Embedding 相似度(阈值 0.9)来判断两个 Tag 是否是”同一个”:
"user preference" 和 "user's preference"→ embedding 相似度 > 0.9→ 复用同一个 TagNode,不创建重复这避免了因文字表述差异导致的知识碎片化,是一个非常实用的工程细节。
四、检索时:三层 LLM 路由,拿到最对的记忆
当 Agent 需要从记忆中获取帮助,调用方式同样优雅:
answer = mg.retrieve_and_reason( goal="订餐厅", subgoal="选择符合预算的选项", state="已找到三家候选餐厅", observation="当前页面显示价格对比...")内部执行了一套三步路由策略:
Step 1:规划 —— 提炼检索意图
LLM 分析当前情境,生成:
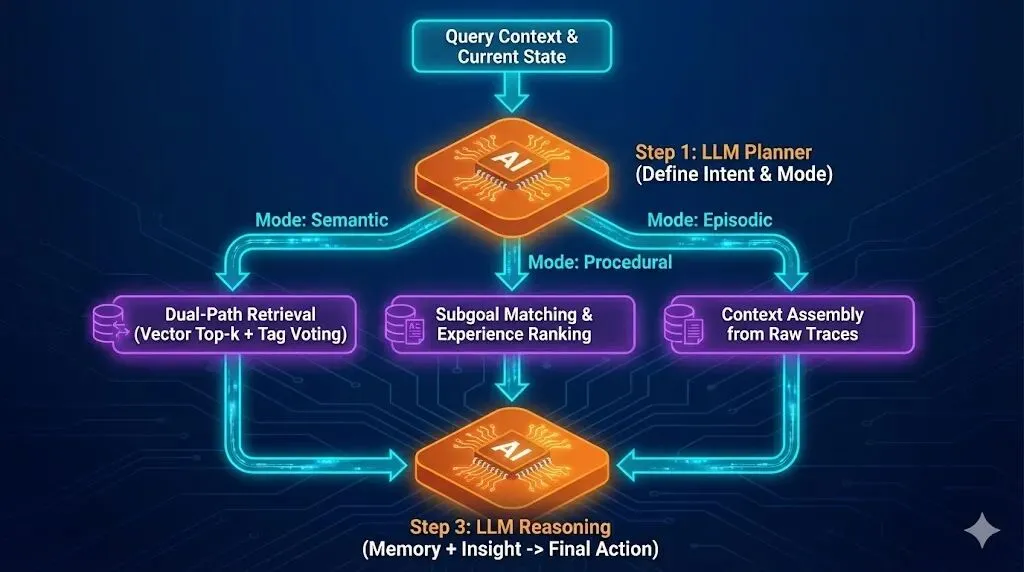
-
query_tags:[“商务宴请”, “北京”, “价格”, …] -
next_subgoal:”选择性价比最高的餐厅” -
mode:该用哪种记忆?
Step 2:按 mode 走不同通路
语义模式 → retrieve_semantic_nodes() 路A: 当前状态 embedding → 直接相似度 Top-5 路B: query_tags → TagNode → 投票语义节点 (精确命中 tag 权重 ×5,模糊命中权重 ×1) 合并两路 → 综合评分 → Top-k 事实过程模式 → retrieve_procedural_nodes() → next_subgoal → 匹配相似 SubgoalNode → 取该节点下所有经验,按历史收益排序情节模式 → 两路都跑 → 通过语义/过程节点反向找原始情节,组装上下文这种双路召回 + 投票聚合的机制,比纯向量检索鲁棒得多。Tag 路由擅长处理专有名词和精确实体,向量检索擅长处理语义泛化,两者互为补充。
Step 3:推理 —— 记忆 + 洞见 → 最终行动
检索到的记忆填入对应的 Prompt 模板,再次调用 LLM,生成最终的行动决策或答案。
五、最令人惊喜的设计:记忆会”自我更新”
这是 PlugMem 里我认为最具前瞻性的功能——
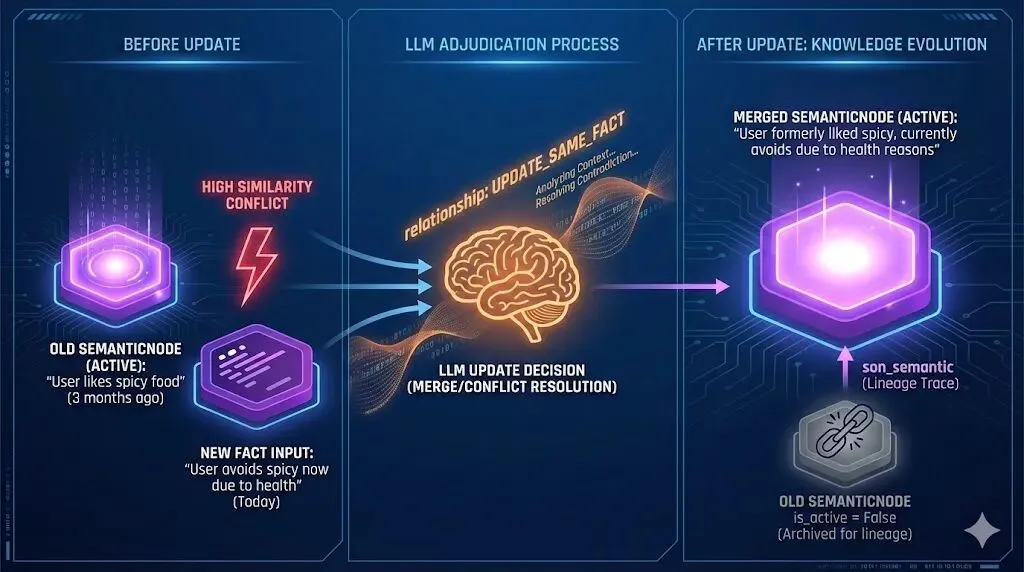
update_semantic_subgraph(),一套LLM 驱动的知识演化机制。mg.update_semantic_subgraph(merge_threshold=0.5)设想这样的场景:
旧事实(三个月前存入):”用户喜欢辣食”新事实(今天存入):”用户点了清淡的粤菜,说最近肠胃不好,不吃辣了”
两条对同一话题的事实,Embedding 相似度超过阈值,触发合并流程:
LLM 合并决策 → relationship: "UPDATE_SAME_FACT" merged_statement: "用户过去喜欢辣食,但近期因肠胃原因改为清淡饮食" deactivate_earlier: true ← 旧事实标记为非活跃 deactivate_later: false ← 新事实保留执行结果:✅ 生成合并后的新 SemanticNode✅ 旧节点 is_active = False(软删除,不物理移除)✅ son_semantic 字段记录合并来源(可溯源、可审计)这里有几个精妙之处:
不是硬删除:旧节点物理上还在,只是被标记为非活跃。历史完整保留,合并链可回溯 LLM 做语义判断:不是简单地”相似度超过阈值就覆盖”,而是让 LLM 理解两条信息的关系是”更新”还是”互补”还是”弱相关不宜合并” Credibility 机制:节点有可信度分数,可以随时间衰减,实现对旧知识的渐进遗忘 这让知识图谱从”只增不减的档案馆”变成了”动态更新的活知识库”。
六、可插拔策略:这套系统如何做到任务无关
PlugMem 被设计为”任务无关”(task-agnostic),核心是一套**策略模式(Strategy Pattern)**的价值函数体系:
class ValueBase(ABC): def evaluate(self, Importance, Relevance, Recency, Return, Credibility) -> float: return ( self.compute_importance(Importance) + self.compute_relevance(Relevance) + self.compute_recency(Recency) + self.compute_return(Return) ) # 子类负责实现每个维度的具体计算逻辑 @abstractmethod def compute_relevance(self, ...) -> float: ... @abstractmethod def compute_recency(self, ...) -> float: ... ...五个维度意味着五个可扩展的方向:
-
Relevance:当前版本的核心维度,用 Embedding 相似度衡量 -
Recency:时间衰减,越近的记忆权重越高 -
Importance:被引用次数越多,说明越重要 -
Return:强化学习视角,历史上带来收益的经验优先 -
Credibility:知识可信度,可随时间或新证据更新
不同的应用场景,注入不同的 ValueBase 子类实例,完全不需要修改检索逻辑。这正是 PlugMem “即插即用”定位的工程基础。
七、在三个主流 Benchmark 上的验证
PlugMem 在三个完全不同的任务场景上进行了评测,这恰恰证明了其设计的通用性:
|
|
|
|
|---|---|---|
| WebArena |
|
|
| LongMemEval |
|
|
| HotpotQA |
|
|
同一套 MemoryGraph,三套不同的 insert_xx_ver() 和 build_mem_from_disk_xx_ver() 适配方法,核心图结构完全复用。
总结:这套设计的真正价值在哪里
回到最开始的问题——为什么 AI 总像失忆了?
PlugMem 给出的不只是一个技术答案,更是一种认知范式的迁移:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
六行代码接入,让 Agent 拥有会学习、会演化、会遗忘旧错误的长期记忆——这正是 AI Agent 从”工具”走向”助手”所需要的关键一跃。
项目地址:TIMAN-group/PlugMem本文基于源码阅读整理,所有代码细节均来自项目
src/目录的实际实现。
如果你对 AI Agent 的记忆系统设计感兴趣,欢迎在评论区交流。
