 夜雨聆风
夜雨聆风





Python实战:手把手带你开发一个“PDF表格提取合并神器”
前言
在日常办公中,我们经常遇到这样的需求:把PDF文件里的表格数据提取出来,保存到Excel中。如果只是几行数据,复制粘贴还能忍受,但如果是几十页的报表,手动复制简直是噩梦。
其实也有很多在线的网页或者工具可以提取pdf中的表格,但是这种在线的工具我用起来总觉得不放心。
所以最近我就用 Python 写了一个小工具,不仅能自动提取 PDF 表格,还能指定页码范围,将多页的表格自动合并到一个 Excel 文件中。
为了方便非技术人员使用,我还给它加上了图形界面(GUI),并打包成了 EXE 可执行文件。该工具纯Python编写,不需要网络即可运行,所以在断网和内网环境中均可以使用,绝对安全。
今天就来分享一下这个工具的开发思路,以及如何将几百兆的程序优化到十几兆。
软件介绍
打开软件后,界面如下: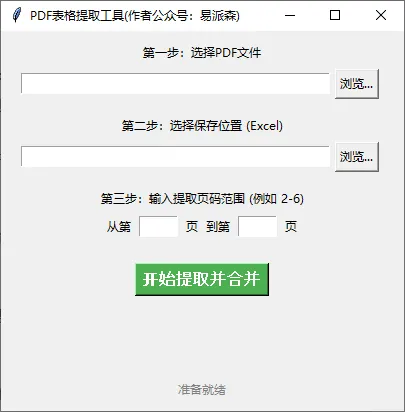
软件使用也是非常傻瓜,根据提示选择pdf文件和保存位置,然后再输入你需要提取的excel所在页数即可,如果只有一页,那就填两个相同的数字,最后点击开始按钮就行咯。
软件获取方式: 关注gzh:“易派森”,输入关键词“pdf提取excel”,获取exe工具及源码下载链接。
接下来是代码介绍
一、 需求分析
我们的目标是将一段简单的 Python 脚本改造成一个成熟的桌面工具,具体需求如下:
-
图形界面:不用敲命令行,通过按钮选择文件。 -
输入/输出控制:选择输入的 PDF 和输出的 Excel 保存路径。 -
页码控制:PDF 可能有封面和目录,我们需要指定提取第几页到第几页的表格。 -
轻量化:打包后的软件体积要小,启动要快。
二、 技术选型
-
GUI 框架: tkinter(Python 内置,无需安装,轻量级)。 -
PDF 提取: pdfplumber(提取表格数据的神器)。 -
Excel 写入: openpyxl(代替庞大的 Pandas,大幅减小软件体积)。 -
打包工具: PyInstaller。
三、 从 Pandas 到 OpenPyxl:一次关键的优化
最初,我使用 pandas 来处理表格数据。虽然 pandas 功能强大,但在打包成 EXE 时,它会把几百兆的依赖库都打进去,导致一个简单的工具体积高达 **80MB+**,且启动缓慢。
考虑到我们的需求仅仅是“合并数据并写入 Excel”,并不需要复杂的统计分析功能。因此,我决定移除 pandas,改用 Python 原生列表 (List) 配合 openpyxl 库。
优化结果:打包后的 EXE 文件从 80MB 降到了约 15MB,启动速度实现秒开!
四、 核心代码实现逻辑
为了实现上述功能,我们需要解决三个核心编程问题。以下是关键代码片段的讲解:
1. 处理页码索引差异
用户习惯从第 1 页开始计数,但编程库 pdfplumber 的页面索引是从 0 开始的。因此,在循环遍历页面时,需要对用户输入的页码进行转换。
# start_p 是用户输入的起始页(如2),end_p 是结束页(如6)
# range 函数左闭右开,且索引从0开始,所以要 start_p - 1
for i in range(start_p - 1, end_p):
page = pdf.pages[i]
tables = page.extract_tables()
# 接下来处理 tables...
2. 智能合并表格(去除重复表头)
当我们将多页的表格合并时,通常只需要保留第一页的表头,后续页面的表头需要剔除,否则 Excel 中会出现多行重复的标题。
all_rows = [] # 用于存储所有行数据
header = None# 用于标记是否已经提取过表头
for table in tables:
ifnot table: continue
# 逻辑:如果是提取的第一个表格,我们需要表头
if header isNone:
header = table[0] # 取第一行作为表头
all_rows.extend(table[1:]) # 剩下的作为内容
else:
# 后续表格,直接跳过第一行表头,只取内容
if len(table) > 1:
all_rows.extend(table[1:])
3. 轻量化写入 Excel
放弃 Pandas 后,我们使用 openpyxl 直接操作单元格写入数据,这使得程序更加轻巧。
import openpyxl
# 创建一个新的工作簿
wb = openpyxl.Workbook()
ws = wb.active
# 1. 写入表头
if header:
ws.append(header)
# 2. 循环写入所有内容行
for row in all_rows:
ws.append(row)
# 3. 保存文件
wb.save(output_file_path)
通过以上三个步骤,我们将原本复杂的逻辑拆解成了清晰的数据流:修正页码 -> 提取并清洗数据 -> 写入文件。配合 tkinter 的界面代码(主要是 Entry 输入框和 Button 按钮的布局),就构成了一个完整的工具。
五、 打包成 EXE 可执行文件
为了让同事或者朋友也能使用这个工具,我们需要把它打包成 .exe 文件。
-
安装打包工具:
pip install pyinstaller -
执行打包命令: 在代码所在目录下打开终端(CMD),运行:
pyinstaller -F -w pdf_tool.py参数说明:
-
-F:打包成单独的一个 exe 文件,方便发送。 -
-w:运行程序时不显示黑色的命令行窗口。 -
获取成品: 运行完成后,打开生成的
dist文件夹,里面的pdf_tool.exe就是你的最终成果!
六、 总结
通过这次实战,我们不仅解决了一个实际的办公自动化问题,还学习了:
-
使用 pdfplumber精准提取 PDF 表格。 -
使用 tkinter开发桌面图形界面。 -
优化思维:用轻量级的 openpyxl替代pandas从而减小软件体积。 -
使用 PyInstaller进行软件分发。
如果你也有类似的重复性工作,不妨试试用 Python 来解放双手!
