 夜雨聆风
夜雨聆风





MinerU-全能PDF文档数据提取的开源利器
MinerU 是一款面向开发者与科研用户的 PDF 结构化解析工具,专注于将 PDF 文档高质量地转换为机器可读格式(如 Markdown、JSON 等),以便于后续的检索、分析与二次加工。MinerU 起源于「书生·浦语」大模型预训练过程,核心目标是解决科技文献中复杂版式、符号与公式的高质量解析问题,在大模型时代为科研与工程应用提供可靠的数据基础。
MinerU是什么?
MinerU是一款强大的开源PDF数据提取工具,由OpenDataLab开发。它能够智能地将PDF文档转换为结构化的数据格式,支持文本、图片、表格和数学公式的精确提取。无论是处理学术论文、技术文档还是商业报告,MinerU都能帮你轻松应对。
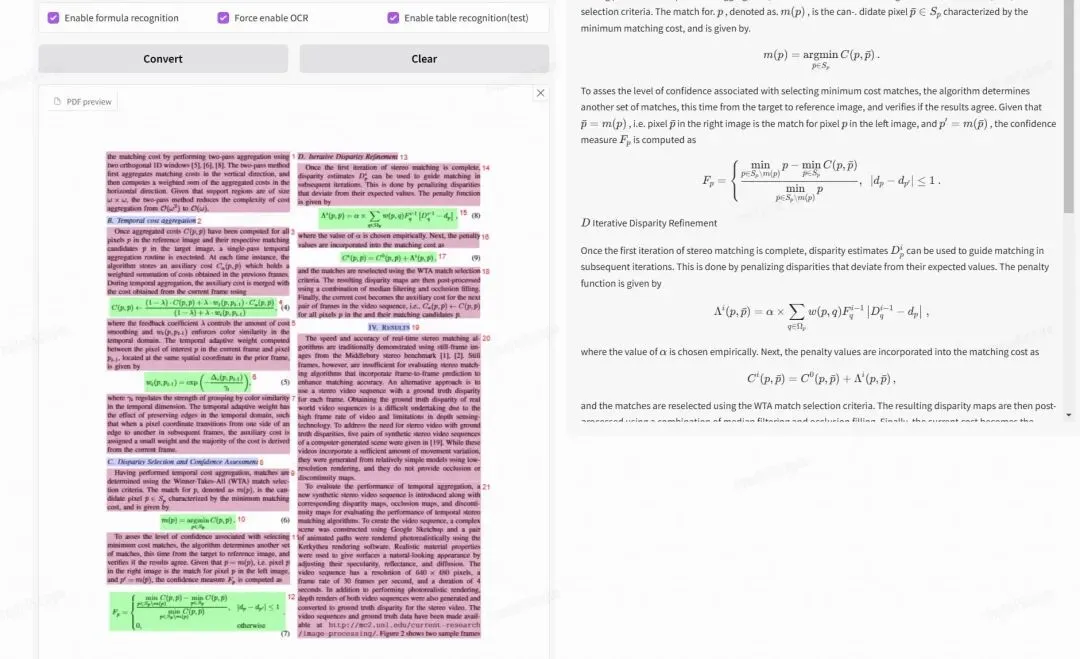
随着 2.7.0 版本的发布,MinerU 在解析架构和易用性方面进行了重要升级,引入了全新的 hybrid 后端,融合了 pipeline 与 VLM 两类后端的优势,在保证解析精度的同时显著提升了扩展性与稳定性。该后端在文本型 PDF 场景下可直接抽取原生文本,天然支持多语言并有效降低解析幻觉;在扫描版 PDF 场景下,则支持多达 109 种语言的 OCR 识别,并提供独立的行内公式识别开关,以适配不同视觉与结构需求。
复杂元素无损提取


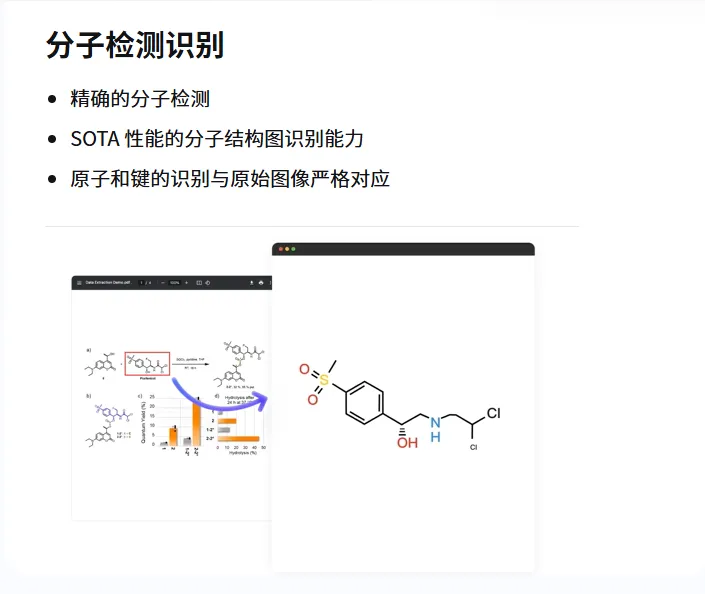

Part.1
功能特性

-
智能清理 – 自动移除页眉页脚等干扰内容
-
结构保持 – 完整保留原文档的层级结构
-
多模态支持 – 精确提取图片、表格及说明文字
-
公式转换 – 自动识别数学公式并转为LaTeX
-
多语言OCR – 支持84种语言的文字识别
-
跨平台兼容 – 支持所有主流操作系统

Part.2
应用场景

MinerU 的出现,为众多领域打开了新的可能性:
-
高质量 LLM 语料构建:将海量 PDF 文档(如书籍、论文、财报)批量转换为干净、结构化的 Markdown,是构建垂直领域大模型不可或缺的预处理步骤。MinerU 产出的格式几乎可以直接喂给 LLM 进行训练。
-
智能知识库与 RAG 系统:在企业知识管理场景中,MinerU 可以自动解析上传的 PDF 文档,提取关键信息并建立索引,使得基于 RAG 的问答系统能够精准地回答用户关于文档内容的问题。
-
自动化文档处理(IDP):在金融、法律等行业,MinerU 可以作为 IDP 流程的第一环,自动提取合同、发票、报告中的关键字段和表格数据,大幅提升工作效率。
-
无障碍阅读与教育:为视障人士提供结构化的文本,或帮助学生快速从教材 PDF 中提取重点笔记。
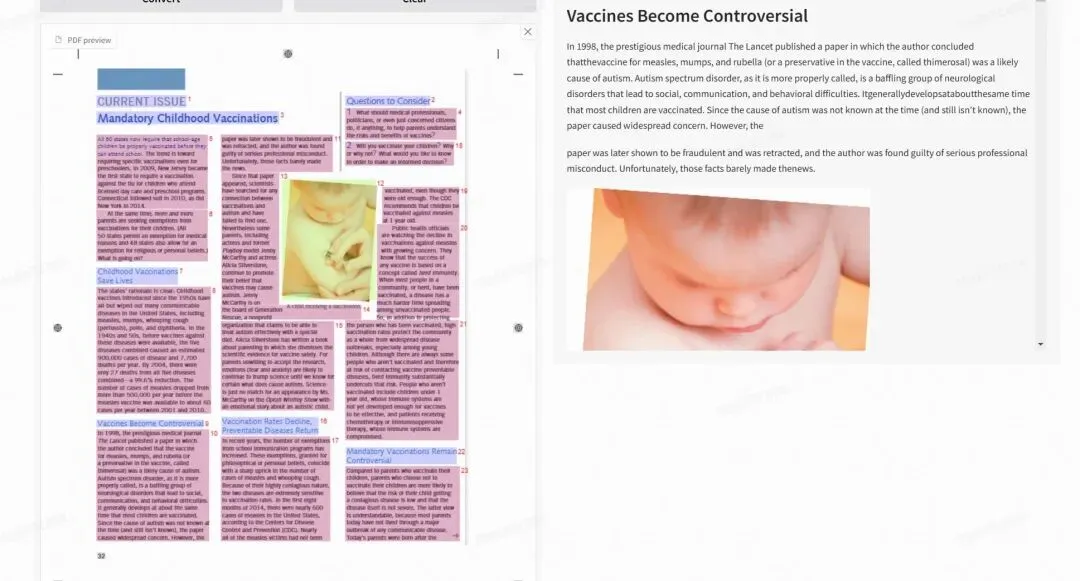
Part.3
支持语言

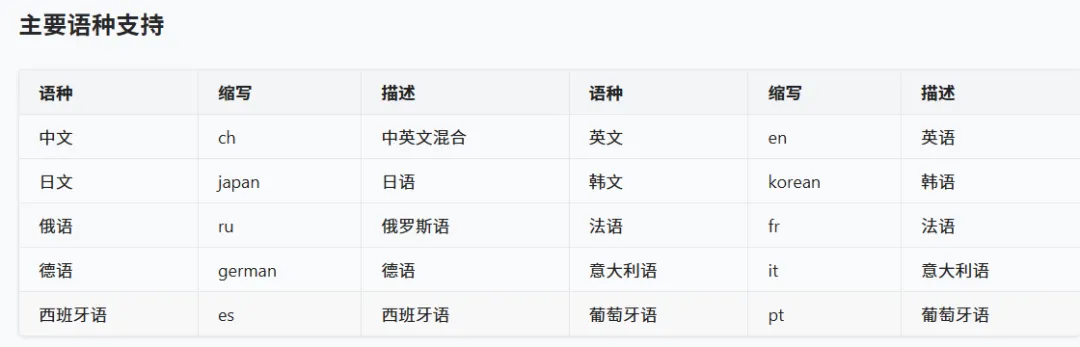
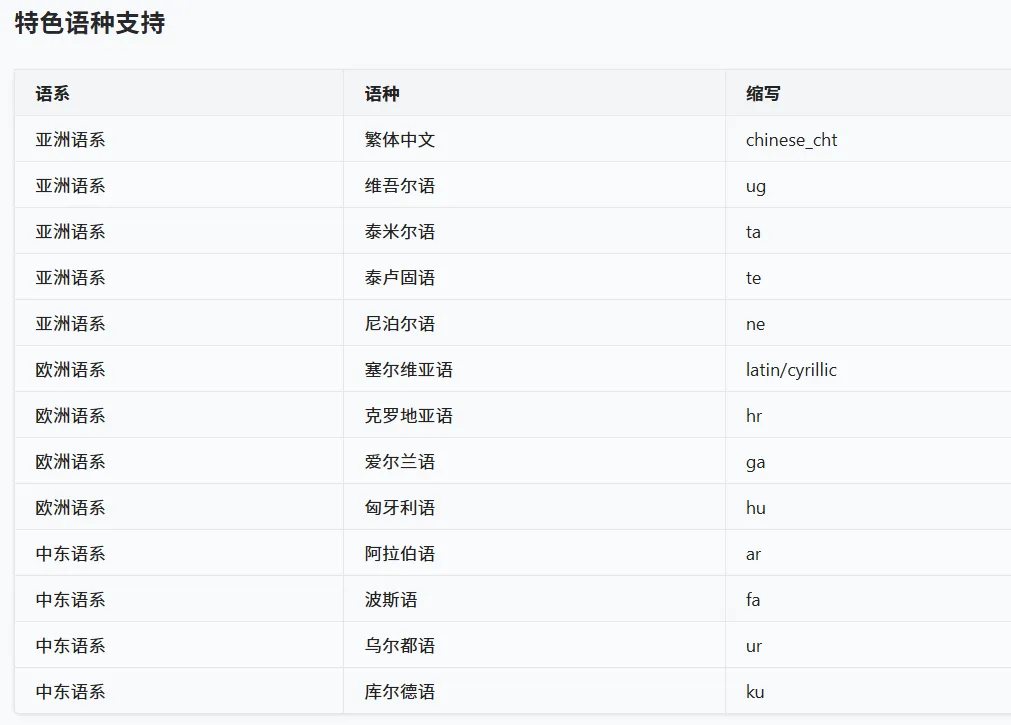
Part.4
快速开始

在线体验
不想安装?直接访问以下平台即可体验:
https://mineru.net/OpenSourceTools/Extractor
本地安装
基础环境配置
基础Python环境配置
# 创建虚拟环境conda create -n MinerU python=3.10conda activate MinerU# 安装核心包pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com
基本使用方法
# 处理单个文件magic-pdf -p paper.pdf -o output -m auto# 批量处理文件夹magic-pdf -p papers_dir -o output -m auto
表格识别增强
最新版本集成了RapidTable表格识别引擎:
-
识别速度提升10倍
-
更高的识别准确率
-
更低的资源占用
Part.5
实战应用场景

实战应用场景
1. 学术研究
-
批量提取研究论文数据
-
构建文献知识库
-
提取实验数据和图表
2. 数据分析
-
提取财务报表数据
-
处理技术文档
-
分析研究报告
3. 内容管理
-
文档数字化转换
-
建立搜索系统
-
知识库构建
4. 开发集成
-
RAG系统开发
-
文档处理服务
-
内容分析平台
-
性能优化建议
常见问题解决
1. 安装问题
Q: 安装时报错”未找到预编译包”? A: 检查Python版本是否为3.10,并确保pip源配置正确。
2. 识别问题
Q: 复杂公式识别不准确? A: 尝试使用高精度模式,并确保PDF质量良好。
3. 性能问题
Q: 处理大文件很慢? A: 启用GPU加速,并适当调整batch size。
更多历史热门文章
工业时序数据底座的终极答案?Apache IoTDB 如何重塑智能制造数据栈
告别复杂与延迟:Apache Doris 实践指南,构建下一代高性能实时分析平台
FastAPI + Vue3 的完美搭档:开源中后台框架 RuoYi-Vue3-FastAPI 深度解析
10.2K Star!拖拽即开发,这款开源低代码平台堪称接单与企业提效神器!
